 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Coordinated Text Streams through Burst Information Network Construction and Decipherment
Sep 27, 2016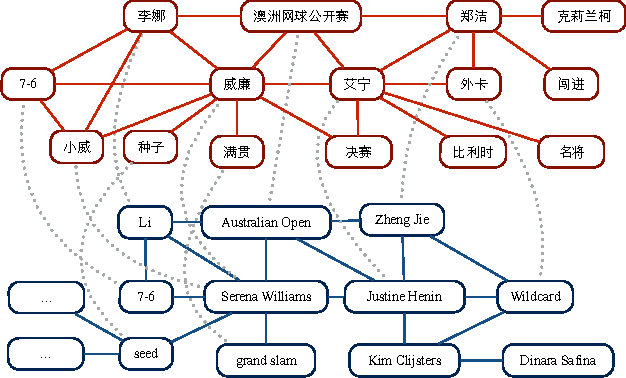

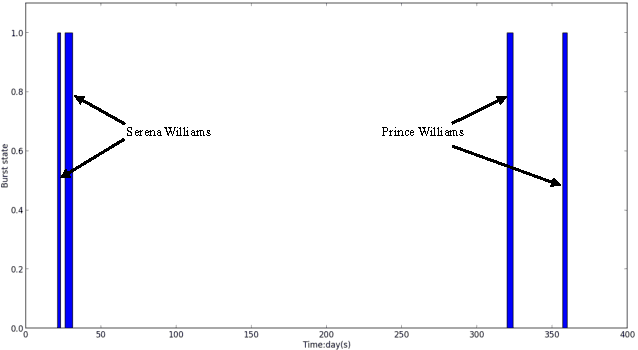
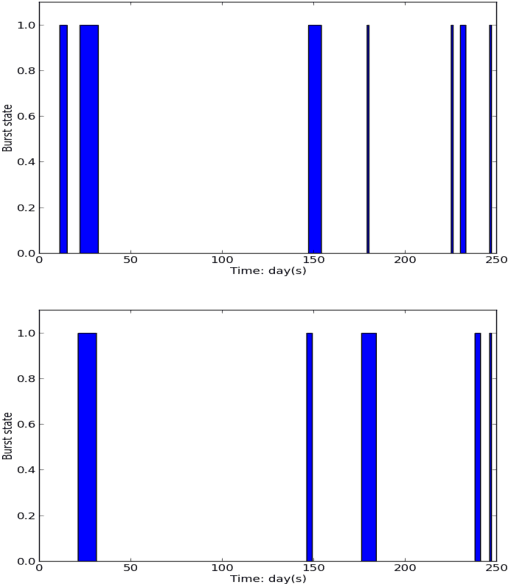
Aligning coordinated text streams from multiple sources and multiple languages has opened many new research venues on cross-lingual knowledge discovery. In this paper we aim to advance state-of-the-art by: (1). extending coarse-grained topic-level knowledge mining to fine-grained information units such as entities and events; (2). following a novel Data-to-Network-to-Knowledge (D2N2K) paradigm to construct and utilize network structures to capture and propagate reliable evidence. We introduce a novel Burst Information Network (BINet) representation that can display the most important information and illustrate the connections among bursty entities, events and keywords in the corpus. We propose an effective approach to construct and decipher BINets, incorporating novel criteria based on multi-dimensional clues from pronunciation, translation, burst, neighbor and graph topological structure. The experimental results on Chinese and English coordinated text streams show that our approach can accurately decipher the nodes with high confidence in the BINets and that the algorithm can be efficiently run in parallel, which makes it possible to apply it to huge amounts of streaming data for never-ending language and information decipherment.
Response Selection with Topic Clues for Retrieval-based Chatbots
Sep 22, 2016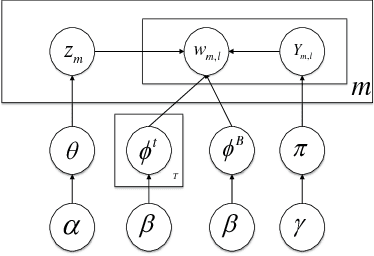
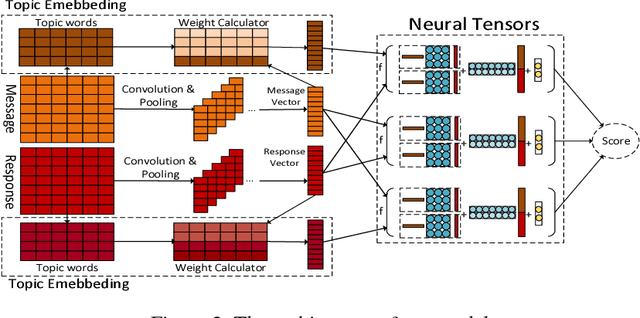
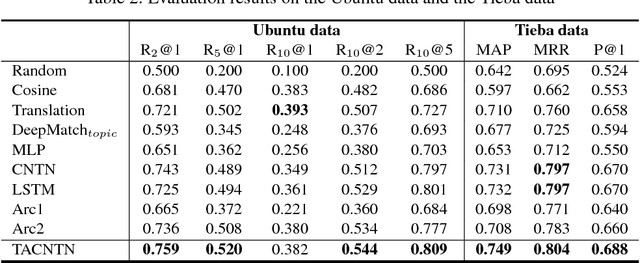
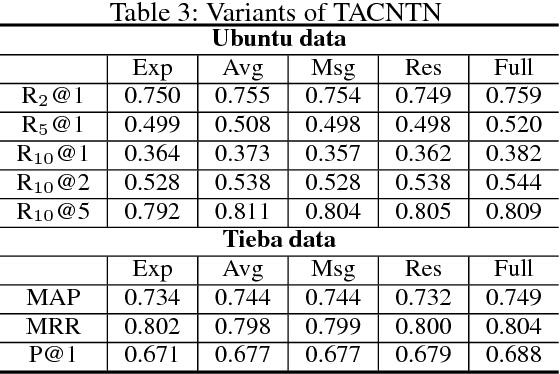
We consider incorporating topic information into message-response matching to boost responses with rich content in retrieval-based chatbots. To this end, we propose a topic-aware convolutional neural tensor network (TACNTN). In TACNTN, matching between a message and a response is not only conducted between a message vector and a response vector generated by convolutional neural networks, but also leverages extra topic information encoded in two topic vectors. The two topic vectors are linear combinations of topic words of the message and the response respectively, where the topic words are obtained from a pre-trained LDA model and their weights are determined by themselves as well as the message vector and the response vector. The message vector, the response vector, and the two topic vectors are fed to neural tensors to calculate a matching score. Empirical study on a public data set and a human annotated data set shows that TACNTN can significantly outperform state-of-the-art methods for message-response matching.
Topic Aware Neural Response Generation
Sep 19, 2016
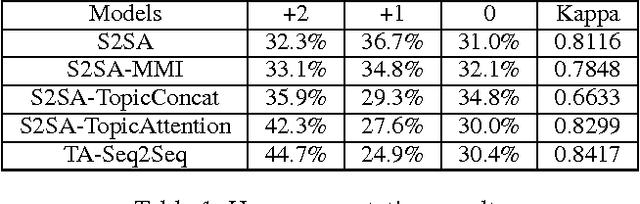
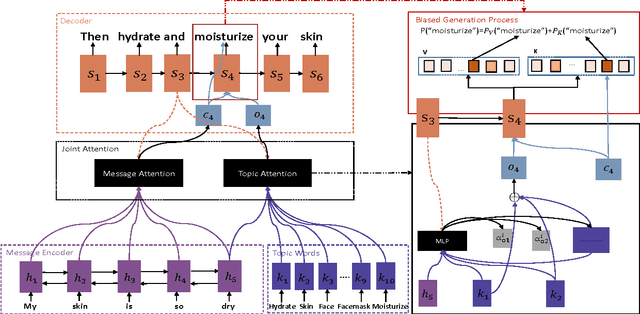
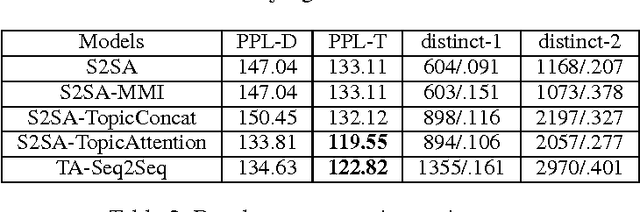
We consider incorporating topic information into the sequence-to-sequence framework to generate informative and interesting responses for chatbots. To this end, we propose a topic aware sequence-to-sequence (TA-Seq2Seq) model. The model utilizes topics to simulate prior knowledge of human that guides them to form informative and interesting responses in conversation, and leverages the topic information in generation by a joint attention mechanism and a biased generation probability. The joint attention mechanism summarizes the hidden vectors of an input message as context vectors by message attention, synthesizes topic vectors by topic attention from the topic words of the message obtained from a pre-trained LDA model, and let these vectors jointly affect the generation of words in decoding. To increase the possibility of topic words appearing in responses, the model modifies the generation probability of topic words by adding an extra probability item to bias the overall distribution. Empirical study on both automatic evaluation metrics and human annotations shows that TA-Seq2Seq can generate more informative and interesting responses, and significantly outperform the-state-of-the-art response generation models.
Unsupervised Word and Dependency Path Embeddings for Aspect Term Extraction
May 25, 2016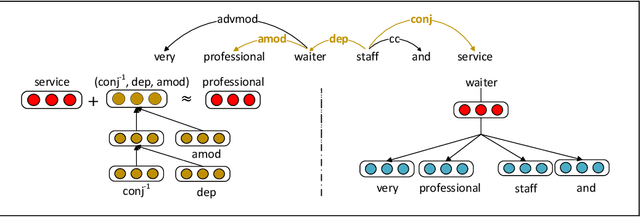
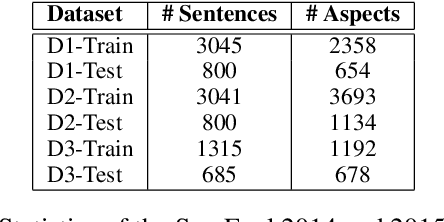

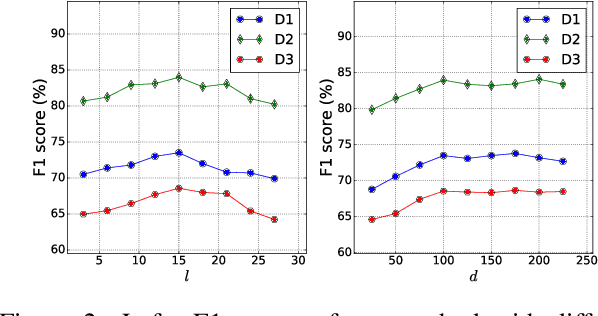
In this paper, we develop a novel approach to aspect term extraction based on unsupervised learning of distributed representations of words and dependency paths. The basic idea is to connect two words (w1 and w2) with the dependency path (r) between them in the embedding space. Specifically, our method optimizes the objective w1 + r = w2 in the low-dimensional space, where the multi-hop dependency paths are treated as a sequence of grammatical relations and modeled by a recurrent neural network. Then, we design the embedding features that consider linear context and dependency context information, for the conditional random field (CRF) based aspect term extraction. Experimental results on the SemEval datasets show that, (1) with only embedding features, we can achieve state-of-the-art results; (2) our embedding method which incorporates the syntactic information among words yields better performance than other representative ones in aspect term extraction.
Implicit Distortion and Fertility Models for Attention-based Encoder-Decoder NMT Model
Jan 22, 2016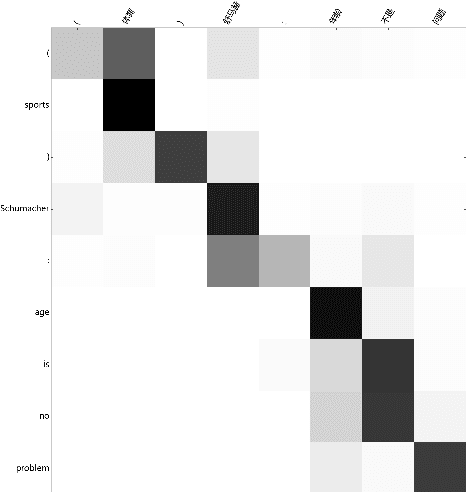
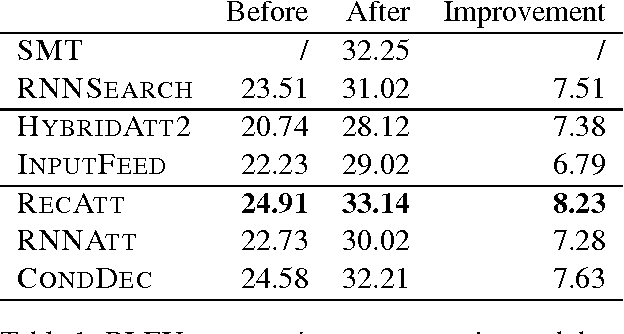
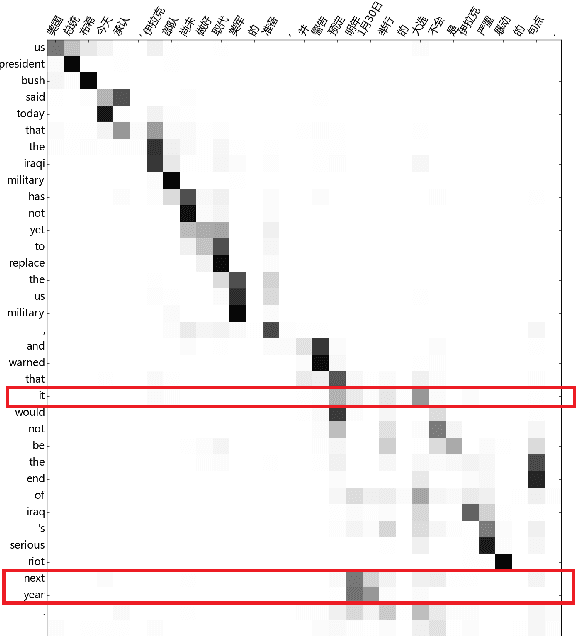

Neural machine translation has shown very promising results lately. Most NMT models follow the encoder-decoder framework. To make encoder-decoder models more flexible, attention mechanism was introduced to machine translation and also other tasks like speech recognition and image captioning. We observe that the quality of translation by attention-based encoder-decoder can be significantly damaged when the alignment is incorrect. We attribute these problems to the lack of distortion and fertility models. Aiming to resolve these problems, we propose new variations of attention-based encoder-decoder and compare them with other models on machine translation. Our proposed method achieved an improvement of 2 BLEU points over the original attention-based encoder-decoder.
Jointly Modeling Topics and Intents with Global Order Structure
Dec 07, 2015
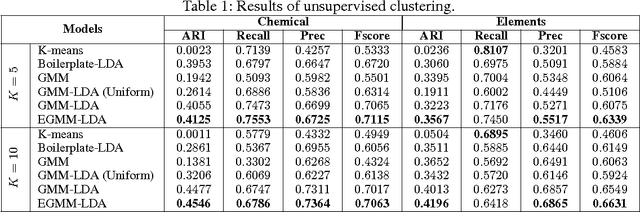
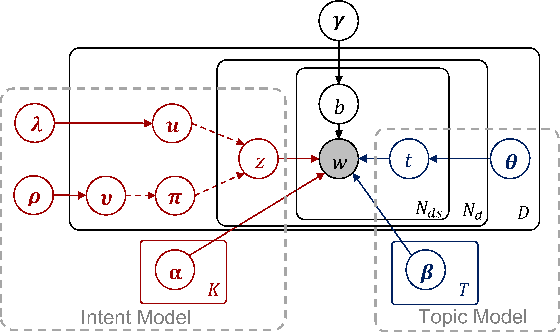

Modeling document structure is of great importance for discourse analysis and related applications. The goal of this research is to capture the document intent structure by modeling documents as a mixture of topic words and rhetorical words. While the topics are relatively unchanged through one document, the rhetorical functions of sentences usually change following certain orders in discourse. We propose GMM-LDA, a topic modeling based Bayesian unsupervised model, to analyze the document intent structure cooperated with order information. Our model is flexible that has the ability to combine the annotations and do supervised learning. Additionally, entropic regularization can be introduced to model the significant divergence between topics and intents. We perform experiments in both unsupervised and supervised settings, results show the superiority of our model over several state-of-the-art baselines.
TGSum: Build Tweet Guided Multi-Document Summarization Dataset
Nov 26, 2015
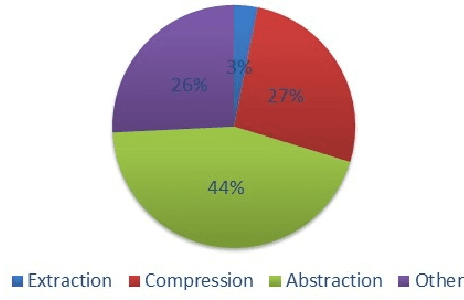
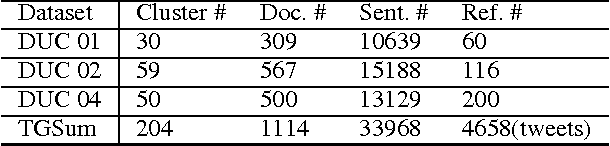

The development of summarization research has been significantly hampered by the costly acquisition of reference summaries. This paper proposes an effective way to automatically collect large scales of news-related multi-document summaries with reference to social media's reactions. We utilize two types of social labels in tweets, i.e., hashtags and hyper-links. Hashtags are used to cluster documents into different topic sets. Also, a tweet with a hyper-link often highlights certain key points of the corresponding document. We synthesize a linked document cluster to form a reference summary which can cover most key points. To this aim, we adopt the ROUGE metrics to measure the coverage ratio, and develop an Integer Linear Programming solution to discover the sentence set reaching the upper bound of ROUGE. Since we allow summary sentences to be selected from both documents and high-quality tweets, the generated reference summaries could be abstractive. Both informativeness and readability of the collected summaries are verified by manual judgment. In addition, we train a Support Vector Regression summarizer on DUC generic multi-document summarization benchmarks. With the collected data as extra training resource, the performance of the summarizer improves a lot on all the test sets. We release this dataset for further research.
A Dependency-Based Neural Network for Relation Classification
Jul 16, 2015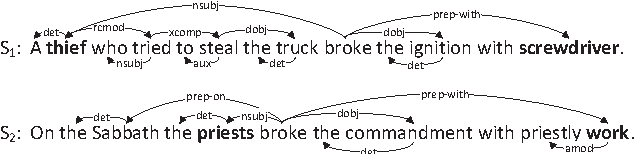

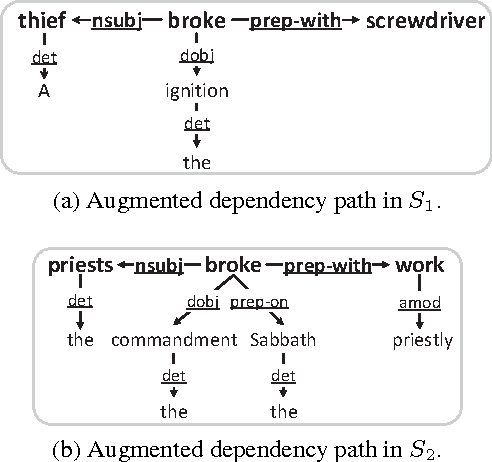
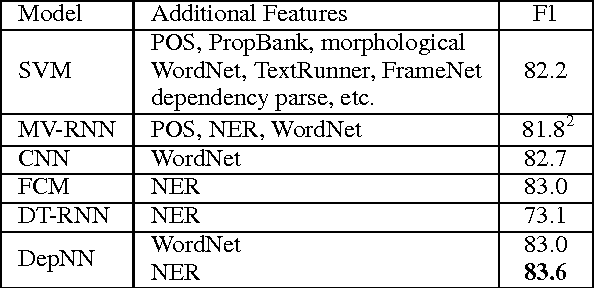
Previous research on relation classification has verified the effectiveness of using dependency shortest paths or subtrees. In this paper, we further explore how to make full use of the combination of these dependency information. We first propose a new structure, termed augmented dependency path (ADP), which is composed of the shortest dependency path between two entities and the subtrees attached to the shortest path. To exploit the semantic representation behind the ADP structure, we develop dependency-based neural networks (DepNN): a recursive neural network designed to model the subtrees, and a convolutional neural network to capture the most important features on the shortest path. Experiments on the SemEval-2010 dataset show that our proposed method achieves state-of-art results.
Multi-Document Summarization via Discriminative Summary Reranking
Jul 08, 2015
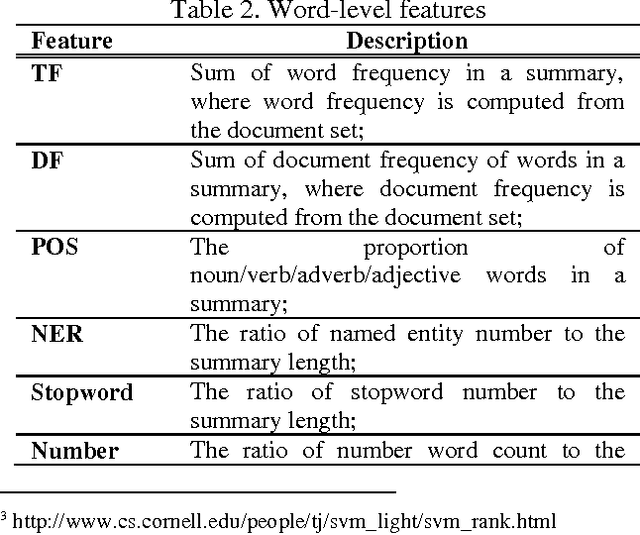

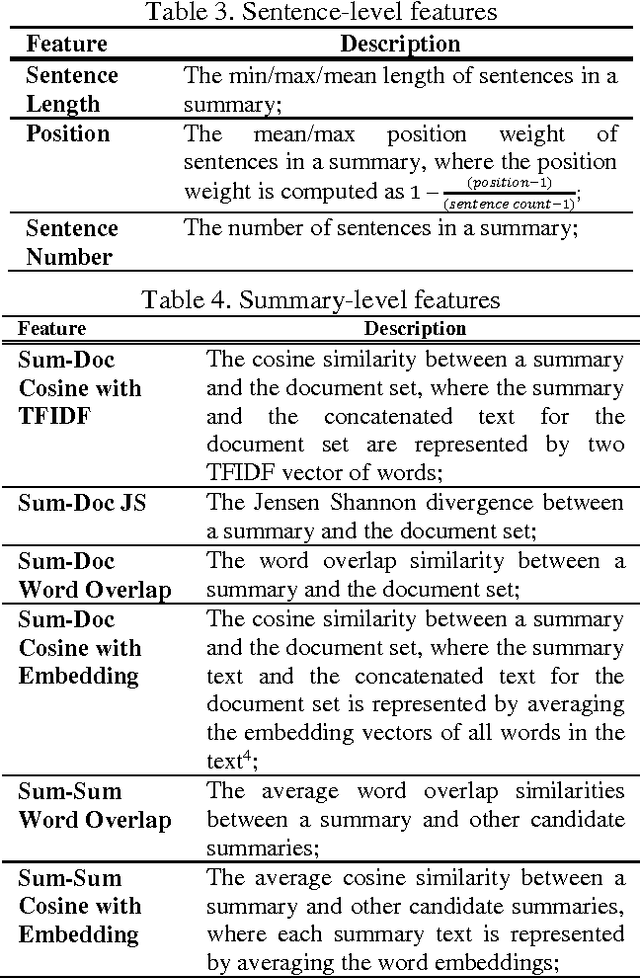
Existing multi-document summarization systems usually rely on a specific summarization model (i.e., a summarization method with a specific parameter setting) to extract summaries for different document sets with different topics. However, according to our quantitative analysis, none of the existing summarization models can always produce high-quality summaries for different document sets, and even a summarization model with good overall performance may produce low-quality summaries for some document sets. On the contrary, a baseline summarization model may produce high-quality summaries for some document sets. Based on the above observations, we treat the summaries produced by different summarization models as candidate summaries, and then explore discriminative reranking techniques to identify high-quality summaries from the candidates for difference document sets. We propose to extract a set of candidate summaries for each document set based on an ILP framework, and then leverage Ranking SVM for summary reranking. Various useful features have been developed for the reranking process, including word-level features, sentence-level features and summary-level features. Evaluation results on the benchmark DUC datasets validate the efficacy and robustness of our proposed approach.
A Statistical Parsing Framework for Sentiment Classification
Mar 05, 2015We present a statistical parsing framework for sentence-level sentiment classification in this article. Unlike previous works that employ syntactic parsing results for sentiment analysis, we develop a statistical parser to directly analyze the sentiment structure of a sentence. We show that complicated phenomena in sentiment analysis (e.g., negation, intensification, and contrast) can be handled the same as simple and straightforward sentiment expressions in a unified and probabilistic way. We formulate the sentiment grammar upon Context-Free Grammars (CFGs), and provide a formal description of the sentiment parsing framework. We develop the parsing model to obtain possible sentiment parse trees for a sentence, from which the polarity model is proposed to derive the sentiment strength and polarity, and the ranking model is dedicated to selecting the best sentiment tree. We train the parser directly from examples of sentences annotated only with sentiment polarity labels but without any syntactic annotations or polarity annotations of constituents within sentences. Therefore we can obtain training data easily. In particular, we train a sentiment parser, s.parser, from a large amount of review sentences with users' ratings as rough sentiment polarity labels. Extensive experiments on existing benchmark datasets show significant improvements over baseline sentiment classification approaches.