 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTARIC: Memory-Augmented Traversability-Aware Outdoor VLN under Interrupted Semantic Cues
May 29, 2026Outdoor vision-language navigation (VLN) in long-range, open-world environments is frequently disrupted by semantic-cue interruptions, where informative goal cues become sparse, occluded, or leave the field of view. Once such cues disappear, agents enter a cue-free phase and often degrade into backtracking, oscillatory headings, or aimless exploration. While memory-based methods attempt to bridge these gaps, they often fail under traversability-driven detours: the remembered cue direction may be infeasible, forcing detours that prolong cue-free phases and gradually render robot-centric cues stale and implicit histories blurred. This makes traversability a stability condition for maintaining goal-directed guidance, rather than merely a local safety concern. We propose a unified outdoor VLN framework that survives semantic-cue interruptions by maintaining traversability-consistent executable guidance throughout prolonged cue-free phases. Specifically, our method extracts semantic bearings from visibility-gated goal or exploration cues and grounds them into executable headings using a real-time near-field traversability profile, providing goal-consistent feasible guidance beyond reject-only safety filtering. To prevent guidance degradation during detours, we lift intermittent 2D evidence into a world-aligned 3D cue memory with an uncertainty-aware readout mechanism, ensuring guidance remains continuously reachable and stable as the robot moves. We evaluate the framework on quadrupedal and wheeled platforms over 600--1000 m routes. Our method improves simulation success rate by over 10 percentage points over the strongest baseline and achieves a real-world success rate of 40%, compared to 17.5% for the strongest baseline, with substantially higher robustness during prolonged cue-free intervals.
Enhancing Glass Surface Reconstruction via Depth Prior for Robot Navigation
Apr 20, 2026Indoor robot navigation is often compromised by glass surfaces, which severely corrupt depth sensor measurements. While foundation models like Depth Anything 3 provide excellent geometric priors, they lack an absolute metric scale. We propose a training-free framework that leverages depth foundation models as a structural prior, employing a robust local RANSAC-based alignment to fuse it with raw sensor depth. This naturally avoids contamination from erroneous glass measurements and recovers an accurate metric scale. Furthermore, we introduce \ti{GlassRecon}, a novel RGB-D dataset with geometrically derived ground truth for glass regions. Extensive experiments demonstrate that our approach consistently outperforms state-of-the-art baselines, especially under severe sensor depth corruption. The dataset and related code will be released at https://github.com/jarvisyjw/GlassRecon.
OpenNavMap: Structure-Free Topometric Mapping via Large-Scale Collaborative Localization
Jan 18, 2026Scalable and maintainable map representations are fundamental to enabling large-scale visual navigation and facilitating the deployment of robots in real-world environments. While collaborative localization across multi-session mapping enhances efficiency, traditional structure-based methods struggle with high maintenance costs and fail in feature-less environments or under significant viewpoint changes typical of crowd-sourced data. To address this, we propose OPENNAVMAP, a lightweight, structure-free topometric system leveraging 3D geometric foundation models for on-demand reconstruction. Our method unifies dynamic programming-based sequence matching, geometric verification, and confidence-calibrated optimization to robust, coarse-to-fine submap alignment without requiring pre-built 3D models. Evaluations on the Map-Free benchmark demonstrate superior accuracy over structure-from-motion and regression baselines, achieving an average translation error of 0.62m. Furthermore, the system maintains global consistency across 15km of multi-session data with an absolute trajectory error below 3m for map merging. Finally, we validate practical utility through 12 successful autonomous image-goal navigation tasks on simulated and physical robots. Code and datasets will be publicly available in https://rpl-cs-ucl.github.io/OpenNavMap_page.
TPT-Bench: A Large-Scale, Long-Term and Robot-Egocentric Dataset for Benchmarking Target Person Tracking
May 12, 2025Tracking a target person from robot-egocentric views is crucial for developing autonomous robots that provide continuous personalized assistance or collaboration in Human-Robot Interaction (HRI) and Embodied AI. However, most existing target person tracking (TPT) benchmarks are limited to controlled laboratory environments with few distractions, clean backgrounds, and short-term occlusions. In this paper, we introduce a large-scale dataset designed for TPT in crowded and unstructured environments, demonstrated through a robot-person following task. The dataset is collected by a human pushing a sensor-equipped cart while following a target person, capturing human-like following behavior and emphasizing long-term tracking challenges, including frequent occlusions and the need for re-identification from numerous pedestrians. It includes multi-modal data streams, including odometry, 3D LiDAR, IMU, panoptic, and RGB-D images, along with exhaustively annotated 2D bounding boxes of the target person across 35 sequences, both indoors and outdoors. Using this dataset and visual annotations, we perform extensive experiments with existing TPT methods, offering a thorough analysis of their limitations and suggesting future research directions.
GV-Bench: Benchmarking Local Feature Matching for Geometric Verification of Long-term Loop Closure Detection
Jul 16, 2024



Visual loop closure detection is an important module in visual simultaneous localization and mapping (SLAM), which associates current camera observation with previously visited places. Loop closures correct drifts in trajectory estimation to build a globally consistent map. However, a false loop closure can be fatal, so verification is required as an additional step to ensure robustness by rejecting the false positive loops. Geometric verification has been a well-acknowledged solution that leverages spatial clues provided by local feature matching to find true positives. Existing feature matching methods focus on homography and pose estimation in long-term visual localization, lacking references for geometric verification. To fill the gap, this paper proposes a unified benchmark targeting geometric verification of loop closure detection under long-term conditional variations. Furthermore, we evaluate six representative local feature matching methods (handcrafted and learning-based) under the benchmark, with in-depth analysis for limitations and future directions.
FusionPortableV2: A Unified Multi-Sensor Dataset for Generalized SLAM Across Diverse Platforms and Scalable Environments
Apr 12, 2024Simultaneous Localization and Mapping (SLAM) technology has been widely applied in various robotic scenarios, from rescue operations to autonomous driving. However, the generalization of SLAM algorithms remains a significant challenge, as current datasets often lack scalability in terms of platforms and environments. To address this limitation, we present FusionPortableV2, a multi-sensor SLAM dataset featuring notable sensor diversity, varied motion patterns, and a wide range of environmental scenarios. Our dataset comprises $27$ sequences, spanning over $2.5$ hours and collected from four distinct platforms: a handheld suite, wheeled and legged robots, and vehicles. These sequences cover diverse settings, including buildings, campuses, and urban areas, with a total length of $38.7km$. Additionally, the dataset includes ground-truth (GT) trajectories and RGB point cloud maps covering approximately $0.3km^2$. To validate the utility of our dataset in advancing SLAM research, we assess several state-of-the-art (SOTA) SLAM algorithms. Furthermore, we demonstrate the dataset's broad applicability beyond traditional SLAM tasks by investigating its potential for monocular depth estimation. The complete dataset, including sensor data, GT, and calibration details, is accessible at https://fusionportable.github.io/dataset/fusionportable_v2.
FusionPortable: A Multi-Sensor Campus-Scene Dataset for Evaluation of Localization and Mapping Accuracy on Diverse Platforms
Aug 25, 2022

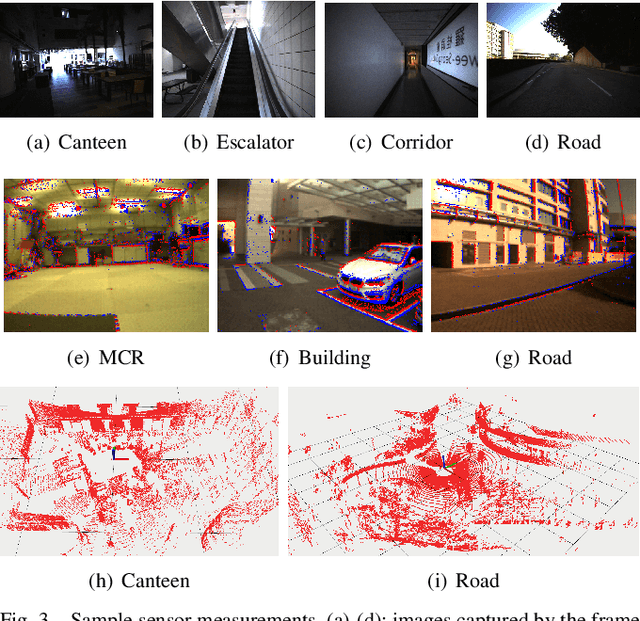

Combining multiple sensors enables a robot to maximize its perceptual awareness of environments and enhance its robustness to external disturbance, crucial to robotic navigation. This paper proposes the FusionPortable benchmark, a complete multi-sensor dataset with a diverse set of sequences for mobile robots. This paper presents three contributions. We first advance a portable and versatile multi-sensor suite that offers rich sensory measurements: 10Hz LiDAR point clouds, 20Hz stereo frame images, high-rate and asynchronous events from stereo event cameras, 200Hz inertial readings from an IMU, and 10Hz GPS signal. Sensors are already temporally synchronized in hardware. This device is lightweight, self-contained, and has plug-and-play support for mobile robots. Second, we construct a dataset by collecting 17 sequences that cover a variety of environments on the campus by exploiting multiple robot platforms for data collection. Some sequences are challenging to existing SLAM algorithms. Third, we provide ground truth for the decouple localization and mapping performance evaluation. We additionally evaluate state-of-the-art SLAM approaches and identify their limitations. The dataset, consisting of raw sensor easurements, ground truth, calibration data, and evaluated algorithms, will be released: https://ram-lab.com/file/site/multi-sensor-dataset.
Condition-Invariant and Compact Visual Place Description by Convolutional Autoencoder
Apr 15, 2022

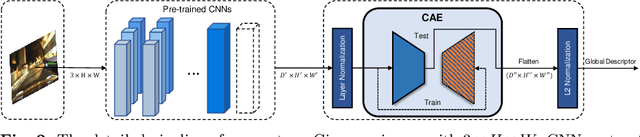
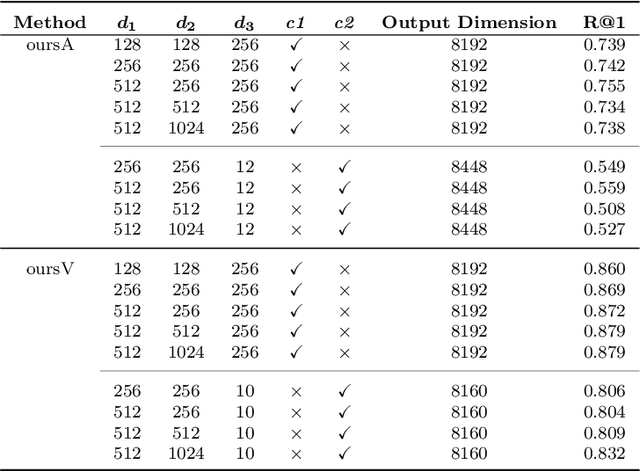
Visual place recognition (VPR) in condition-varying environments is still an open problem. Popular solutions are CNN-based image descriptors, which have been shown to outperform traditional image descriptors based on hand-crafted visual features. However, there are two drawbacks of current CNN-based descriptors: a) their high dimension and b) lack of generalization, leading to low efficiency and poor performance in applications. In this paper, we propose to use a convolutional autoencoder (CAE) to tackle this problem. We employ a high-level layer of a pre-trained CNN to generate features, and train a CAE to map the features to a low-dimensional space to improve the condition invariance property of the descriptor and reduce its dimension at the same time. We verify our method in three challenging datasets involving significant illumination changes, and our method is shown to be superior to the state-of-the-art. For the benefit of the community, we make public the source code.
Relationship Oriented Affordance Learning through Manipulation Graph Construction
Nov 01, 2021
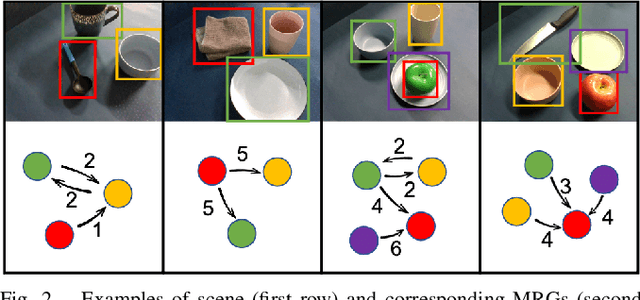
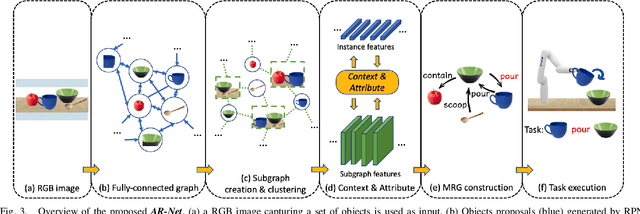
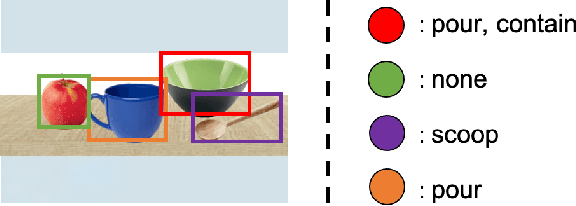
In this paper, we propose Manipulation Relationship Graph (MRG), a novel affordance representation which captures the underlying manipulation relationships of an arbitrary scene. To construct such a graph from raw visual observations, a deep nerual network named AR-Net is introduced. It consists of an Attribute module and a Context module, which guide the relationship learning at object and subgraph level respectively. We quantitatively validate our method on a novel manipulation relationship dataset named SMRD. To evaluate the performance of the proposed model and representation, both visual perception and physical manipulation experiments are conducted. Overall, AR-Net along with MRG outperforms all baselines, achieving the success rate of 88.89% on task relationship recognition (TRR) and 73.33% on task completion (TC)