 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Relevant Knowledge in Context Modeling and Response Generation
Nov 09, 2018
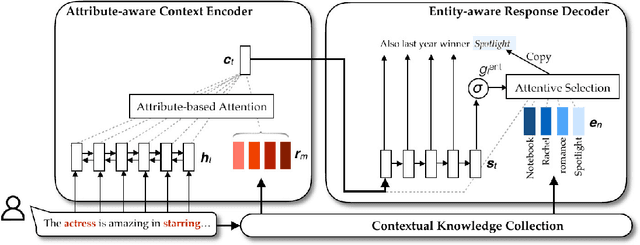
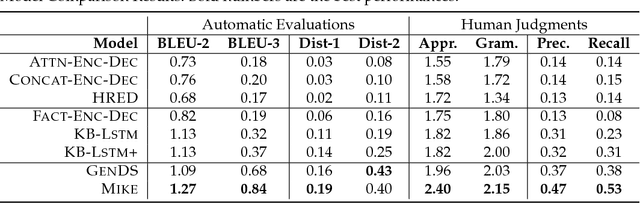
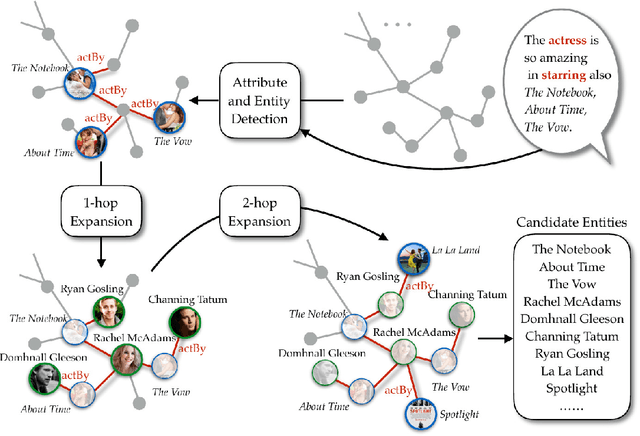
To sustain engaging conversation, it is critical for chatbots to make good use of relevant knowledge. Equipped with a knowledge base, chatbots are able to extract conversation-related attributes and entities to facilitate context modeling and response generation. In this work, we distinguish the uses of attribute and entity and incorporate them into the encoder-decoder architecture in different manners. Based on the augmented architecture, our chatbot, namely Mike, is able to generate responses by referring to proper entities from the collected knowledge. To validate the proposed approach, we build a movie conversation corpus on which the proposed approach significantly outperforms other four knowledge-grounded models.
TGSum: Build Tweet Guided Multi-Document Summarization Dataset
Nov 26, 2015
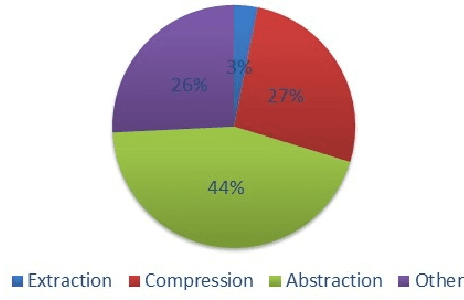
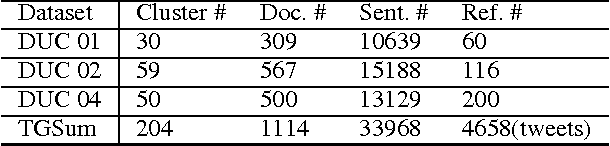

The development of summarization research has been significantly hampered by the costly acquisition of reference summaries. This paper proposes an effective way to automatically collect large scales of news-related multi-document summaries with reference to social media's reactions. We utilize two types of social labels in tweets, i.e., hashtags and hyper-links. Hashtags are used to cluster documents into different topic sets. Also, a tweet with a hyper-link often highlights certain key points of the corresponding document. We synthesize a linked document cluster to form a reference summary which can cover most key points. To this aim, we adopt the ROUGE metrics to measure the coverage ratio, and develop an Integer Linear Programming solution to discover the sentence set reaching the upper bound of ROUGE. Since we allow summary sentences to be selected from both documents and high-quality tweets, the generated reference summaries could be abstractive. Both informativeness and readability of the collected summaries are verified by manual judgment. In addition, we train a Support Vector Regression summarizer on DUC generic multi-document summarization benchmarks. With the collected data as extra training resource, the performance of the summarizer improves a lot on all the test sets. We release this dataset for further research.