 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Translation: Do LVLM Judges Generalize Across Languages?
Apr 21, 2026Automatic evaluators such as reward models play a central role in the alignment and evaluation of large vision-language models (LVLMs). Despite their growing importance, these evaluators are almost exclusively assessed on English-centric benchmarks, leaving open the question of how well these evaluators generalize across languages. To answer this question, we introduce MM-JudgeBench, the first large-scale benchmark for multilingual and multimodal judge model evaluation, which includes over 60K pairwise preference instances spanning 25 typologically diverse languages. MM-JudgeBench integrates two complementary subsets: a general vision-language preference evaluation subset extending VL-RewardBench, and a chart-centric visual-text reasoning subset derived from OpenCQA, enabling systematic analysis of reward models (i.e., LVLM judges) across diverse settings. We additionally release a multilingual training set derived from MM-RewardBench, disjoint from our evaluation data, to support domain adaptation. By evaluating 22 LVLMs (15 open-source, 7 proprietary), we uncover substantial cross-lingual performance variance in our proposed benchmark. Our analysis further shows that model size and architecture are poor predictors of multilingual robustness, and that even state-of-the-art LVLM judges exhibit inconsistent behavior across languages. Together, these findings expose fundamental limitations of current reward modeling and underscore the necessity of multilingual, multimodal benchmarks for developing reliable automated evaluators.
Assessing the Quality of Mental Health Support in LLM Responses through Multi-Attribute Human Evaluation
Jan 26, 2026The escalating global mental health crisis, marked by persistent treatment gaps, availability, and a shortage of qualified therapists, positions Large Language Models (LLMs) as a promising avenue for scalable support. While LLMs offer potential for accessible emotional assistance, their reliability, therapeutic relevance, and alignment with human standards remain challenging to address. This paper introduces a human-grounded evaluation methodology designed to assess LLM generated responses in therapeutic dialogue. Our approach involved curating a dataset of 500 mental health conversations from datasets with real-world scenario questions and evaluating the responses generated by nine diverse LLMs, including closed source and open source models. More specifically, these responses were evaluated by two psychiatric trained experts, who independently rated each on a 5 point Likert scale across a comprehensive 6 attribute rubric. This rubric captures Cognitive Support and Affective Resonance, providing a multidimensional perspective on therapeutic quality. Our analysis reveals that LLMs provide strong cognitive reliability by producing safe, coherent, and clinically appropriate information, but they demonstrate unstable affective alignment. Although closed source models (e.g., GPT-4o) offer balanced therapeutic responses, open source models show greater variability and emotional flatness. We reveal a persistent cognitive-affective gap and highlight the need for failure aware, clinically grounded evaluation frameworks that prioritize relational sensitivity alongside informational accuracy in mental health oriented LLMs. We advocate for balanced evaluation protocols with human in the loop that center on therapeutic sensitivity and provide a framework to guide the responsible design and clinical oversight of mental health oriented conversational AI.
Learning to Fast Unrank in Collaborative Filtering Recommendation
Nov 10, 2025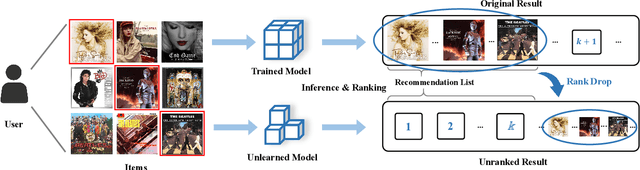
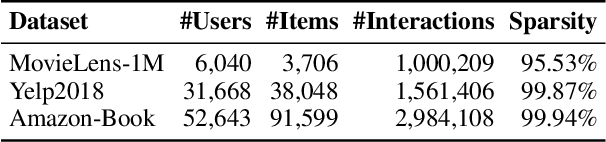
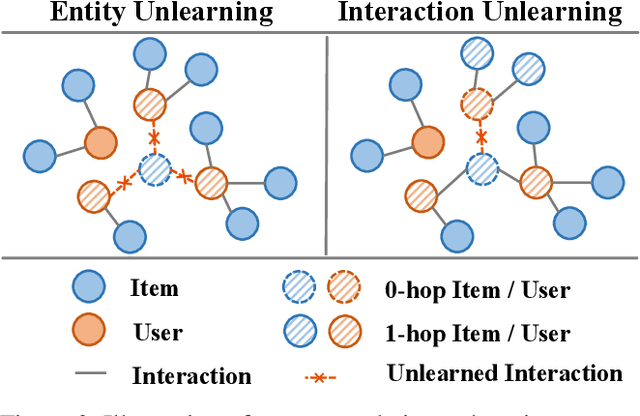
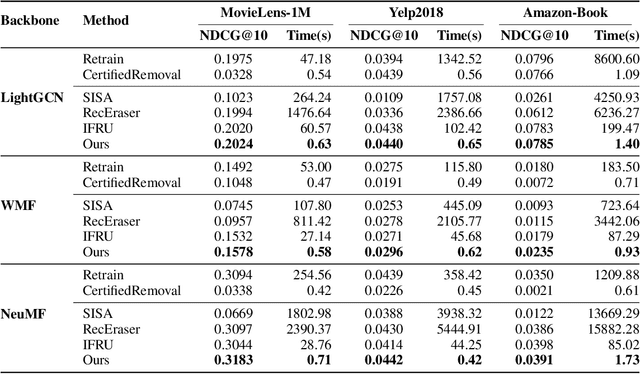
Modern data-driven recommendation systems risk memorizing sensitive user behavioral patterns, raising privacy concerns. Existing recommendation unlearning methods, while capable of removing target data influence, suffer from inefficient unlearning speed and degraded performance, failing to meet real-time unlearning demands. Considering the ranking-oriented nature of recommendation systems, we present unranking, the process of reducing the ranking positions of target items while ensuring the formal guarantees of recommendation unlearning. To achieve efficient unranking, we propose Learning to Fast Unrank in Collaborative Filtering Recommendation (L2UnRank), which operates through three key stages: (a) identifying the influenced scope via interaction-based p-hop propagation, (b) computing structural and semantic influences for entities within this scope, and (c) performing efficient, ranking-aware parameter updates guided by influence information. Extensive experiments across multiple datasets and backbone models demonstrate L2UnRank's model-agnostic nature, achieving state-of-the-art unranking effectiveness and maintaining recommendation quality comparable to retraining, while also delivering a 50x speedup over existing methods. Codes are available at https://github.com/Juniper42/L2UnRank.
When Can We Trust LLMs in Mental Health? Large-Scale Benchmarks for Reliable LLM Evaluation
Oct 21, 2025Evaluating Large Language Models (LLMs) for mental health support is challenging due to the emotionally and cognitively complex nature of therapeutic dialogue. Existing benchmarks are limited in scale, reliability, often relying on synthetic or social media data, and lack frameworks to assess when automated judges can be trusted. To address the need for large-scale dialogue datasets and judge reliability assessment, we introduce two benchmarks that provide a framework for generation and evaluation. MentalBench-100k consolidates 10,000 one-turn conversations from three real scenarios datasets, each paired with nine LLM-generated responses, yielding 100,000 response pairs. MentalAlign-70k}reframes evaluation by comparing four high-performing LLM judges with human experts across 70,000 ratings on seven attributes, grouped into Cognitive Support Score (CSS) and Affective Resonance Score (ARS). We then employ the Affective Cognitive Agreement Framework, a statistical methodology using intraclass correlation coefficients (ICC) with confidence intervals to quantify agreement, consistency, and bias between LLM judges and human experts. Our analysis reveals systematic inflation by LLM judges, strong reliability for cognitive attributes such as guidance and informativeness, reduced precision for empathy, and some unreliability in safety and relevance. Our contributions establish new methodological and empirical foundations for reliable, large-scale evaluation of LLMs in mental health. We release the benchmarks and codes at: https://github.com/abeerbadawi/MentalBench/
Judging the Judges: Can Large Vision-Language Models Fairly Evaluate Chart Comprehension and Reasoning?
May 13, 2025Charts are ubiquitous as they help people understand and reason with data. Recently, various downstream tasks, such as chart question answering, chart2text, and fact-checking, have emerged. Large Vision-Language Models (LVLMs) show promise in tackling these tasks, but their evaluation is costly and time-consuming, limiting real-world deployment. While using LVLMs as judges to assess the chart comprehension capabilities of other LVLMs could streamline evaluation processes, challenges like proprietary datasets, restricted access to powerful models, and evaluation costs hinder their adoption in industrial settings. To this end, we present a comprehensive evaluation of 13 open-source LVLMs as judges for diverse chart comprehension and reasoning tasks. We design both pairwise and pointwise evaluation tasks covering criteria like factual correctness, informativeness, and relevancy. Additionally, we analyze LVLM judges based on format adherence, positional consistency, length bias, and instruction-following. We focus on cost-effective LVLMs (<10B parameters) suitable for both research and commercial use, following a standardized evaluation protocol and rubric to measure the LVLM judge's accuracy. Experimental results reveal notable variability: while some open LVLM judges achieve GPT-4-level evaluation performance (about 80% agreement with GPT-4 judgments), others struggle (below ~10% agreement). Our findings highlight that state-of-the-art open-source LVLMs can serve as cost-effective automatic evaluators for chart-related tasks, though biases such as positional preference and length bias persist.
A Systematic Survey and Critical Review on Evaluating Large Language Models: Challenges, Limitations, and Recommendations
Jul 04, 2024



Large Language Models (LLMs) have recently gained significant attention due to their remarkable capabilities in performing diverse tasks across various domains. However, a thorough evaluation of these models is crucial before deploying them in real-world applications to ensure they produce reliable performance. Despite the well-established importance of evaluating LLMs in the community, the complexity of the evaluation process has led to varied evaluation setups, causing inconsistencies in findings and interpretations. To address this, we systematically review the primary challenges and limitations causing these inconsistencies and unreliable evaluations in various steps of LLM evaluation. Based on our critical review, we present our perspectives and recommendations to ensure LLM evaluations are reproducible, reliable, and robust.
Exploring ChatGPT for Next-generation Information Retrieval: Opportunities and Challenges
Feb 17, 2024

The rapid advancement of artificial intelligence (AI) has highlighted ChatGPT as a pivotal technology in the field of information retrieval (IR). Distinguished from its predecessors, ChatGPT offers significant benefits that have attracted the attention of both the industry and academic communities. While some view ChatGPT as a groundbreaking innovation, others attribute its success to the effective integration of product development and market strategies. The emergence of ChatGPT, alongside GPT-4, marks a new phase in Generative AI, generating content that is distinct from training examples and exceeding the capabilities of the prior GPT-3 model by OpenAI. Unlike the traditional supervised learning approach in IR tasks, ChatGPT challenges existing paradigms, bringing forth new challenges and opportunities regarding text quality assurance, model bias, and efficiency. This paper seeks to examine the impact of ChatGPT on IR tasks and offer insights into its potential future developments.
* Survey Paper
A Comprehensive Evaluation of Large Language Models on Benchmark Biomedical Text Processing Tasks
Oct 10, 2023



Recently, Large Language Models (LLM) have demonstrated impressive capability to solve a wide range of tasks. However, despite their success across various tasks, no prior work has investigated their capability in the biomedical domain yet. To this end, this paper aims to evaluate the performance of LLMs on benchmark biomedical tasks. For this purpose, we conduct a comprehensive evaluation of 4 popular LLMs in 6 diverse biomedical tasks across 26 datasets. To the best of our knowledge, this is the first work that conducts an extensive evaluation and comparison of various LLMs in the biomedical domain. Interestingly, we find based on our evaluation that in biomedical datasets that have smaller training sets, zero-shot LLMs even outperform the current state-of-the-art fine-tuned biomedical models. This suggests that pretraining on large text corpora makes LLMs quite specialized even in the biomedical domain. We also find that not a single LLM can outperform other LLMs in all tasks, with the performance of different LLMs may vary depending on the task. While their performance is still quite poor in comparison to the biomedical models that were fine-tuned on large training sets, our findings demonstrate that LLMs have the potential to be a valuable tool for various biomedical tasks that lack large annotated data.
Evaluation of ChatGPT on Biomedical Tasks: A Zero-Shot Comparison with Fine-Tuned Generative Transformers
Jun 07, 2023



ChatGPT is a large language model developed by OpenAI. Despite its impressive performance across various tasks, no prior work has investigated its capability in the biomedical domain yet. To this end, this paper aims to evaluate the performance of ChatGPT on various benchmark biomedical tasks, such as relation extraction, document classification, question answering, and summarization. To the best of our knowledge, this is the first work that conducts an extensive evaluation of ChatGPT in the biomedical domain. Interestingly, we find based on our evaluation that in biomedical datasets that have smaller training sets, zero-shot ChatGPT even outperforms the state-of-the-art fine-tuned generative transformer models, such as BioGPT and BioBART. This suggests that ChatGPT's pre-training on large text corpora makes it quite specialized even in the biomedical domain. Our findings demonstrate that ChatGPT has the potential to be a valuable tool for various tasks in the biomedical domain that lack large annotated data.
Extending Isolation Forest for Anomaly Detection in Big Data via K-Means
Apr 27, 2021

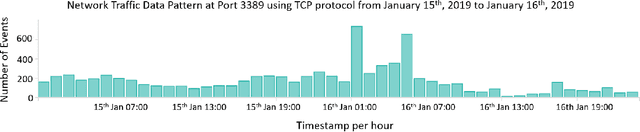

Industrial Information Technology (IT) infrastructures are often vulnerable to cyberattacks. To ensure security to the computer systems in an industrial environment, it is required to build effective intrusion detection systems to monitor the cyber-physical systems (e.g., computer networks) in the industry for malicious activities. This paper aims to build such intrusion detection systems to protect the computer networks from cyberattacks. More specifically, we propose a novel unsupervised machine learning approach that combines the K-Means algorithm with the Isolation Forest for anomaly detection in industrial big data scenarios. Since our objective is to build the intrusion detection system for the big data scenario in the industrial domain, we utilize the Apache Spark framework to implement our proposed model which was trained in large network traffic data (about 123 million instances of network traffic) stored in Elasticsearch. Moreover, we evaluate our proposed model on the live streaming data and find that our proposed system can be used for real-time anomaly detection in the industrial setup. In addition, we address different challenges that we face while training our model on large datasets and explicitly describe how these issues were resolved. Based on our empirical evaluation in different use-cases for anomaly detection in real-world network traffic data, we observe that our proposed system is effective to detect anomalies in big data scenarios. Finally, we evaluate our proposed model on several academic datasets to compare with other models and find that it provides comparable performance with other state-of-the-art approaches.