 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRNGDet++: Road Network Graph Detection by Transformer with Instance Segmentation and Multi-scale Features Enhancement
Sep 21, 2022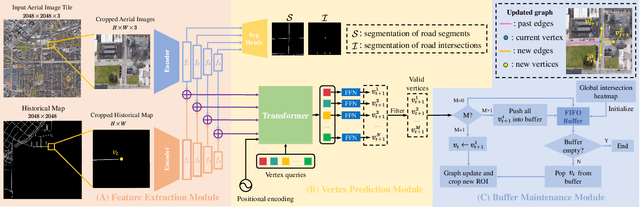
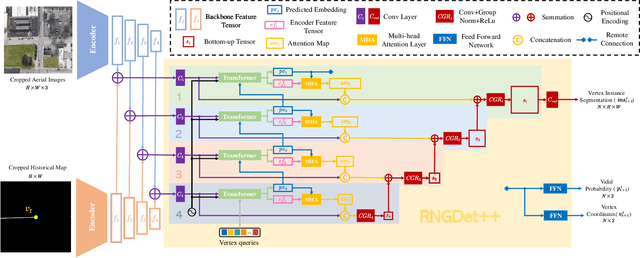
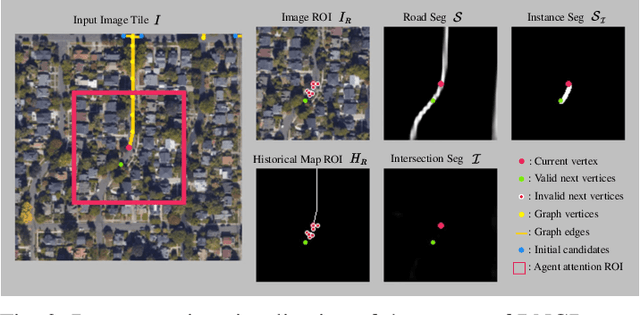
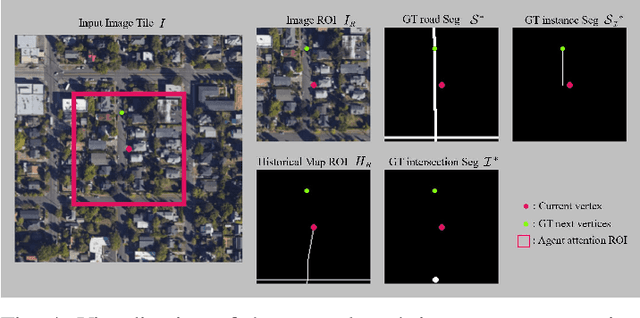
The graph structure of road networks is critical for downstream tasks of autonomous driving systems, such as global planning, motion prediction and control. In the past, the road network graph is usually manually annotated by human experts, which is time-consuming and labor-intensive. To obtain the road network graph with better effectiveness and efficiency, automatic approaches for road network graph detection are required. Previous works either post-process semantic segmentation maps or propose graph-based algorithms to directly predict the road network graph. However, previous works suffer from hard-coded heuristic processing algorithms and inferior final performance. To enhance the previous SOTA (State-of-the-Art) approach RNGDet, we add an instance segmentation head to better supervise the model training, and enable the model to leverage multi-scale features of the backbone network. Since the new proposed approach is improved from RNGDet, it is named RNGDet++. All approaches are evaluated on a large publicly available dataset. RNGDet++ outperforms baseline models on almost all metrics scores. It improves the topology correctness APLS (Average Path Length Similarity) by around 3\%. The demo video and supplementary materials are available on our project page \url{https://tonyxuqaq.github.io/projects/RNGDetPlusPlus/}.
V2HDM-Mono: A Framework of Building a Marking-Level HD Map with One or More Monocular Cameras
Sep 16, 2022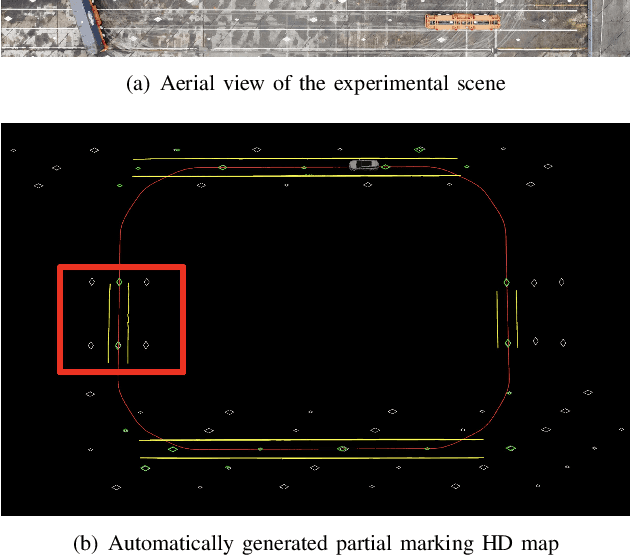
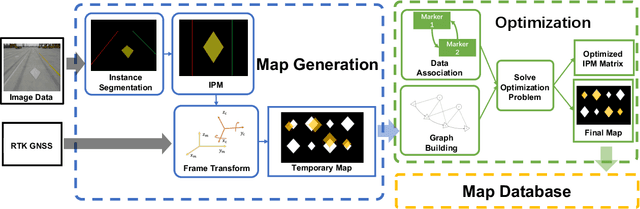

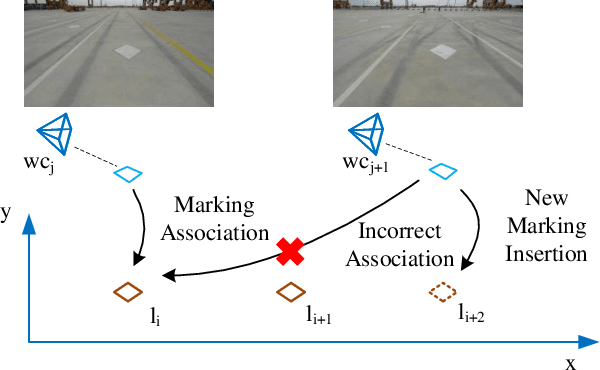
Marking-level high-definition maps (HD maps) are of great significance for autonomous vehicles, especially in large-scale, appearance-changing scenarios where autonomous vehicles rely on markings for localization and lanes for safe driving. In this paper, we propose a highly feasible framework for automatically building a marking-level HD map using a simple sensor setup (one or more monocular cameras). We optimize the position of the marking corners to fit the result of marking segmentation and simultaneously optimize the inverse perspective mapping (IPM) matrix of the corresponding camera to obtain an accurate transformation from the front view image to the bird's-eye view (BEV). In the quantitative evaluation, the built HD map almost attains centimeter-level accuracy. The accuracy of the optimized IPM matrix is similar to that of the manual calibration. The method can also be generalized to build HD maps in a broader sense by increasing the types of recognizable markings.
CenterLineDet: Road Lane CenterLine Graph Detection With Vehicle-Mounted Sensors by Transformer for High-definition Map Creation
Sep 16, 2022



With the rapid development of autonomous vehicles, there witnesses a booming demand for high-definition maps (HD maps) that provide reliable and robust prior information of static surroundings in autonomous driving scenarios. As one of the main high-level elements in the HD map, the road lane centerline is critical for downstream tasks, such as prediction and planning. Manually annotating lane centerline HD maps by human annotators is labor-intensive, expensive and inefficient, severely restricting the wide application and fast deployment of autonomous driving systems. Previous works seldom explore the centerline HD map mapping problem due to the complicated topology and severe overlapping issues of road centerlines. In this paper, we propose a novel method named CenterLineDet to create the lane centerline HD map automatically. CenterLineDet is trained by imitation learning and can effectively detect the graph of lane centerlines by iterations with vehicle-mounted sensors. Due to the application of the DETR-like transformer network, CenterLineDet can handle complicated graph topology, such as lane intersections. The proposed approach is evaluated on a large publicly available dataset Nuscenes, and the superiority of CenterLineDet is well demonstrated by the comparison results. This paper is accompanied by a demo video and a supplementary document that are available at \url{https://tonyxuqaq.github.io/projects/CenterLineDet/}.
ElasticROS: An Elastically Collaborative Robot Operation System for Fog and Cloud Robotics
Sep 05, 2022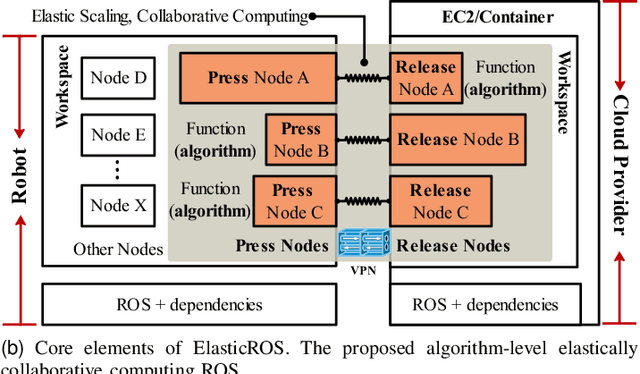
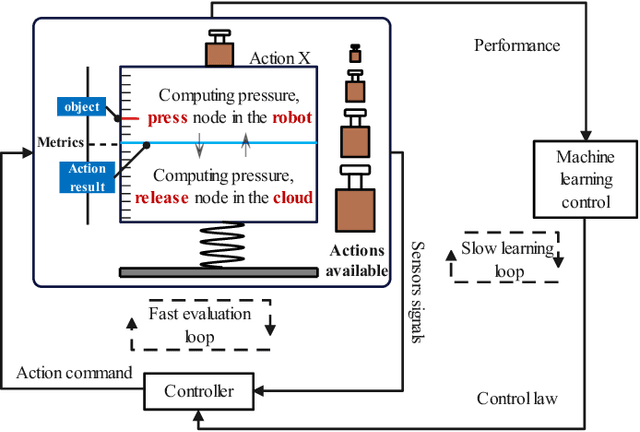
Robots are integrating more huge-size models to enrich functions and improve accuracy, which leads to out-of-control computing pressure. And thus robots are encountering bottlenecks in computing power and battery capacity. Fog or cloud robotics is one of the most anticipated theories to address these issues. Approaches of cloud robotics have developed from system-level to node-level. However, the present node-level systems are not flexible enough to dynamically adapt to changing conditions. To address this, we present ElasticROS, which evolves the present node-level systems into an algorithm-level one. ElasticROS is based on ROS and ROS2. For fog and cloud robotics, it is the first robot operating system with algorithm-level collaborative computing. ElasticROS develops elastic collaborative computing to achieve adaptability to dynamic conditions. The collaborative computing algorithm is the core and challenge of ElasticROS. We abstract the problem and then propose an algorithm named ElasAction to address. It is a dynamic action decision algorithm based on online learning, which determines how robots and servers cooperate. The algorithm dynamically updates parameters to adapt to changes of conditions where the robot is currently in. It achieves elastically distributing of computing tasks to robots and servers according to configurations. In addition, we prove that the regret upper bound of the ElasAction is sublinear, which guarantees its convergence and thus enables ElasticROS to be stable in its elasticity. Finally, we conducted experiments with ElasticROS on common tasks of robotics, including SLAM, grasping and human-robot dialogue, and then measured its performances in latency, CPU usage and power consumption. The algorithm-level ElasticROS performs significantly better than the present node-level system.
FusionPortable: A Multi-Sensor Campus-Scene Dataset for Evaluation of Localization and Mapping Accuracy on Diverse Platforms
Aug 25, 2022

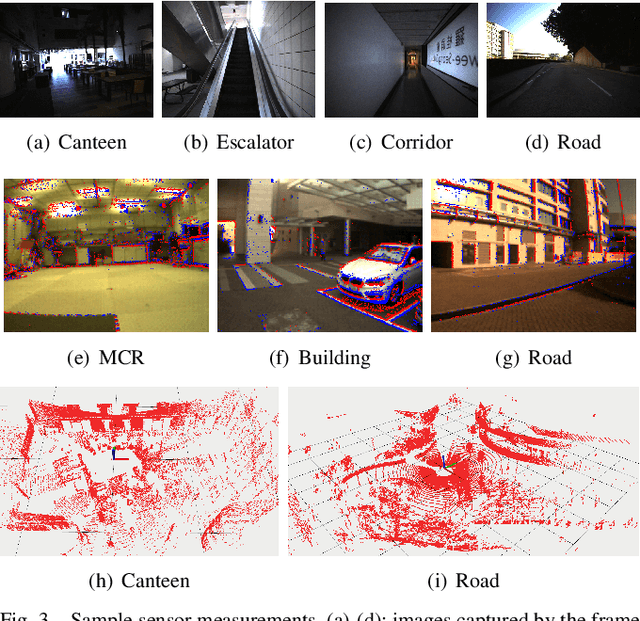

Combining multiple sensors enables a robot to maximize its perceptual awareness of environments and enhance its robustness to external disturbance, crucial to robotic navigation. This paper proposes the FusionPortable benchmark, a complete multi-sensor dataset with a diverse set of sequences for mobile robots. This paper presents three contributions. We first advance a portable and versatile multi-sensor suite that offers rich sensory measurements: 10Hz LiDAR point clouds, 20Hz stereo frame images, high-rate and asynchronous events from stereo event cameras, 200Hz inertial readings from an IMU, and 10Hz GPS signal. Sensors are already temporally synchronized in hardware. This device is lightweight, self-contained, and has plug-and-play support for mobile robots. Second, we construct a dataset by collecting 17 sequences that cover a variety of environments on the campus by exploiting multiple robot platforms for data collection. Some sequences are challenging to existing SLAM algorithms. Third, we provide ground truth for the decouple localization and mapping performance evaluation. We additionally evaluate state-of-the-art SLAM approaches and identify their limitations. The dataset, consisting of raw sensor easurements, ground truth, calibration data, and evaluated algorithms, will be released: https://ram-lab.com/file/site/multi-sensor-dataset.
Real-time Neural Dense Elevation Mapping for Urban Terrain with Uncertainty Estimations
Aug 06, 2022Having good knowledge of terrain information is essential for improving the performance of various downstream tasks on complex terrains, especially for the locomotion and navigation of legged robots. We present a novel framework for neural urban terrain reconstruction with uncertainty estimations. It generates dense robot-centric elevation maps online from sparse LiDAR observations. We design a novel pre-processing and point features representation approach that ensures high robustness and computational efficiency when integrating multiple point cloud frames. A Bayesian-GAN model then recovers the detailed terrain structures while simultaneously providing the pixel-wise reconstruction uncertainty. We evaluate the proposed pipeline through extensive simulation and real-world experiments. It demonstrates efficient terrain reconstruction with high quality and real-time performance on a mobile platform, which further benefits the downstream tasks of legged robots. (See https://kin-zhang.github.io/ndem/ for more details.)
A Survey on Leveraging Pre-trained Generative Adversarial Networks for Image Editing and Restoration
Jul 21, 2022

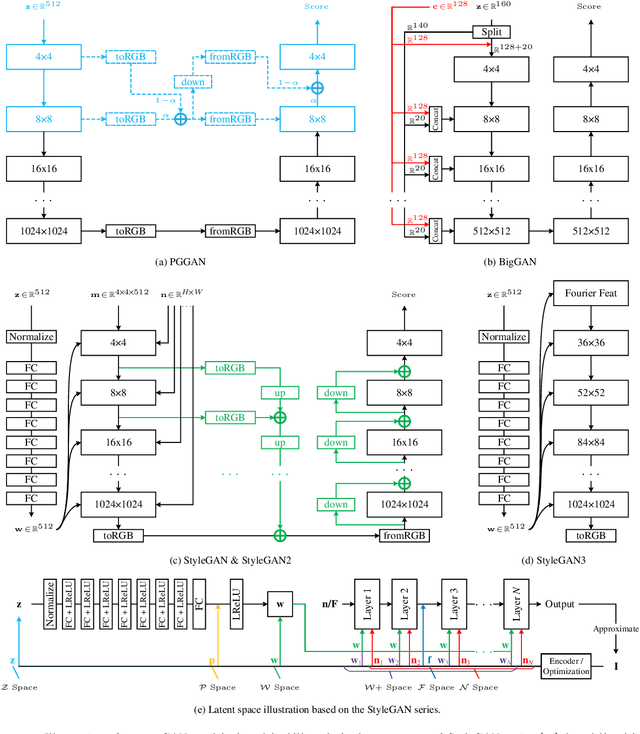

Generative adversarial networks (GANs) have drawn enormous attention due to the simple yet effective training mechanism and superior image generation quality. With the ability to generate photo-realistic high-resolution (e.g., $1024\times1024$) images, recent GAN models have greatly narrowed the gaps between the generated images and the real ones. Therefore, many recent works show emerging interest to take advantage of pre-trained GAN models by exploiting the well-disentangled latent space and the learned GAN priors. In this paper, we briefly review recent progress on leveraging pre-trained large-scale GAN models from three aspects, i.e., 1) the training of large-scale generative adversarial networks, 2) exploring and understanding the pre-trained GAN models, and 3) leveraging these models for subsequent tasks like image restoration and editing. More information about relevant methods and repositories can be found at https://github.com/csmliu/pretrained-GANs.
Learning Diverse Tone Styles for Image Retouching
Jul 12, 2022


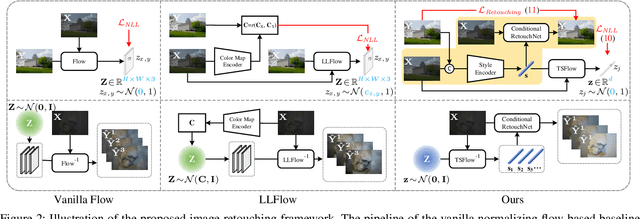
Image retouching, aiming to regenerate the visually pleasing renditions of given images, is a subjective task where the users are with different aesthetic sensations. Most existing methods deploy a deterministic model to learn the retouching style from a specific expert, making it less flexible to meet diverse subjective preferences. Besides, the intrinsic diversity of an expert due to the targeted processing on different images is also deficiently described. To circumvent such issues, we propose to learn diverse image retouching with normalizing flow-based architectures. Unlike current flow-based methods which directly generate the output image, we argue that learning in a style domain could (i) disentangle the retouching styles from the image content, (ii) lead to a stable style presentation form, and (iii) avoid the spatial disharmony effects. For obtaining meaningful image tone style representations, a joint-training pipeline is delicately designed, which is composed of a style encoder, a conditional RetouchNet, and the image tone style normalizing flow (TSFlow) module. In particular, the style encoder predicts the target style representation of an input image, which serves as the conditional information in the RetouchNet for retouching, while the TSFlow maps the style representation vector into a Gaussian distribution in the forward pass. After training, the TSFlow can generate diverse image tone style vectors by sampling from the Gaussian distribution. Extensive experiments on MIT-Adobe FiveK and PPR10K datasets show that our proposed method performs favorably against state-of-the-art methods and is effective in generating diverse results to satisfy different human aesthetic preferences. Source code and pre-trained models are publicly available at https://github.com/SSRHeart/TSFlow.
VEM$^2$L: A Plug-and-play Framework for Fusing Text and Structure Knowledge on Sparse Knowledge Graph Completion
Jul 12, 2022
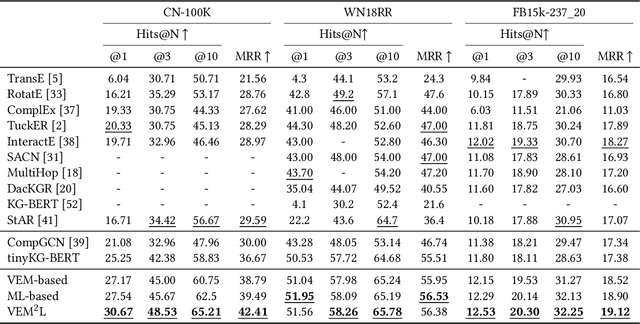
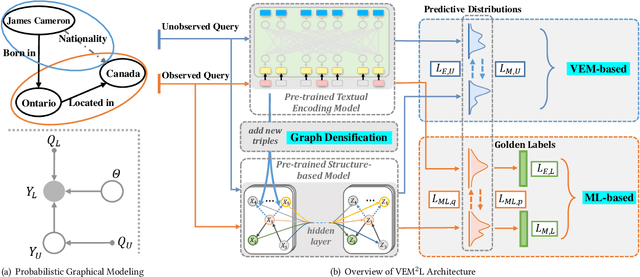
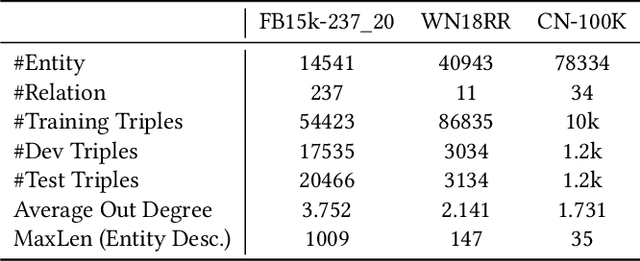
Knowledge Graph Completion has been widely studied recently to complete missing elements within triples via mainly modeling graph structural features, but performs sensitive to the sparsity of graph structure. Relevant texts like entity names and descriptions, acting as another expression form for Knowledge Graphs (KGs), are expected to solve this challenge. Several methods have been proposed to utilize both structure and text messages with two encoders, but only achieved limited improvements due to the failure to balance weights between them. And reserving both structural and textual encoders during inference also suffers from heavily overwhelmed parameters. Motivated by Knowledge Distillation, we view knowledge as mappings from input to output probabilities and propose a plug-and-play framework VEM2L over sparse KGs to fuse knowledge extracted from text and structure messages into a unity. Specifically, we partition knowledge acquired by models into two nonoverlapping parts: one part is relevant to the fitting capacity upon training triples, which could be fused by motivating two encoders to learn from each other on training sets; the other reflects the generalization ability upon unobserved queries. And correspondingly, we propose a new fusion strategy proved by Variational EM algorithm to fuse the generalization ability of models, during which we also apply graph densification operations to further alleviate the sparse graph problem. By combining these two fusion methods, we propose VEM2L framework finally. Both detailed theoretical evidence, as well as quantitative and qualitative experiments, demonstrates the effectiveness and efficiency of our proposed framework.
Open-world Semantic Segmentation for LIDAR Point Clouds
Jul 04, 2022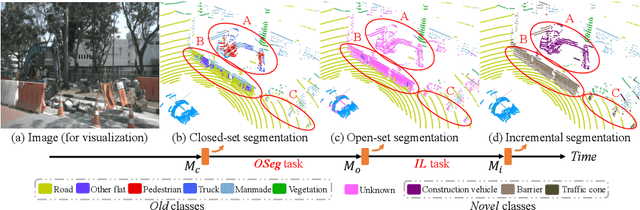
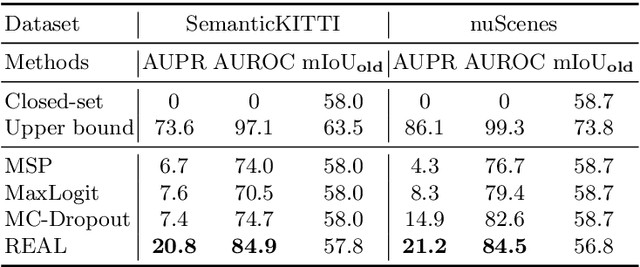
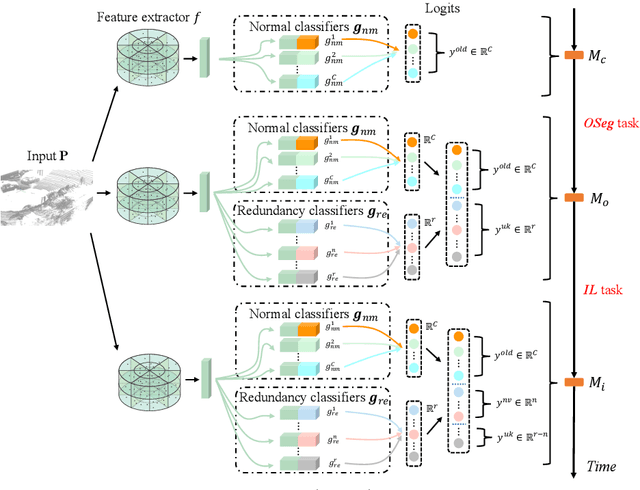

Current methods for LIDAR semantic segmentation are not robust enough for real-world applications, e.g., autonomous driving, since it is closed-set and static. The closed-set assumption makes the network only able to output labels of trained classes, even for objects never seen before, while a static network cannot update its knowledge base according to what it has seen. Therefore, in this work, we propose the open-world semantic segmentation task for LIDAR point clouds, which aims to 1) identify both old and novel classes using open-set semantic segmentation, and 2) gradually incorporate novel objects into the existing knowledge base using incremental learning without forgetting old classes. For this purpose, we propose a REdundAncy cLassifier (REAL) framework to provide a general architecture for both the open-set semantic segmentation and incremental learning problems. The experimental results show that REAL can simultaneously achieves state-of-the-art performance in the open-set semantic segmentation task on the SemanticKITTI and nuScenes datasets, and alleviate the catastrophic forgetting problem with a large margin during incremental learning.