 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJarvis: Towards Personalized AI Assistant via Personal KV-Cache Retrieval
Oct 26, 2025


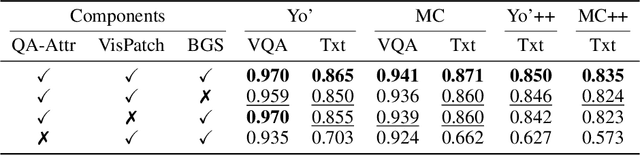
The rapid development of Vision-language models (VLMs) enables open-ended perception and reasoning. Recent works have started to investigate how to adapt general-purpose VLMs into personalized assistants. Even commercial models such as ChatGPT now support model personalization by incorporating user-specific information. However, existing methods either learn a set of concept tokens or train a VLM to utilize user-specific information. However, both pipelines struggle to generate accurate answers as personalized assistants. We introduce Jarvis, an innovative framework for a personalized AI assistant through personal KV-Cache retrieval, which stores user-specific information in the KV-Caches of both textual and visual tokens. The textual tokens are created by summarizing user information into metadata, while the visual tokens are produced by extracting distinct image patches from the user's images. When answering a question, Jarvis first retrieves related KV-Caches from personal storage and uses them to ensure accuracy in responses. We also introduce a fine-grained benchmark built with the same distinct image patch mining pipeline, emphasizing accurate question answering based on fine-grained user-specific information. Jarvis is capable of providing more accurate responses, particularly when they depend on specific local details. Jarvis achieves state-of-the-art results in both visual question answering and text-only tasks across multiple datasets, indicating a practical path toward personalized AI assistants. The code and dataset will be released.
Rethinking Driving World Model as Synthetic Data Generator for Perception Tasks
Oct 22, 2025Recent advancements in driving world models enable controllable generation of high-quality RGB videos or multimodal videos. Existing methods primarily focus on metrics related to generation quality and controllability. However, they often overlook the evaluation of downstream perception tasks, which are $\mathbf{really\ crucial}$ for the performance of autonomous driving. Existing methods usually leverage a training strategy that first pretrains on synthetic data and finetunes on real data, resulting in twice the epochs compared to the baseline (real data only). When we double the epochs in the baseline, the benefit of synthetic data becomes negligible. To thoroughly demonstrate the benefit of synthetic data, we introduce Dream4Drive, a novel synthetic data generation framework designed for enhancing the downstream perception tasks. Dream4Drive first decomposes the input video into several 3D-aware guidance maps and subsequently renders the 3D assets onto these guidance maps. Finally, the driving world model is fine-tuned to produce the edited, multi-view photorealistic videos, which can be used to train the downstream perception models. Dream4Drive enables unprecedented flexibility in generating multi-view corner cases at scale, significantly boosting corner case perception in autonomous driving. To facilitate future research, we also contribute a large-scale 3D asset dataset named DriveObj3D, covering the typical categories in driving scenarios and enabling diverse 3D-aware video editing. We conduct comprehensive experiments to show that Dream4Drive can effectively boost the performance of downstream perception models under various training epochs. Project: $\href{https://wm-research.github.io/Dream4Drive/}{this\ https\ URL}$
Low-Cost and Detunable Wireless Resonator Glasses for Enhanced Eye MRI with Concurrent High-Quality Whole Brain MRI
Sep 10, 2025



Purpose: To develop and evaluate a wearable wireless resonator glasses design that enhances eye MRI signal-to-noise ratio (SNR) without compromising whole-brain image quality at 7 T. Methods: The device integrates two detunable LC loop resonators into a lightweight, 3D-printed frame positioned near the eyes. The resonators passively couple to a standard 2Tx/32Rx head coil without hardware modifications. Bench tests assessed tuning, isolation, and detuning performance. B1$^+$ maps were measured in a head/shoulder phantom, and SNR maps were obtained in both phantom and in vivo experiments. Results: Bench measurements confirmed accurate tuning, strong inter-element isolation, and effective passive detuning. Phantom B1$^+$ mapping showed negligible differences between configurations with and without the resonators. Phantom and in vivo imaging demonstrated up to about a 3-fold SNR gain in the eye region, with no measurable SNR loss in the brain. Conclusion: The wireless resonator glasses provide a low-cost, easy-to-use solution that improves ocular SNR while preserving whole-brain image quality, enabling both dedicated eye MRI and simultaneous eye-brain imaging at ultrahigh field.
MMG-Vid: Maximizing Marginal Gains at Segment-level and Token-level for Efficient Video LLMs
Aug 28, 2025



Video Large Language Models (VLLMs) excel in video understanding, but their excessive visual tokens pose a significant computational challenge for real-world applications. Current methods aim to enhance inference efficiency by visual token pruning. However, they do not consider the dynamic characteristics and temporal dependencies of video frames, as they perceive video understanding as a multi-frame task. To address these challenges, we propose MMG-Vid, a novel training-free visual token pruning framework that removes redundancy by Maximizing Marginal Gains at both segment-level and token-level. Specifically, we first divide the video into segments based on frame similarity, and then dynamically allocate the token budget for each segment to maximize the marginal gain of each segment. Subsequently, we propose a temporal-guided DPC algorithm that jointly models inter-frame uniqueness and intra-frame diversity, thereby maximizing the marginal gain of each token. By combining both stages, MMG-Vid can maximize the utilization of the limited token budget, significantly improving efficiency while maintaining strong performance. Extensive experiments demonstrate that MMG-Vid can maintain over 99.5% of the original performance, while effectively reducing 75% visual tokens and accelerating the prefilling stage by 3.9x on LLaVA-OneVision-7B. Code will be released soon.
Small-Large Collaboration: Training-efficient Concept Personalization for Large VLM using a Meta Personalized Small VLM
Aug 10, 2025



Personalizing Vision-Language Models (VLMs) to transform them into daily assistants has emerged as a trending research direction. However, leading companies like OpenAI continue to increase model size and develop complex designs such as the chain of thought (CoT). While large VLMs are proficient in complex multi-modal understanding, their high training costs and limited access via paid APIs restrict direct personalization. Conversely, small VLMs are easily personalized and freely available, but they lack sufficient reasoning capabilities. Inspired by this, we propose a novel collaborative framework named Small-Large Collaboration (SLC) for large VLM personalization, where the small VLM is responsible for generating personalized information, while the large model integrates this personalized information to deliver accurate responses. To effectively incorporate personalized information, we develop a test-time reflection strategy, preventing the potential hallucination of the small VLM. Since SLC only needs to train a meta personalized small VLM for the large VLMs, the overall process is training-efficient. To the best of our knowledge, this is the first training-efficient framework that supports both open-source and closed-source large VLMs, enabling broader real-world personalized applications. We conduct thorough experiments across various benchmarks and large VLMs to demonstrate the effectiveness of the proposed SLC framework. The code will be released at https://github.com/Hhankyangg/SLC.
Perception-Oriented Latent Coding for High-Performance Compressed Domain Semantic Inference
Jul 02, 2025In recent years, compressed domain semantic inference has primarily relied on learned image coding models optimized for mean squared error (MSE). However, MSE-oriented optimization tends to yield latent spaces with limited semantic richness, which hinders effective semantic inference in downstream tasks. Moreover, achieving high performance with these models often requires fine-tuning the entire vision model, which is computationally intensive, especially for large models. To address these problems, we introduce Perception-Oriented Latent Coding (POLC), an approach that enriches the semantic content of latent features for high-performance compressed domain semantic inference. With the semantically rich latent space, POLC requires only a plug-and-play adapter for fine-tuning, significantly reducing the parameter count compared to previous MSE-oriented methods. Experimental results demonstrate that POLC achieves rate-perception performance comparable to state-of-the-art generative image coding methods while markedly enhancing performance in vision tasks, with minimal fine-tuning overhead. Code is available at https://github.com/NJUVISION/POLC.
Beyond Attention or Similarity: Maximizing Conditional Diversity for Token Pruning in MLLMs
Jun 12, 2025



In multimodal large language models (MLLMs), the length of input visual tokens is often significantly greater than that of their textual counterparts, leading to a high inference cost. Many works aim to address this issue by removing redundant visual tokens. However, current approaches either rely on attention-based pruning, which retains numerous duplicate tokens, or use similarity-based pruning, overlooking the instruction relevance, consequently causing suboptimal performance. In this paper, we go beyond attention or similarity by proposing a novel visual token pruning method named CDPruner, which maximizes the conditional diversity of retained tokens. We first define the conditional similarity between visual tokens conditioned on the instruction, and then reformulate the token pruning problem with determinantal point process (DPP) to maximize the conditional diversity of the selected subset. The proposed CDPruner is training-free and model-agnostic, allowing easy application to various MLLMs. Extensive experiments across diverse MLLMs show that CDPruner establishes new state-of-the-art on various vision-language benchmarks. By maximizing conditional diversity through DPP, the selected subset better represents the input images while closely adhering to user instructions, thereby preserving strong performance even with high reduction ratios. When applied to LLaVA, CDPruner reduces FLOPs by 95\% and CUDA latency by 78\%, while maintaining 94\% of the original accuracy. Our code is available at https://github.com/Theia-4869/CDPruner.
OmniIndoor3D: Comprehensive Indoor 3D Reconstruction
May 27, 2025We propose a novel framework for comprehensive indoor 3D reconstruction using Gaussian representations, called OmniIndoor3D. This framework enables accurate appearance, geometry, and panoptic reconstruction of diverse indoor scenes captured by a consumer-level RGB-D camera. Since 3DGS is primarily optimized for photorealistic rendering, it lacks the precise geometry critical for high-quality panoptic reconstruction. Therefore, OmniIndoor3D first combines multiple RGB-D images to create a coarse 3D reconstruction, which is then used to initialize the 3D Gaussians and guide the 3DGS training. To decouple the optimization conflict between appearance and geometry, we introduce a lightweight MLP that adjusts the geometric properties of 3D Gaussians. The introduced lightweight MLP serves as a low-pass filter for geometry reconstruction and significantly reduces noise in indoor scenes. To improve the distribution of Gaussian primitives, we propose a densification strategy guided by panoptic priors to encourage smoothness on planar surfaces. Through the joint optimization of appearance, geometry, and panoptic reconstruction, OmniIndoor3D provides comprehensive 3D indoor scene understanding, which facilitates accurate and robust robotic navigation. We perform thorough evaluations across multiple datasets, and OmniIndoor3D achieves state-of-the-art results in appearance, geometry, and panoptic reconstruction. We believe our work bridges a critical gap in indoor 3D reconstruction. The code will be released at: https://ucwxb.github.io/OmniIndoor3D/
K-Buffers: A Plug-in Method for Enhancing Neural Fields with Multiple Buffers
May 26, 2025



Neural fields are now the central focus of research in 3D vision and computer graphics. Existing methods mainly focus on various scene representations, such as neural points and 3D Gaussians. However, few works have studied the rendering process to enhance the neural fields. In this work, we propose a plug-in method named K-Buffers that leverages multiple buffers to improve the rendering performance. Our method first renders K buffers from scene representations and constructs K pixel-wise feature maps. Then, We introduce a K-Feature Fusion Network (KFN) to merge the K pixel-wise feature maps. Finally, we adopt a feature decoder to generate the rendering image. We also introduce an acceleration strategy to improve rendering speed and quality. We apply our method to well-known radiance field baselines, including neural point fields and 3D Gaussian Splatting (3DGS). Extensive experiments demonstrate that our method effectively enhances the rendering performance of neural point fields and 3DGS.
UniCTokens: Boosting Personalized Understanding and Generation via Unified Concept Tokens
May 20, 2025Personalized models have demonstrated remarkable success in understanding and generating concepts provided by users. However, existing methods use separate concept tokens for understanding and generation, treating these tasks in isolation. This may result in limitations for generating images with complex prompts. For example, given the concept $\langle bo\rangle$, generating "$\langle bo\rangle$ wearing its hat" without additional textual descriptions of its hat. We call this kind of generation personalized knowledge-driven generation. To address the limitation, we present UniCTokens, a novel framework that effectively integrates personalized information into a unified vision language model (VLM) for understanding and generation. UniCTokens trains a set of unified concept tokens to leverage complementary semantics, boosting two personalized tasks. Moreover, we propose a progressive training strategy with three stages: understanding warm-up, bootstrapping generation from understanding, and deepening understanding from generation to enhance mutual benefits between both tasks. To quantitatively evaluate the unified VLM personalization, we present UnifyBench, the first benchmark for assessing concept understanding, concept generation, and knowledge-driven generation. Experimental results on UnifyBench indicate that UniCTokens shows competitive performance compared to leading methods in concept understanding, concept generation, and achieving state-of-the-art results in personalized knowledge-driven generation. Our research demonstrates that enhanced understanding improves generation, and the generation process can yield valuable insights into understanding. Our code and dataset will be released at: \href{https://github.com/arctanxarc/UniCTokens}{https://github.com/arctanxarc/UniCTokens}.