 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Inverse Perspective Mapping for Automatic Vectorized Road Map Generation
Jan 27, 2026In this study, we present a low-cost and unified framework for vectorized road mapping leveraging enhanced inverse perspective mapping (IPM). In this framework, Catmull-Rom splines are utilized to characterize lane lines, and all the other ground markings are depicted using polygons uniformly. The results from instance segmentation serve as references to refine the three-dimensional position of spline control points and polygon corner points. In conjunction with this process, the homography matrix of IPM and vehicle poses are optimized simultaneously. Our proposed framework significantly reduces the mapping errors associated with IPM. It also improves the accuracy of the initial IPM homography matrix and the predicted vehicle poses. Furthermore, it addresses the limitations imposed by the coplanarity assumption in IPM. These enhancements enable IPM to be effectively applied to vectorized road mapping, which serves a cost-effective solution with enhanced accuracy. In addition, our framework generalizes road map elements to include all common ground markings and lane lines. The proposed framework is evaluated in two different practical scenarios, and the test results show that our method can automatically generate high-precision maps with near-centimeter-level accuracy. Importantly, the optimized IPM matrix achieves an accuracy comparable to that of manual calibration, while the accuracy of vehicle poses is also significantly improved.
Semantic-LiDAR-Inertial-Wheel Odometry Fusion for Robust Localization in Large-Scale Dynamic Environments
Sep 18, 2025Reliable, drift-free global localization presents significant challenges yet remains crucial for autonomous navigation in large-scale dynamic environments. In this paper, we introduce a tightly-coupled Semantic-LiDAR-Inertial-Wheel Odometry fusion framework, which is specifically designed to provide high-precision state estimation and robust localization in large-scale dynamic environments. Our framework leverages an efficient semantic-voxel map representation and employs an improved scan matching algorithm, which utilizes global semantic information to significantly reduce long-term trajectory drift. Furthermore, it seamlessly fuses data from LiDAR, IMU, and wheel odometry using a tightly-coupled multi-sensor fusion Iterative Error-State Kalman Filter (iESKF). This ensures reliable localization without experiencing abnormal drift. Moreover, to tackle the challenges posed by terrain variations and dynamic movements, we introduce a 3D adaptive scaling strategy that allows for flexible adjustments to wheel odometry measurement weights, thereby enhancing localization precision. This study presents extensive real-world experiments conducted in a one-million-square-meter automated port, encompassing 3,575 hours of operational data from 35 Intelligent Guided Vehicles (IGVs). The results consistently demonstrate that our system outperforms state-of-the-art LiDAR-based localization methods in large-scale dynamic environments, highlighting the framework's reliability and practical value.
MoK-RAG: Mixture of Knowledge Paths Enhanced Retrieval-Augmented Generation for Embodied AI Environments
Mar 18, 2025While human cognition inherently retrieves information from diverse and specialized knowledge sources during decision-making processes, current Retrieval-Augmented Generation (RAG) systems typically operate through single-source knowledge retrieval, leading to a cognitive-algorithmic discrepancy. To bridge this gap, we introduce MoK-RAG, a novel multi-source RAG framework that implements a mixture of knowledge paths enhanced retrieval mechanism through functional partitioning of a large language model (LLM) corpus into distinct sections, enabling retrieval from multiple specialized knowledge paths. Applied to the generation of 3D simulated environments, our proposed MoK-RAG3D enhances this paradigm by partitioning 3D assets into distinct sections and organizing them based on a hierarchical knowledge tree structure. Different from previous methods that only use manual evaluation, we pioneered the introduction of automated evaluation methods for 3D scenes. Both automatic and human evaluations in our experiments demonstrate that MoK-RAG3D can assist Embodied AI agents in generating diverse scenes.
CLRKDNet: Speeding up Lane Detection with Knowledge Distillation
May 21, 2024



Road lanes are integral components of the visual perception systems in intelligent vehicles, playing a pivotal role in safe navigation. In lane detection tasks, balancing accuracy with real-time performance is essential, yet existing methods often sacrifice one for the other. To address this trade-off, we introduce CLRKDNet, a streamlined model that balances detection accuracy with real-time performance. The state-of-the-art model CLRNet has demonstrated exceptional performance across various datasets, yet its computational overhead is substantial due to its Feature Pyramid Network (FPN) and muti-layer detection head architecture. Our method simplifies both the FPN structure and detection heads, redesigning them to incorporate a novel teacher-student distillation process alongside a newly introduced series of distillation losses. This combination reduces inference time by up to 60% while maintaining detection accuracy comparable to CLRNet. This strategic balance of accuracy and speed makes CLRKDNet a viable solution for real-time lane detection tasks in autonomous driving applications.
Monocular 3D lane detection for Autonomous Driving: Recent Achievements, Challenges, and Outlooks
Apr 10, 2024



3D lane detection plays a crucial role in autonomous driving by extracting structural and traffic information from the road in 3D space to assist the self-driving car in rational, safe, and comfortable path planning and motion control. Due to the consideration of sensor costs and the advantages of visual data in color information, in practical applications, 3D lane detection based on monocular vision is one of the important research directions in the field of autonomous driving, which has attracted more and more attention in both industry and academia. Unfortunately, recent progress in visual perception seems insufficient to develop completely reliable 3D lane detection algorithms, which also hinders the development of vision-based fully autonomous self-driving cars, i.e., achieving level 5 autonomous driving, driving like human-controlled cars. This is one of the conclusions drawn from this review paper: there is still a lot of room for improvement and significant improvements are still needed in the 3D lane detection algorithm for autonomous driving cars using visual sensors. Motivated by this, this review defines, analyzes, and reviews the current achievements in the field of 3D lane detection research, and the vast majority of the current progress relies heavily on computationally complex deep learning models. In addition, this review covers the 3D lane detection pipeline, investigates the performance of state-of-the-art algorithms, analyzes the time complexity of cutting-edge modeling choices, and highlights the main achievements and limitations of current research efforts. The survey also includes a comprehensive discussion of available 3D lane detection datasets and the challenges that researchers have faced but have not yet resolved. Finally, our work outlines future research directions and welcomes researchers and practitioners to enter this exciting field.
PALoc: Advancing SLAM Benchmarking with Prior-Assisted 6-DoF Trajectory Generation and Uncertainty Estimation
Feb 06, 2024



Accurately generating ground truth (GT) trajectories is essential for Simultaneous Localization and Mapping (SLAM) evaluation, particularly under varying environmental conditions. This study introduces a systematic approach employing a prior map-assisted framework for generating dense six-degree-of-freedom (6-DoF) GT poses for the first time, enhancing the fidelity of both indoor and outdoor SLAM datasets. Our method excels in handling degenerate and stationary conditions frequently encountered in SLAM datasets, thereby increasing robustness and precision. A significant aspect of our approach is the detailed derivation of covariances within the factor graph, enabling an in-depth analysis of pose uncertainty propagation. This analysis crucially contributes to demonstrating specific pose uncertainties and enhancing trajectory reliability from both theoretical and empirical perspectives. Additionally, we provide an open-source toolbox (https://github.com/JokerJohn/Cloud_Map_Evaluation) for map evaluation criteria, facilitating the indirect assessment of overall trajectory precision. Experimental results show at least a 30\% improvement in map accuracy and a 20\% increase in direct trajectory accuracy compared to the Iterative Closest Point (ICP) \cite{sharp2002icp} algorithm across diverse campus environments, with substantially enhanced robustness. Our open-source solution (https://github.com/JokerJohn/PALoc), extensively applied in the FusionPortable\cite{Jiao2022Mar} dataset, is geared towards SLAM benchmark dataset augmentation and represents a significant advancement in SLAM evaluations.
V2HDM-Mono: A Framework of Building a Marking-Level HD Map with One or More Monocular Cameras
Sep 16, 2022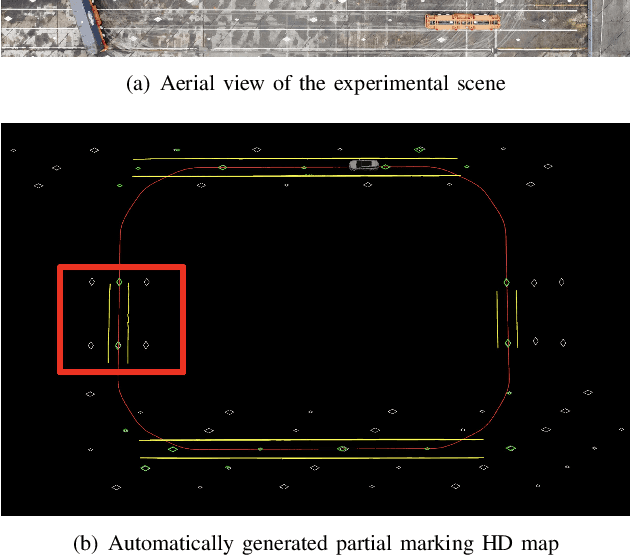
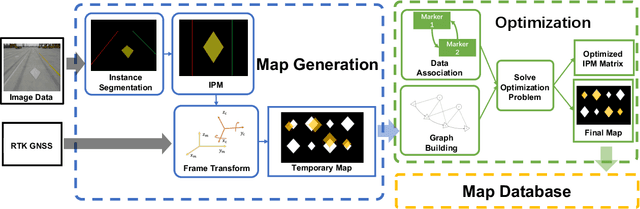

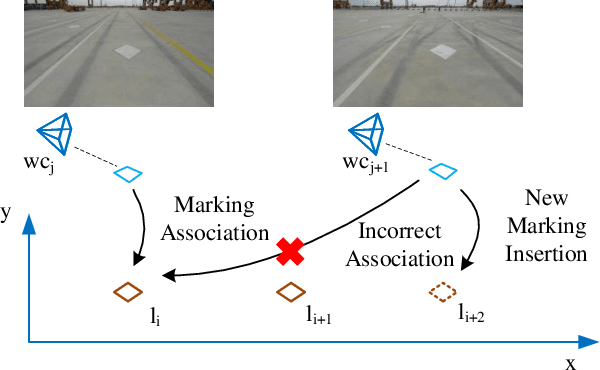
Marking-level high-definition maps (HD maps) are of great significance for autonomous vehicles, especially in large-scale, appearance-changing scenarios where autonomous vehicles rely on markings for localization and lanes for safe driving. In this paper, we propose a highly feasible framework for automatically building a marking-level HD map using a simple sensor setup (one or more monocular cameras). We optimize the position of the marking corners to fit the result of marking segmentation and simultaneously optimize the inverse perspective mapping (IPM) matrix of the corresponding camera to obtain an accurate transformation from the front view image to the bird's-eye view (BEV). In the quantitative evaluation, the built HD map almost attains centimeter-level accuracy. The accuracy of the optimized IPM matrix is similar to that of the manual calibration. The method can also be generalized to build HD maps in a broader sense by increasing the types of recognizable markings.
On Bundle Adjustment for Multiview PointCloud Registration
Aug 06, 2021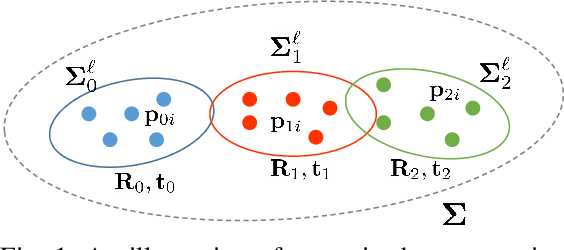
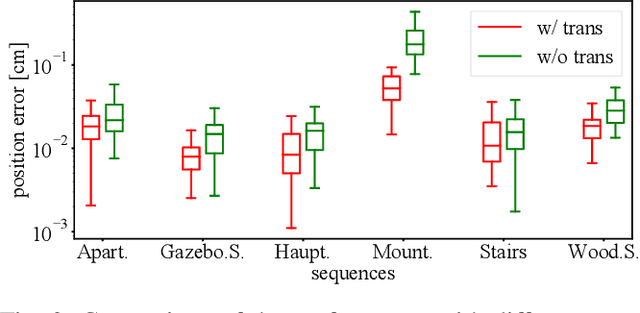
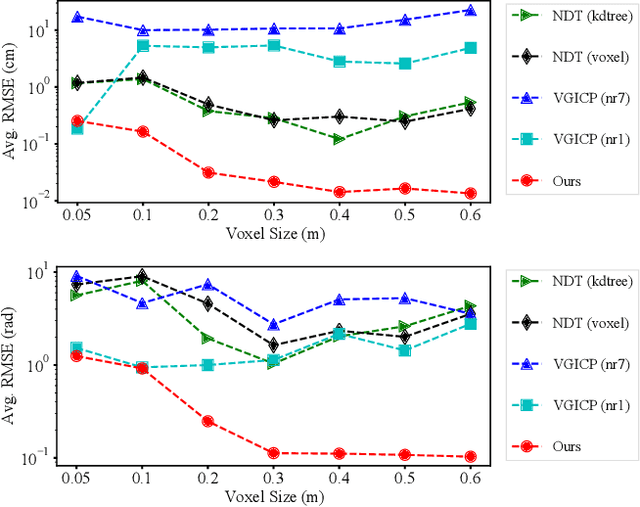
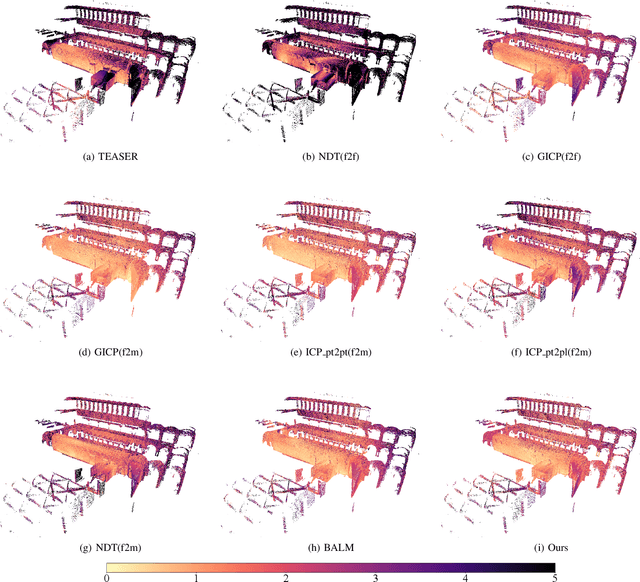
Multiview registration is used to estimate Rigid Body Transformations (RBTs) from multiple frames and reconstruct a scene with corresponding scans. Despite the success of pairwise registration and pose synchronization, the concept of Bundle Adjustment (BA) has been proven to better maintain global consistency. So in this work, we make the multiview point-cloud registration more tractable from a different perspective in resolving range-based BA. Based on this analysis, we propose an objective function that takes both measurement noises and computational cost into account. For the feature parameter update, instead of calculating the global distribution parameters from the raw measurements, we aggregate the local distributions upon the pose update at each iteration. The computational cost of feature update is then only dependent on the number of scans. Finally, we develop a multiview registration system using voxel-based quantization that can be applied in real-world scenarios. The experimental results demonstrate our superiority over the baselines in terms of both accuracy and speed. Moreover, the results also show that our average positioning errors achieve the centimeter level.
Robust Lane Marking Detection Algorithm Using Drivable Area Segmentation and Extended SLT
Nov 20, 2019


In this paper, a robust lane detection algorithm is proposed, where the vertical road profile of the road is estimated using dynamic programming from the v-disparity map and, based on the estimated profile, the road area is segmented. Since the lane markings are on the road area and any feature point above the ground will be a noise source for the lane detection, a mask is created for the road area to remove some of the noise for lane detection. The estimated mask is multiplied by the lane feature map in a bird's eye view (BEV). The lane feature points are extracted by using an extended version of symmetrical local threshold (SLT), which not only considers dark light dark transition (DLD) of the lane markings, like (SLT), but also considers parallelism on the lane marking borders. The segmentation then uses only the feature points that are on the road area. A maximum of two linear lane markings are detected using an efficient 1D Hough transform. Then, the detected linear lane markings are used to create a region of interest (ROI) for parabolic lane detection. Finally, based on the estimated region of interest, parabolic lane models are fitted using robust fitting. Due to the robust lane feature extraction and road area segmentation, the proposed algorithm robustly detects lane markings and achieves lane marking detection with an accuracy of 91% when tested on a sequence from the KITTI dataset.
Automatic Calibration of Dual-LiDARs Using Two Poles Stickered with Retro-Reflective Tape
Nov 02, 2019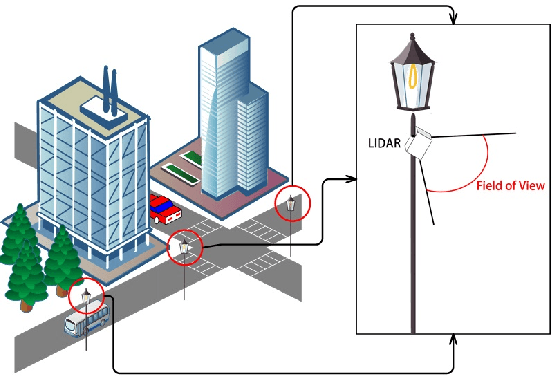

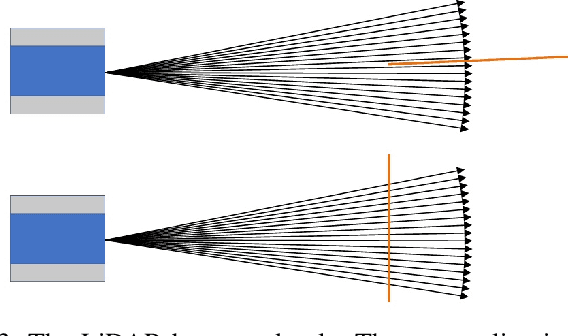
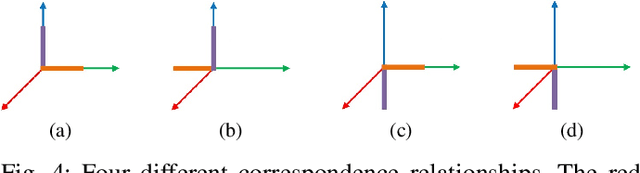
Multi-LiDAR systems have been prevalently applied in modern autonomous vehicles to render a broad view of the environments. The rapid development of 5G wireless technologies has brought a breakthrough for current cellular vehicle-to-everything (C-V2X) applications. Therefore, a novel localization and perception system in which multiple LiDARs are mounted around cities for autonomous vehicles has been proposed. However, the existing calibration methods require specific hard-to-move markers, ego-motion, or good initial values given by users. In this paper, we present a novel approach that enables automatic multi-LiDAR calibration using two poles stickered with retro-reflective tape. This method does not depend on prior environmental information, initial values of the extrinsic parameters, or movable platforms like a car. We analyze the LiDAR-pole model, verify the feasibility of the algorithm through simulation data, and present a simple method to measure the calibration errors w.r.t the ground truth. Experimental results demonstrate that our approach gains better flexibility and higher accuracy when compared with the state-of-the-art approach.