 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfiAgent: An Infinite-Horizon Framework for General-Purpose Autonomous Agents
Jan 06, 2026LLM agents can reason and use tools, but they often break down on long-horizon tasks due to unbounded context growth and accumulated errors. Common remedies such as context compression or retrieval-augmented prompting introduce trade-offs between information fidelity and reasoning stability. We present InfiAgent, a general-purpose framework that keeps the agent's reasoning context strictly bounded regardless of task duration by externalizing persistent state into a file-centric state abstraction. At each step, the agent reconstructs context from a workspace state snapshot plus a fixed window of recent actions. Experiments on DeepResearch and an 80-paper literature review task show that, without task-specific fine-tuning, InfiAgent with a 20B open-source model is competitive with larger proprietary systems and maintains substantially higher long-horizon coverage than context-centric baselines. These results support explicit state externalization as a practical foundation for stable long-horizon agents. Github Repo:https://github.com/ChenglinPoly/infiAgent
MaRCA: Multi-Agent Reinforcement Learning for Dynamic Computation Allocation in Large-Scale Recommender Systems
Dec 30, 2025Modern recommender systems face significant computational challenges due to growing model complexity and traffic scale, making efficient computation allocation critical for maximizing business revenue. Existing approaches typically simplify multi-stage computation resource allocation, neglecting inter-stage dependencies, thus limiting global optimality. In this paper, we propose MaRCA, a multi-agent reinforcement learning framework for end-to-end computation resource allocation in large-scale recommender systems. MaRCA models the stages of a recommender system as cooperative agents, using Centralized Training with Decentralized Execution (CTDE) to optimize revenue under computation resource constraints. We introduce an AutoBucket TestBench for accurate computation cost estimation, and a Model Predictive Control (MPC)-based Revenue-Cost Balancer to proactively forecast traffic loads and adjust the revenue-cost trade-off accordingly. Since its end-to-end deployment in the advertising pipeline of a leading global e-commerce platform in November 2024, MaRCA has consistently handled hundreds of billions of ad requests per day and has delivered a 16.67% revenue uplift using existing computation resources.
Schoenfeld's Anatomy of Mathematical Reasoning by Language Models
Dec 23, 2025



Large language models increasingly expose reasoning traces, yet their underlying cognitive structure and steps remain difficult to identify and analyze beyond surface-level statistics. We adopt Schoenfeld's Episode Theory as an inductive, intermediate-scale lens and introduce ThinkARM (Anatomy of Reasoning in Models), a scalable framework that explicitly abstracts reasoning traces into functional reasoning steps such as Analysis, Explore, Implement, Verify, etc. When applied to mathematical problem solving by diverse models, this abstraction reveals reproducible thinking dynamics and structural differences between reasoning and non-reasoning models, which are not apparent from token-level views. We further present two diagnostic case studies showing that exploration functions as a critical branching step associated with correctness, and that efficiency-oriented methods selectively suppress evaluative feedback steps rather than uniformly shortening responses. Together, our results demonstrate that episode-level representations make reasoning steps explicit, enabling systematic analysis of how reasoning is structured, stabilized, and altered in modern language models.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Can LLMs Estimate Student Struggles? Human-AI Difficulty Alignment with Proficiency Simulation for Item Difficulty Prediction
Dec 21, 2025



Accurate estimation of item (question or task) difficulty is critical for educational assessment but suffers from the cold start problem. While Large Language Models demonstrate superhuman problem-solving capabilities, it remains an open question whether they can perceive the cognitive struggles of human learners. In this work, we present a large-scale empirical analysis of Human-AI Difficulty Alignment for over 20 models across diverse domains such as medical knowledge and mathematical reasoning. Our findings reveal a systematic misalignment where scaling up model size is not reliably helpful; instead of aligning with humans, models converge toward a shared machine consensus. We observe that high performance often impedes accurate difficulty estimation, as models struggle to simulate the capability limitations of students even when being explicitly prompted to adopt specific proficiency levels. Furthermore, we identify a critical lack of introspection, as models fail to predict their own limitations. These results suggest that general problem-solving capability does not imply an understanding of human cognitive struggles, highlighting the challenge of using current models for automated difficulty prediction.
HiFi-Portrait: Zero-shot Identity-preserved Portrait Generation with High-fidelity Multi-face Fusion
Dec 16, 2025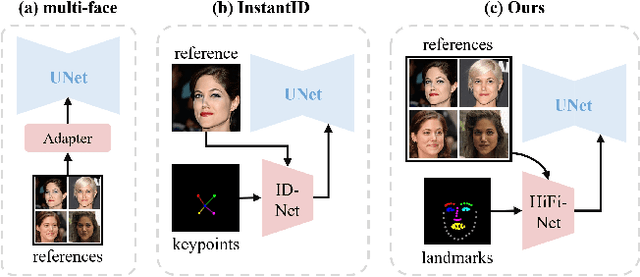
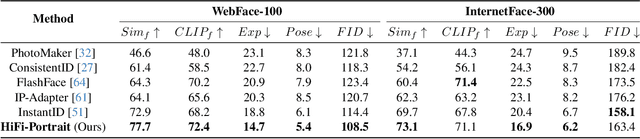


Recent advancements in diffusion-based technologies have made significant strides, particularly in identity-preserved portrait generation (IPG). However, when using multiple reference images from the same ID, existing methods typically produce lower-fidelity portraits and struggle to customize face attributes precisely. To address these issues, this paper presents HiFi-Portrait, a high-fidelity method for zero-shot portrait generation. Specifically, we first introduce the face refiner and landmark generator to obtain fine-grained multi-face features and 3D-aware face landmarks. The landmarks include the reference ID and the target attributes. Then, we design HiFi-Net to fuse multi-face features and align them with landmarks, which improves ID fidelity and face control. In addition, we devise an automated pipeline to construct an ID-based dataset for training HiFi-Portrait. Extensive experimental results demonstrate that our method surpasses the SOTA approaches in face similarity and controllability. Furthermore, our method is also compatible with previous SDXL-based works.
V-REX: Benchmarking Exploratory Visual Reasoning via Chain-of-Questions
Dec 12, 2025While many vision-language models (VLMs) are developed to answer well-defined, straightforward questions with highly specified targets, as in most benchmarks, they often struggle in practice with complex open-ended tasks, which usually require multiple rounds of exploration and reasoning in the visual space. Such visual thinking paths not only provide step-by-step exploration and verification as an AI detective but also produce better interpretations of the final answers. However, these paths are challenging to evaluate due to the large exploration space of intermediate steps. To bridge the gap, we develop an evaluation suite, ``Visual Reasoning with multi-step EXploration (V-REX)'', which is composed of a benchmark of challenging visual reasoning tasks requiring native multi-step exploration and an evaluation protocol. V-REX covers rich application scenarios across diverse domains. V-REX casts the multi-step exploratory reasoning into a Chain-of-Questions (CoQ) and disentangles VLMs' capability to (1) Planning: breaking down an open-ended task by selecting a chain of exploratory questions; and (2) Following: answering curated CoQ sequentially to collect information for deriving the final answer. By curating finite options of questions and answers per step, V-REX achieves a reliable quantitative and fine-grained analysis of the intermediate steps. By assessing SOTA proprietary and open-sourced VLMs, we reveal consistent scaling trends, significant differences between planning and following abilities, and substantial room for improvement in multi-step exploratory reasoning.
RoboTidy : A 3D Gaussian Splatting Household Tidying Benchmark for Embodied Navigation and Action
Nov 19, 2025Household tidying is an important application area, yet current benchmarks neither model user preferences nor support mobility, and they generalize poorly, making it hard to comprehensively assess integrated language-to-action capabilities. To address this, we propose RoboTidy, a unified benchmark for language-guided household tidying that supports Vision-Language-Action (VLA) and Vision-Language-Navigation (VLN) training and evaluation. RoboTidy provides 500 photorealistic 3D Gaussian Splatting (3DGS) household scenes (covering 500 objects and containers) with collisions, formulates tidying as an "Action (Object, Container)" list, and supplies 6.4k high-quality manipulation demonstration trajectories and 1.5k naviagtion trajectories to support both few-shot and large-scale training. We also deploy RoboTidy in the real world for object tidying, establishing an end-to-end benchmark for household tidying. RoboTidy offers a scalable platform and bridges a key gap in embodied AI by enabling holistic and realistic evaluation of language-guided robots.
TCM-5CEval: Extended Deep Evaluation Benchmark for LLM's Comprehensive Clinical Research Competence in Traditional Chinese Medicine
Nov 17, 2025Large language models (LLMs) have demonstrated exceptional capabilities in general domains, yet their application in highly specialized and culturally-rich fields like Traditional Chinese Medicine (TCM) requires rigorous and nuanced evaluation. Building upon prior foundational work such as TCM-3CEval, which highlighted systemic knowledge gaps and the importance of cultural-contextual alignment, we introduce TCM-5CEval, a more granular and comprehensive benchmark. TCM-5CEval is designed to assess LLMs across five critical dimensions: (1) Core Knowledge (TCM-Exam), (2) Classical Literacy (TCM-LitQA), (3) Clinical Decision-making (TCM-MRCD), (4) Chinese Materia Medica (TCM-CMM), and (5) Clinical Non-pharmacological Therapy (TCM-ClinNPT). We conducted a thorough evaluation of fifteen prominent LLMs, revealing significant performance disparities and identifying top-performing models like deepseek\_r1 and gemini\_2\_5\_pro. Our findings show that while models exhibit proficiency in recalling foundational knowledge, they struggle with the interpretative complexities of classical texts. Critically, permutation-based consistency testing reveals widespread fragilities in model inference. All evaluated models, including the highest-scoring ones, displayed a substantial performance degradation when faced with varied question option ordering, indicating a pervasive sensitivity to positional bias and a lack of robust understanding. TCM-5CEval not only provides a more detailed diagnostic tool for LLM capabilities in TCM but aldso exposes fundamental weaknesses in their reasoning stability. To promote further research and standardized comparison, TCM-5CEval has been uploaded to the Medbench platform, joining its predecessor in the "In-depth Challenge for Comprehensive TCM Abilities" special track.
Learning to Fast Unrank in Collaborative Filtering Recommendation
Nov 10, 2025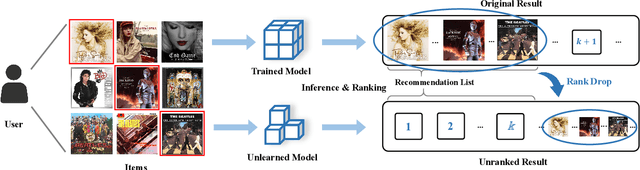
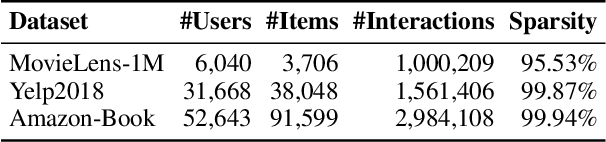
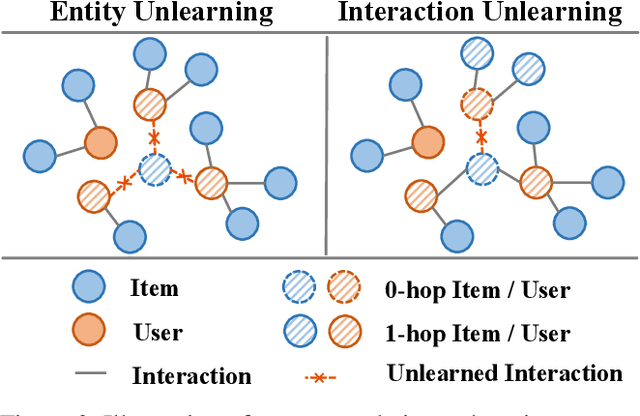
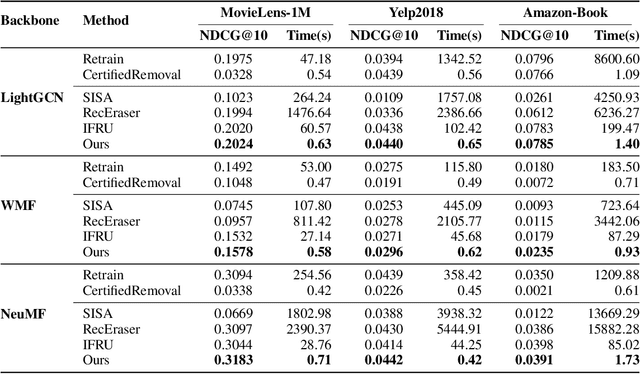
Modern data-driven recommendation systems risk memorizing sensitive user behavioral patterns, raising privacy concerns. Existing recommendation unlearning methods, while capable of removing target data influence, suffer from inefficient unlearning speed and degraded performance, failing to meet real-time unlearning demands. Considering the ranking-oriented nature of recommendation systems, we present unranking, the process of reducing the ranking positions of target items while ensuring the formal guarantees of recommendation unlearning. To achieve efficient unranking, we propose Learning to Fast Unrank in Collaborative Filtering Recommendation (L2UnRank), which operates through three key stages: (a) identifying the influenced scope via interaction-based p-hop propagation, (b) computing structural and semantic influences for entities within this scope, and (c) performing efficient, ranking-aware parameter updates guided by influence information. Extensive experiments across multiple datasets and backbone models demonstrate L2UnRank's model-agnostic nature, achieving state-of-the-art unranking effectiveness and maintaining recommendation quality comparable to retraining, while also delivering a 50x speedup over existing methods. Codes are available at https://github.com/Juniper42/L2UnRank.