 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Self-attention for Cross-domain Sequential Recommendation
May 27, 2025Sequential recommendation is a popular paradigm in modern recommender systems. In particular, one challenging problem in this space is cross-domain sequential recommendation (CDSR), which aims to predict future behaviors given user interactions across multiple domains. Existing CDSR frameworks are mostly built on the self-attention transformer and seek to improve by explicitly injecting additional domain-specific components (e.g. domain-aware module blocks). While these additional components help, we argue they overlook the core self-attention module already present in the transformer, a naturally powerful tool to learn correlations among behaviors. In this work, we aim to improve the CDSR performance for simple models from a novel perspective of enhancing the self-attention. Specifically, we introduce a Pareto-optimal self-attention and formulate the cross-domain learning as a multi-objective problem, where we optimize the recommendation task while dynamically minimizing the cross-domain attention scores. Our approach automates knowledge transfer in CDSR (dubbed as AutoCDSR) -- it not only mitigates negative transfer but also encourages complementary knowledge exchange among auxiliary domains. Based on the idea, we further introduce AutoCDSR+, a more performant variant with slight additional cost. Our proposal is easy to implement and works as a plug-and-play module that can be incorporated into existing transformer-based recommenders. Besides flexibility, it is practical to deploy because it brings little extra computational overheads without heavy hyper-parameter tuning. AutoCDSR on average improves Recall@10 for SASRec and Bert4Rec by 9.8% and 16.0% and NDCG@10 by 12.0% and 16.7%, respectively. Code is available at https://github.com/snap-research/AutoCDSR.
Learning Universal User Representations Leveraging Cross-domain User Intent at Snapchat
Apr 30, 2025The development of powerful user representations is a key factor in the success of recommender systems (RecSys). Online platforms employ a range of RecSys techniques to personalize user experience across diverse in-app surfaces. User representations are often learned individually through user's historical interactions within each surface and user representations across different surfaces can be shared post-hoc as auxiliary features or additional retrieval sources. While effective, such schemes cannot directly encode collaborative filtering signals across different surfaces, hindering its capacity to discover complex relationships between user behaviors and preferences across the whole platform. To bridge this gap at Snapchat, we seek to conduct universal user modeling (UUM) across different in-app surfaces, learning general-purpose user representations which encode behaviors across surfaces. Instead of replacing domain-specific representations, UUM representations capture cross-domain trends, enriching existing representations with complementary information. This work discusses our efforts in developing initial UUM versions, practical challenges, technical choices and modeling and research directions with promising offline performance. Following successful A/B testing, UUM representations have been launched in production, powering multiple use cases and demonstrating their value. UUM embedding has been incorporated into (i) Long-form Video embedding-based retrieval, leading to 2.78% increase in Long-form Video Open Rate, (ii) Long-form Video L2 ranking, with 19.2% increase in Long-form Video View Time sum, (iii) Lens L2 ranking, leading to 1.76% increase in Lens play time, and (iv) Notification L2 ranking, with 0.87% increase in Notification Open Rate.
Aligning Coordinated Text Streams through Burst Information Network Construction and Decipherment
Sep 27, 2016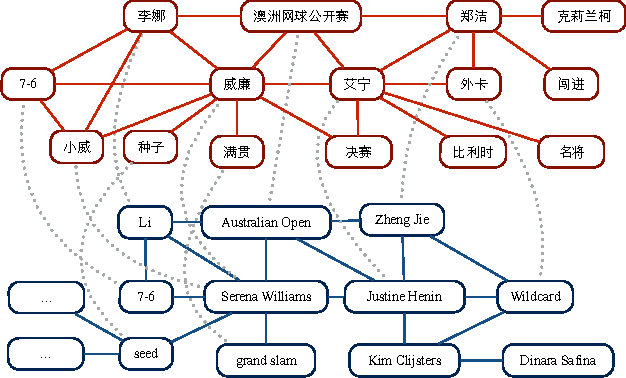

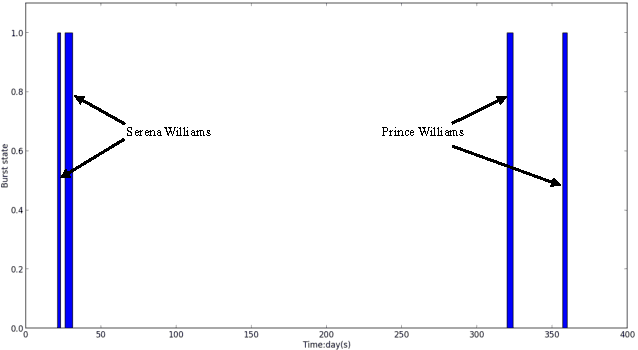
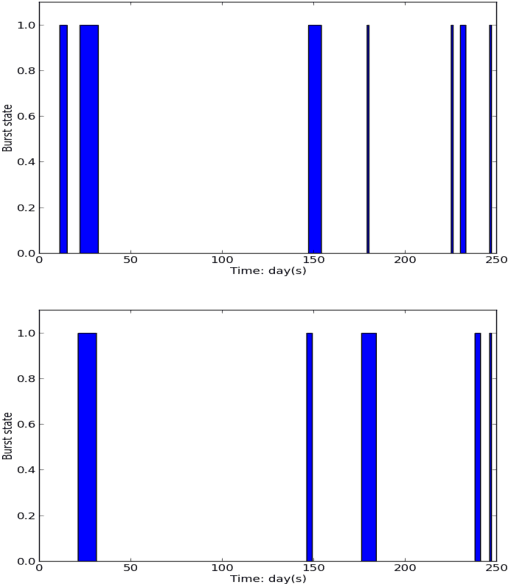
Aligning coordinated text streams from multiple sources and multiple languages has opened many new research venues on cross-lingual knowledge discovery. In this paper we aim to advance state-of-the-art by: (1). extending coarse-grained topic-level knowledge mining to fine-grained information units such as entities and events; (2). following a novel Data-to-Network-to-Knowledge (D2N2K) paradigm to construct and utilize network structures to capture and propagate reliable evidence. We introduce a novel Burst Information Network (BINet) representation that can display the most important information and illustrate the connections among bursty entities, events and keywords in the corpus. We propose an effective approach to construct and decipher BINets, incorporating novel criteria based on multi-dimensional clues from pronunciation, translation, burst, neighbor and graph topological structure. The experimental results on Chinese and English coordinated text streams show that our approach can accurately decipher the nodes with high confidence in the BINets and that the algorithm can be efficiently run in parallel, which makes it possible to apply it to huge amounts of streaming data for never-ending language and information decipherment.