 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency Bias and OOD Generalization in Neural Operators under a Variable-Coefficient Wave Equation
May 13, 2026Neural operators learn to map initial conditions to the terminal solution of partial differential equations (PDEs), providing a surrogate for the full operator mapping. This enables rapid prediction across different input configurations. While recent neural operator architectures have demonstrated strong performance on diverse PDE tasks, their behavior under structured distribution shifts remains insufficiently understood. To investigate this, we study operator learning in a wave propagation setting governed by a one-dimensional variable-coefficient wave equation, using two representative architectures, the Fourier Neural Operator (FNO) and the Deep Operator Network (DeepONet). To examine their generalization under distribution shifts, we consider structured out-of-distribution (OOD) settings that independently vary input frequency and coefficient smoothness. The results show that under smoothness shifts, both models maintain stable performance, with FNO achieving lower error. In contrast, under frequency shifts, FNO exhibits a sharp increase in error under unseen high-frequency inputs, whereas DeepONet shows milder degradation despite higher overall error. Our analysis reveals that these differences arise from how each architecture represents and responds to variations in frequency structure. Together, these findings highlight a fundamental gap between strong in-distribution performance and generalization under distribution shifts in operator learning, underscoring the role of architectural representation bias in developing more reliable neural operators for physics-based PDE simulations beyond the training distribution.
ADD for Multi-Bit Image Watermarking
Apr 13, 2026As generative models enable rapid creation of high-fidelity images, societal concerns about misinformation and authenticity have intensified. A promising remedy is multi-bit image watermarking, which embeds a multi-bit message into an image so that a verifier can later detect whether the image is generated by someone and further identify the source by decoding the embedded message. Existing approaches often fall short in capacity, resilience to common image distortions, and theoretical justification. To address these limitations, we propose ADD (Add, Dot, Decode), a multi-bit image watermarking method with two stages: learning a watermark to be linearly combined with the multi-bit message and added to the image, and decoding through inner products between the watermarked image and the learned watermark. On the standard MS-COCO benchmark, we demonstrate that for the challenging task of 48-bit watermarking, ADD achieves 100\% decoding accuracy, with performance dropping by at most 2\% under a wide range of image distortions, substantially smaller than the 14\% average drop of state-of-the-art methods. In addition, ADD achieves substantial computational gains, with 2-fold faster embedding and 7.4-fold faster decoding than the fastest existing method. We further provide a theoretical analysis explaining why the learned watermark and the corresponding decoding rule are effective.
AgentDS Technical Report: Benchmarking the Future of Human-AI Collaboration in Domain-Specific Data Science
Mar 19, 2026Data science plays a critical role in transforming complex data into actionable insights across numerous domains. Recent developments in large language models (LLMs) and artificial intelligence (AI) agents have significantly automated data science workflow. However, it remains unclear to what extent AI agents can match the performance of human experts on domain-specific data science tasks, and in which aspects human expertise continues to provide advantages. We introduce AgentDS, a benchmark and competition designed to evaluate both AI agents and human-AI collaboration performance in domain-specific data science. AgentDS consists of 17 challenges across six industries: commerce, food production, healthcare, insurance, manufacturing, and retail banking. We conducted an open competition involving 29 teams and 80 participants, enabling systematic comparison between human-AI collaborative approaches and AI-only baselines. Our results show that current AI agents struggle with domain-specific reasoning. AI-only baselines perform near or below the median of competition participants, while the strongest solutions arise from human-AI collaboration. These findings challenge the narrative of complete automation by AI and underscore the enduring importance of human expertise in data science, while illuminating directions for the next generation of AI. Visit the AgentDS website here: https://agentds.org/ and open source datasets here: https://huggingface.co/datasets/lainmn/AgentDS .
Can Agentic AI Match the Performance of Human Data Scientists?
Dec 24, 2025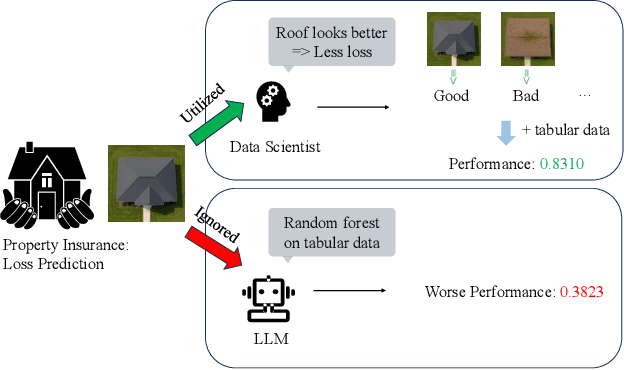

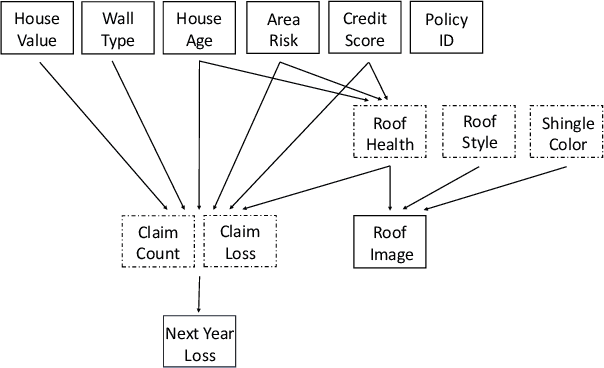

Data science plays a critical role in transforming complex data into actionable insights across numerous domains. Recent developments in large language models (LLMs) have significantly automated data science workflows, but a fundamental question persists: Can these agentic AI systems truly match the performance of human data scientists who routinely leverage domain-specific knowledge? We explore this question by designing a prediction task where a crucial latent variable is hidden in relevant image data instead of tabular features. As a result, agentic AI that generates generic codes for modeling tabular data cannot perform well, while human experts could identify the important hidden variable using domain knowledge. We demonstrate this idea with a synthetic dataset for property insurance. Our experiments show that agentic AI that relies on generic analytics workflow falls short of methods that use domain-specific insights. This highlights a key limitation of the current agentic AI for data science and underscores the need for future research to develop agentic AI systems that can better recognize and incorporate domain knowledge.
An Outlook on the Opportunities and Challenges of Multi-Agent AI Systems
May 23, 2025Multi-agent AI systems (MAS) offer a promising framework for distributed intelligence, enabling collaborative reasoning, planning, and decision-making across autonomous agents. This paper provides a systematic outlook on the current opportunities and challenges of MAS, drawing insights from recent advances in large language models (LLMs), federated optimization, and human-AI interaction. We formalize key concepts including agent topology, coordination protocols, and shared objectives, and identify major risks such as dependency, misalignment, and vulnerabilities arising from training data overlap. Through a biologically inspired simulation and comprehensive theoretical framing, we highlight critical pathways for developing robust, scalable, and secure MAS in real-world settings.
Ice Cream Doesn't Cause Drowning: Benchmarking LLMs Against Statistical Pitfalls in Causal Inference
May 19, 2025Reliable causal inference is essential for making decisions in high-stakes areas like medicine, economics, and public policy. However, it remains unclear whether large language models (LLMs) can handle rigorous and trustworthy statistical causal inference. Current benchmarks usually involve simplified tasks. For example, these tasks might only ask LLMs to identify semantic causal relationships or draw conclusions directly from raw data. As a result, models may overlook important statistical pitfalls, such as Simpson's paradox or selection bias. This oversight limits the applicability of LLMs in the real world. To address these limitations, we propose CausalPitfalls, a comprehensive benchmark designed to rigorously evaluate the capability of LLMs in overcoming common causal inference pitfalls. Our benchmark features structured challenges across multiple difficulty levels, each paired with grading rubrics. This approach allows us to quantitatively measure both causal reasoning capabilities and the reliability of LLMs' responses. We evaluate models using two protocols: (1) direct prompting, which assesses intrinsic causal reasoning, and (2) code-assisted prompting, where models generate executable code for explicit statistical analysis. Additionally, we validate the effectiveness of this judge by comparing its scoring with assessments from human experts. Our results reveal significant limitations in current LLMs when performing statistical causal inference. The CausalPitfalls benchmark provides essential guidance and quantitative metrics to advance the development of trustworthy causal reasoning systems.