 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvariance on Manifolds: Understanding Robust Visual Representations for Place Recognition
Jan 31, 2026Visual Place Recognition (VPR) demands representations robust to drastic environmental and viewpoint shifts. Current aggregation paradigms, however, either rely on data-hungry supervision or simplistic first-order statistics, often neglecting intrinsic structural correlations. In this work, we propose a Second-Order Geometric Statistics framework that inherently captures geometric stability without training. We conceptualize scenes as covariance descriptors on the Symmetric Positive Definite (SPD) manifold, where perturbations manifest as tractable congruence transformations. By leveraging geometry-aware Riemannian mappings, we project these descriptors into a linearized Euclidean embedding, effectively decoupling signal structure from noise. Our approach introduces a training-free framework built upon fixed, pre-trained backbones, achieving strong zero-shot generalization without parameter updates. Extensive experiments confirm that our method achieves highly competitive performance against state-of-the-art baselines, particularly excelling in challenging zero-shot scenarios.
Diffusion-Based Restoration for Multi-Modal 3D Object Detection in Adverse Weather
Dec 18, 2025Multi-modal 3D object detection is important for reliable perception in robotics and autonomous driving. However, its effectiveness remains limited under adverse weather conditions due to weather-induced distortions and misalignment between different data modalities. In this work, we propose DiffFusion, a novel framework designed to enhance robustness in challenging weather through diffusion-based restoration and adaptive cross-modal fusion. Our key insight is that diffusion models possess strong capabilities for denoising and generating data that can adapt to various weather conditions. Building on this, DiffFusion introduces Diffusion-IR restoring images degraded by weather effects and Point Cloud Restoration (PCR) compensating for corrupted LiDAR data using image object cues. To tackle misalignments between two modalities, we develop Bidirectional Adaptive Fusion and Alignment Module (BAFAM). It enables dynamic multi-modal fusion and bidirectional bird's-eye view (BEV) alignment to maintain consistent spatial correspondence. Extensive experiments on three public datasets show that DiffFusion achieves state-of-the-art robustness under adverse weather while preserving strong clean-data performance. Zero-shot results on the real-world DENSE dataset further validate its generalization. The implementation of our DiffFusion will be released as open-source.
KDMOS:Knowledge Distillation for Motion Segmentation
Jun 17, 2025



Motion Object Segmentation (MOS) is crucial for autonomous driving, as it enhances localization, path planning, map construction, scene flow estimation, and future state prediction. While existing methods achieve strong performance, balancing accuracy and real-time inference remains a challenge. To address this, we propose a logits-based knowledge distillation framework for MOS, aiming to improve accuracy while maintaining real-time efficiency. Specifically, we adopt a Bird's Eye View (BEV) projection-based model as the student and a non-projection model as the teacher. To handle the severe imbalance between moving and non-moving classes, we decouple them and apply tailored distillation strategies, allowing the teacher model to better learn key motion-related features. This approach significantly reduces false positives and false negatives. Additionally, we introduce dynamic upsampling, optimize the network architecture, and achieve a 7.69% reduction in parameter count, mitigating overfitting. Our method achieves a notable IoU of 78.8% on the hidden test set of the SemanticKITTI-MOS dataset and delivers competitive results on the Apollo dataset. The KDMOS implementation is available at https://github.com/SCNU-RISLAB/KDMOS.
Leveraging Nested MLMC for Sequential Neural Posterior Estimation with Intractable Likelihoods
Jan 30, 2024



Sequential neural posterior estimation (SNPE) techniques have been recently proposed for dealing with simulation-based models with intractable likelihoods. They are devoted to learning the posterior from adaptively proposed simulations using neural network-based conditional density estimators. As a SNPE technique, the automatic posterior transformation (APT) method proposed by Greenberg et al. (2019) performs notably and scales to high dimensional data. However, the APT method bears the computation of an expectation of the logarithm of an intractable normalizing constant, i.e., a nested expectation. Although atomic APT was proposed to solve this by discretizing the normalizing constant, it remains challenging to analyze the convergence of learning. In this paper, we propose a nested APT method to estimate the involved nested expectation instead. This facilitates establishing the convergence analysis. Since the nested estimators for the loss function and its gradient are biased, we make use of unbiased multi-level Monte Carlo (MLMC) estimators for debiasing. To further reduce the excessive variance of the unbiased estimators, this paper also develops some truncated MLMC estimators by taking account of the trade-off between the bias and the average cost. Numerical experiments for approximating complex posteriors with multimodal in moderate dimensions are provided.
An efficient likelihood-free Bayesian inference method based on sequential neural posterior estimation
Nov 27, 2023Sequential neural posterior estimation (SNPE) techniques have been recently proposed for dealing with simulation-based models with intractable likelihoods. Unlike approximate Bayesian computation, SNPE techniques learn the posterior from sequential simulation using neural network-based conditional density estimators by minimizing a specific loss function. The SNPE method proposed by Lueckmann et al. (2017) used a calibration kernel to boost the sample weights around the observed data, resulting in a concentrated loss function. However, the use of calibration kernels may increase the variances of both the empirical loss and its gradient, making the training inefficient. To improve the stability of SNPE, this paper proposes to use an adaptive calibration kernel and several variance reduction techniques. The proposed method greatly speeds up the process of training, and provides a better approximation of the posterior than the original SNPE method and some existing competitors as confirmed by numerical experiments.
FusionPortable: A Multi-Sensor Campus-Scene Dataset for Evaluation of Localization and Mapping Accuracy on Diverse Platforms
Aug 25, 2022

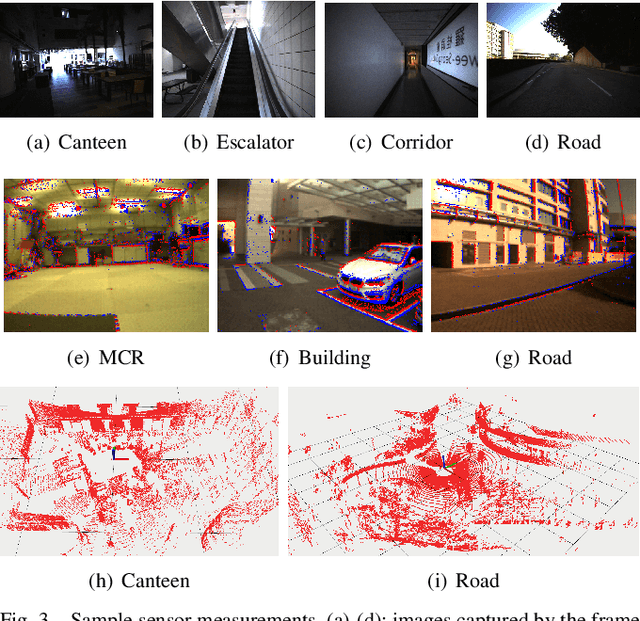

Combining multiple sensors enables a robot to maximize its perceptual awareness of environments and enhance its robustness to external disturbance, crucial to robotic navigation. This paper proposes the FusionPortable benchmark, a complete multi-sensor dataset with a diverse set of sequences for mobile robots. This paper presents three contributions. We first advance a portable and versatile multi-sensor suite that offers rich sensory measurements: 10Hz LiDAR point clouds, 20Hz stereo frame images, high-rate and asynchronous events from stereo event cameras, 200Hz inertial readings from an IMU, and 10Hz GPS signal. Sensors are already temporally synchronized in hardware. This device is lightweight, self-contained, and has plug-and-play support for mobile robots. Second, we construct a dataset by collecting 17 sequences that cover a variety of environments on the campus by exploiting multiple robot platforms for data collection. Some sequences are challenging to existing SLAM algorithms. Third, we provide ground truth for the decouple localization and mapping performance evaluation. We additionally evaluate state-of-the-art SLAM approaches and identify their limitations. The dataset, consisting of raw sensor easurements, ground truth, calibration data, and evaluated algorithms, will be released: https://ram-lab.com/file/site/multi-sensor-dataset.
Comparing Representations in Tracking for Event Camera-based SLAM
Apr 20, 2021
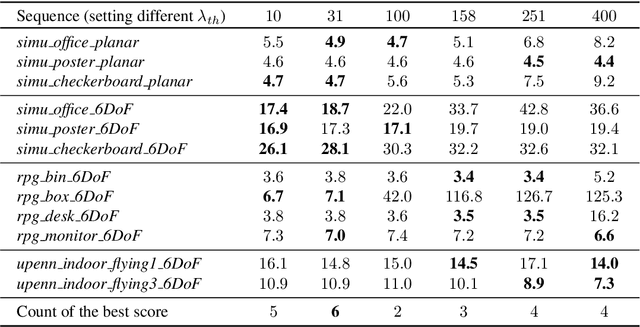

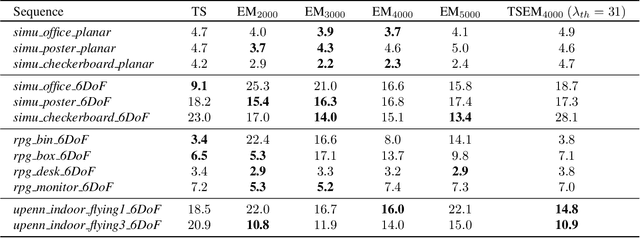
This paper investigates two typical image-type representations for event camera-based tracking: time surface (TS) and event map (EM). Based on the original TS-based tracker, we make use of these two representations' complementary strengths to develop an enhanced version. The proposed tracker consists of a general strategy to evaluate the optimization problem's degeneracy online and then switch proper representations. Both TS and EM are motion- and scene-dependent, and thus it is important to figure out their limitations in tracking. We develop six tracker variations and conduct a thorough comparison of them on sequences covering various scenarios and motion complexities. We release our implementations and detailed results to benefit the research community on event cameras: https: //github.com/gogojjh/ESVO_extension.