 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-130B: An Open Bilingual Pre-trained Model
Oct 05, 2022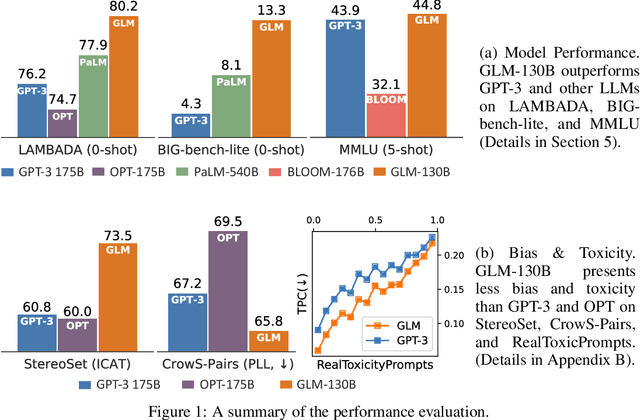
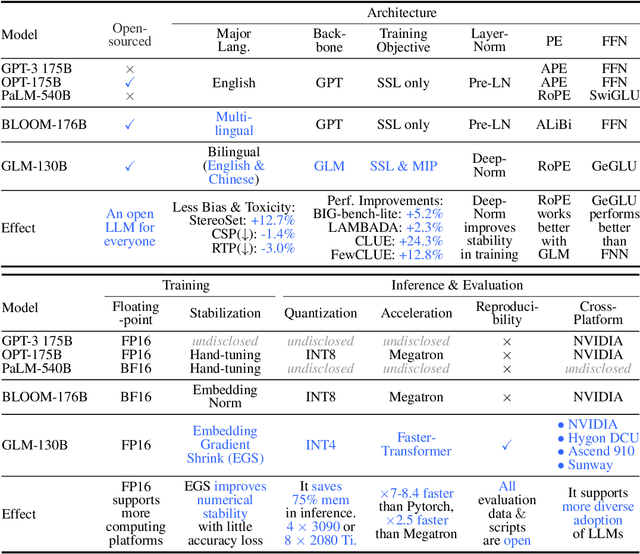

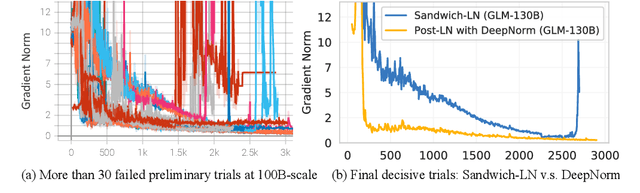
We introduce GLM-130B, a bilingual (English and Chinese) pre-trained language model with 130 billion parameters. It is an attempt to open-source a 100B-scale model at least as good as GPT-3 and unveil how models of such a scale can be successfully pre-trained. Over the course of this effort, we face numerous unexpected technical and engineering challenges, particularly on loss spikes and disconvergence. In this paper, we introduce the training process of GLM-130B including its design choices, training strategies for both efficiency and stability, and engineering efforts. The resultant GLM-130B model offers significant outperformance over GPT-3 175B on a wide range of popular English benchmarks while the performance advantage is not observed in OPT-175B and BLOOM-176B. It also consistently and significantly outperforms ERNIE TITAN 3.0 260B -- the largest Chinese language model -- across related benchmarks. Finally, we leverage a unique scaling property of GLM-130B to reach INT4 quantization, without quantization aware training and with almost no performance loss, making it the first among 100B-scale models. More importantly, the property allows its effective inference on 4$\times$RTX 3090 (24G) or 8$\times$RTX 2080 Ti (11G) GPUs, the most ever affordable GPUs required for using 100B-scale models. The GLM-130B model weights are publicly accessible and its code, training logs, related toolkit, and lessons learned are open-sourced at https://github.com/THUDM/GLM-130B .
Robust Information Bottleneck for Task-Oriented Communication with Digital Modulation
Sep 21, 2022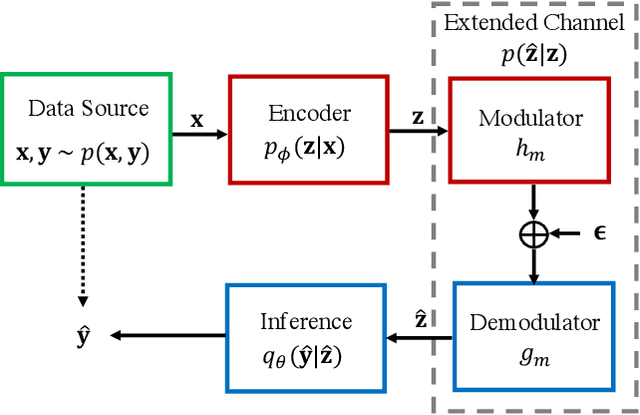
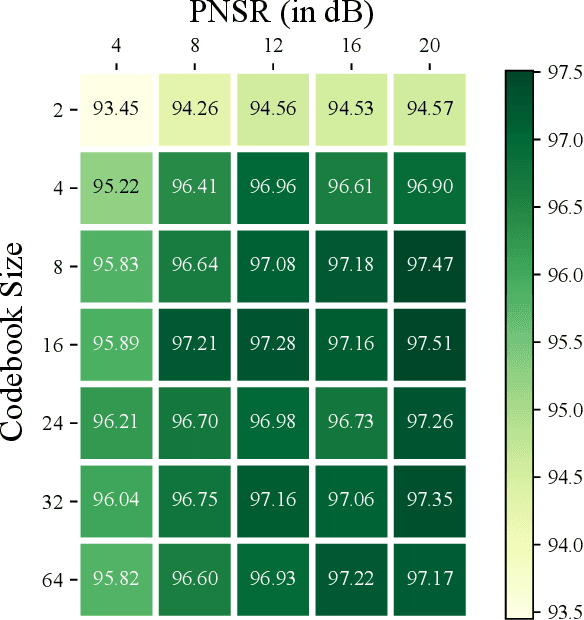
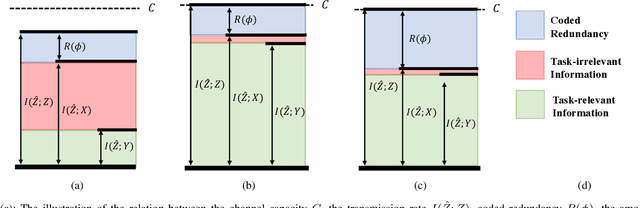
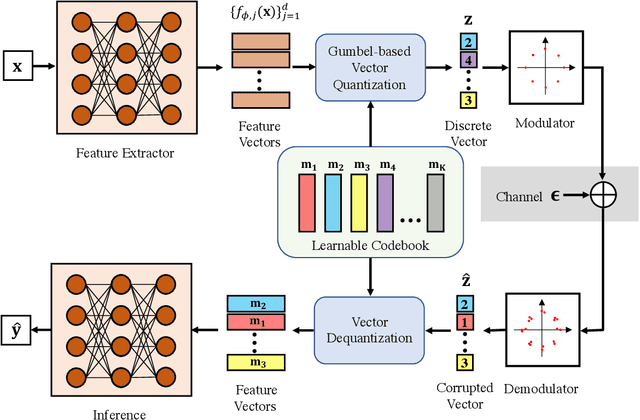
Task-oriented communications, mostly using learning-based joint source-channel coding (JSCC), aim to design a communication-efficient edge inference system by transmitting task-relevant information to the receiver. However, only transmitting task-relevant information without introducing any redundancy may cause robustness issues in learning due to the channel variations, and the JSCC which directly maps the source data into continuous channel input symbols poses compatibility issues on existing digital communication systems. In this paper, we address these two issues by first investigating the inherent tradeoff between the informativeness of the encoded representations and the robustness to information distortion in the received representations, and then propose a task-oriented communication scheme with digital modulation, named discrete task-oriented JSCC (DT-JSCC), where the transmitter encodes the features into a discrete representation and transmits it to the receiver with the digital modulation scheme. In the DT-JSCC scheme, we develop a robust encoding framework, named robust information bottleneck (RIB), to improve the communication robustness to the channel variations, and derive a tractable variational upper bound of the RIB objective function using the variational approximation to overcome the computational intractability of mutual information. The experimental results demonstrate that the proposed DT-JSCC achieves better inference performance than the baseline methods with low communication latency, and exhibits robustness to channel variations due to the applied RIB framework.
Intelligent Blockchain-based Edge Computing via Deep Reinforcement Learning: Solutions and Challenges
Jun 17, 2022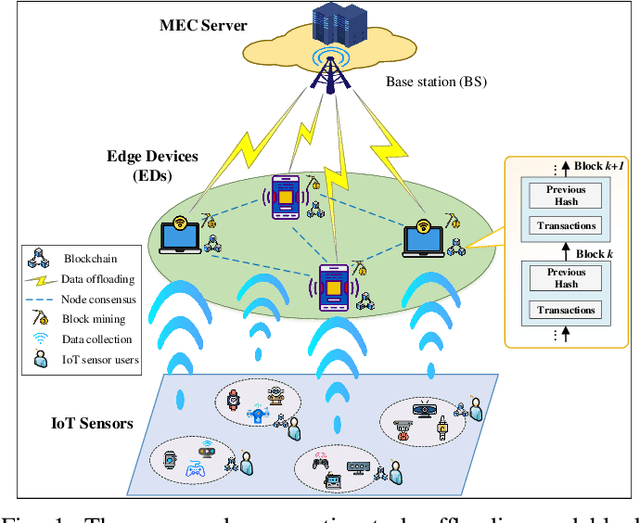
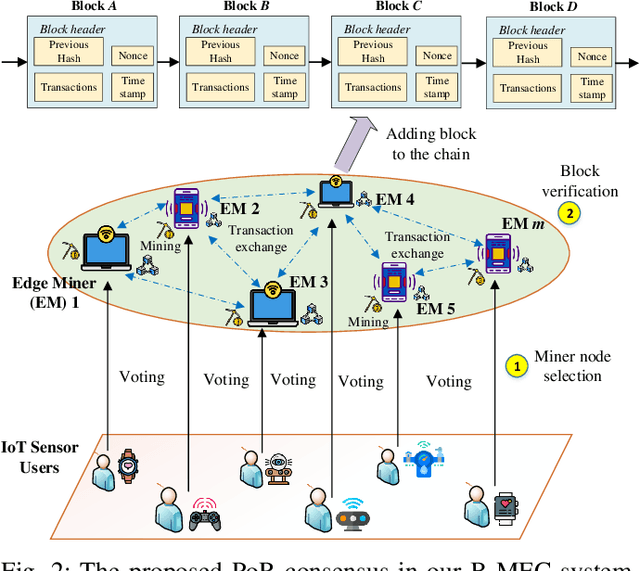
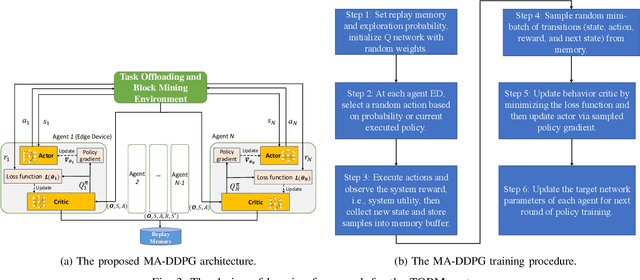
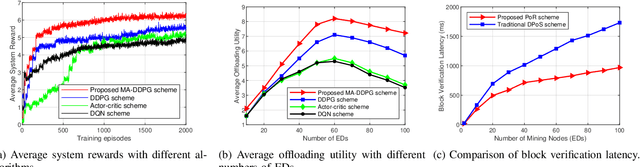
The convergence of mobile edge computing (MEC) and blockchain is transforming the current computing services in wireless Internet-of-Things networks, by enabling task offloading with security enhancement based on blockchain mining. Yet the existing approaches for these enabling technologies are isolated, providing only tailored solutions for specific services and scenarios. To fill this gap, we propose a novel cooperative task offloading and blockchain mining (TOBM) scheme for a blockchain-based MEC system, where each edge device not only handles computation tasks but also deals with block mining for improving system utility. To address the latency issues caused by the blockchain operation in MEC, we develop a new Proof-of-Reputation consensus mechanism based on a lightweight block verification strategy. To accommodate the highly dynamic environment and high-dimensional system state space, we apply a novel distributed deep reinforcement learning-based approach by using a multi-agent deep deterministic policy gradient algorithm. Experimental results demonstrate the superior performance of the proposed TOBM scheme in terms of enhanced system reward, improved offloading utility with lower blockchain mining latency, and better system utility, compared to the existing cooperative and non-cooperative schemes. The paper concludes with key technical challenges and possible directions for future blockchain-based MEC research.
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
May 29, 2022
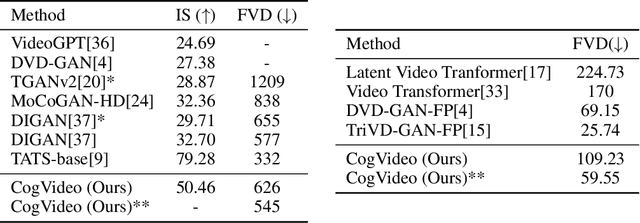
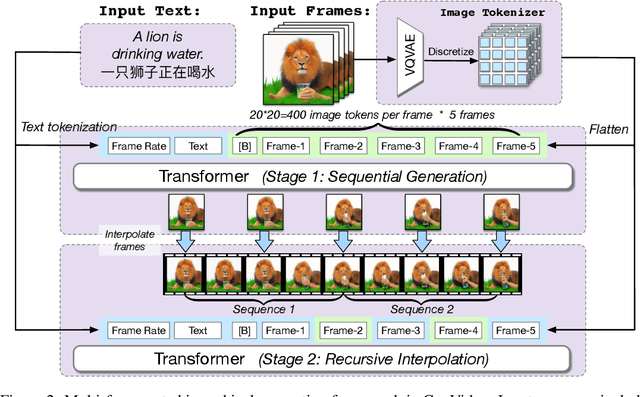

Large-scale pretrained transformers have created milestones in text (GPT-3) and text-to-image (DALL-E and CogView) generation. Its application to video generation is still facing many challenges: The potential huge computation cost makes the training from scratch unaffordable; The scarcity and weak relevance of text-video datasets hinder the model understanding complex movement semantics. In this work, we present 9B-parameter transformer CogVideo, trained by inheriting a pretrained text-to-image model, CogView2. We also propose multi-frame-rate hierarchical training strategy to better align text and video clips. As (probably) the first open-source large-scale pretrained text-to-video model, CogVideo outperforms all publicly available models at a large margin in machine and human evaluations.
Rethinking the Setting of Semi-supervised Learning on Graphs
May 28, 2022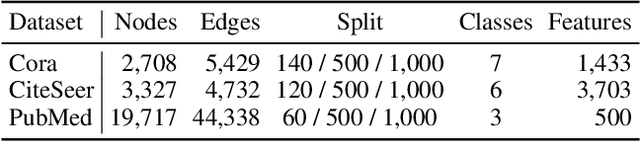
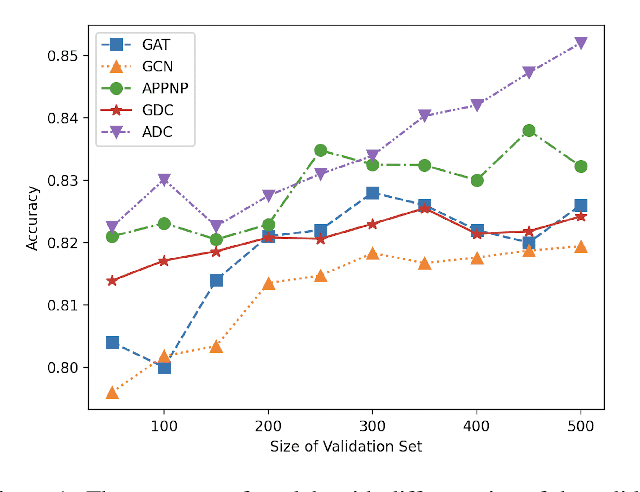
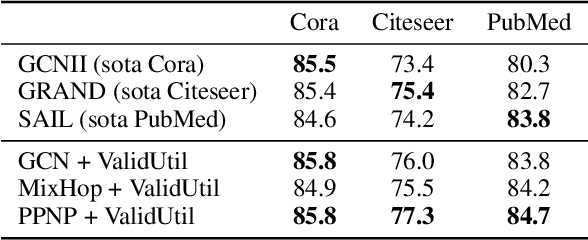
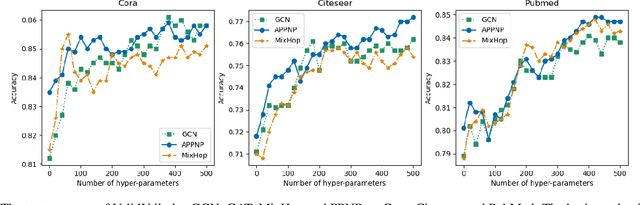
We argue that the present setting of semisupervised learning on graphs may result in unfair comparisons, due to its potential risk of over-tuning hyper-parameters for models. In this paper, we highlight the significant influence of tuning hyper-parameters, which leverages the label information in the validation set to improve the performance. To explore the limit of over-tuning hyperparameters, we propose ValidUtil, an approach to fully utilize the label information in the validation set through an extra group of hyper-parameters. With ValidUtil, even GCN can easily get high accuracy of 85.8% on Cora. To avoid over-tuning, we merge the training set and the validation set and construct an i.i.d. graph benchmark (IGB) consisting of 4 datasets. Each dataset contains 100 i.i.d. graphs sampled from a large graph to reduce the evaluation variance. Our experiments suggest that IGB is a more stable benchmark than previous datasets for semisupervised learning on graphs.
CogView2: Faster and Better Text-to-Image Generation via Hierarchical Transformers
Apr 28, 2022
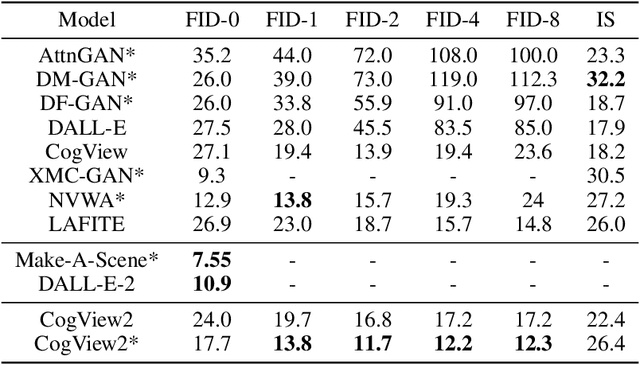
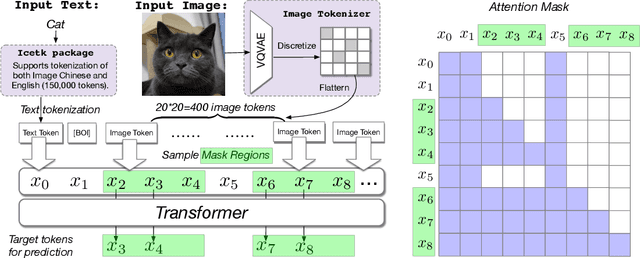

The development of the transformer-based text-to-image models are impeded by its slow generation and complexity for high-resolution images. In this work, we put forward a solution based on hierarchical transformers and local parallel auto-regressive generation. We pretrain a 6B-parameter transformer with a simple and flexible self-supervised task, Cross-modal general language model (CogLM), and finetune it for fast super-resolution. The new text-to-image system, CogView2, shows very competitive generation compared to concurrent state-of-the-art DALL-E-2, and naturally supports interactive text-guided editing on images.
A Roadmap for Big Model
Apr 02, 2022



With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.
Vertical Federated Learning: Challenges, Methodologies and Experiments
Feb 09, 2022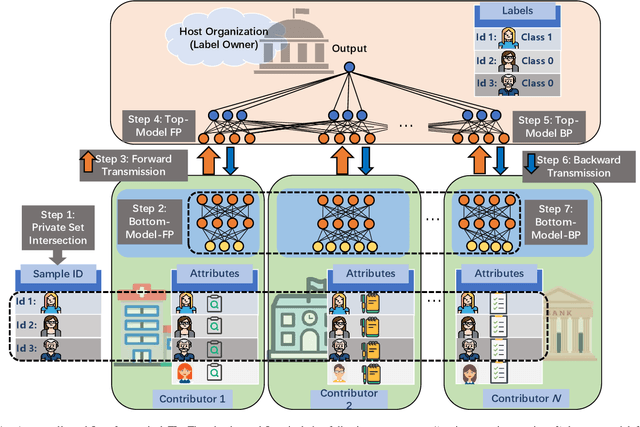
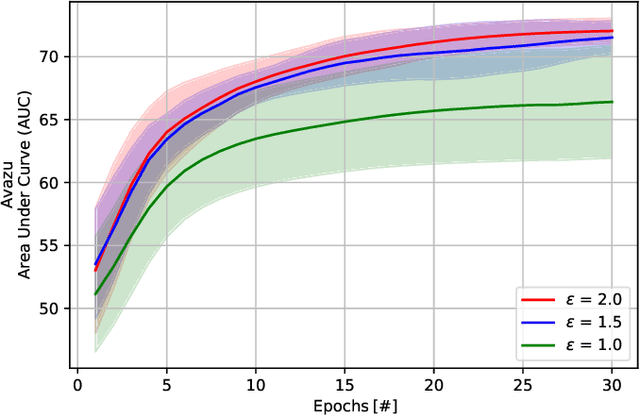
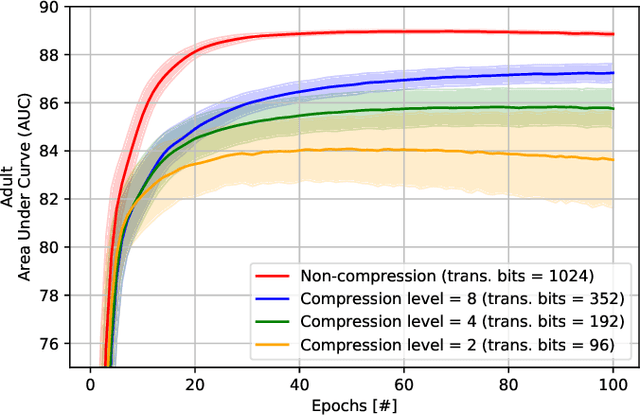
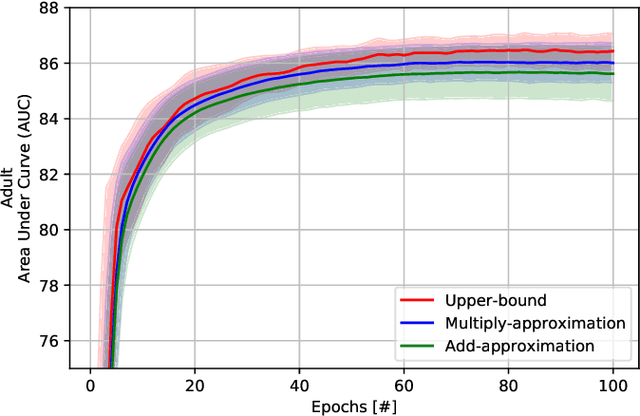
Recently, federated learning (FL) has emerged as a promising distributed machine learning (ML) technology, owing to the advancing computational and sensing capacities of end-user devices, however with the increasing concerns on users' privacy. As a special architecture in FL, vertical FL (VFL) is capable of constructing a hyper ML model by embracing sub-models from different clients. These sub-models are trained locally by vertically partitioned data with distinct attributes. Therefore, the design of VFL is fundamentally different from that of conventional FL, raising new and unique research issues. In this paper, we aim to discuss key challenges in VFL with effective solutions, and conduct experiments on real-life datasets to shed light on these issues. Specifically, we first propose a general framework on VFL, and highlight the key differences between VFL and conventional FL. Then, we discuss research challenges rooted in VFL systems under four aspects, i.e., security and privacy risks, expensive computation and communication costs, possible structural damage caused by model splitting, and system heterogeneity. Afterwards, we develop solutions to addressing the aforementioned challenges, and conduct extensive experiments to showcase the effectiveness of our proposed solutions.
A Wearable ECG Monitor for Deep Learning Based Real-Time Cardiovascular Disease Detection
Jan 25, 2022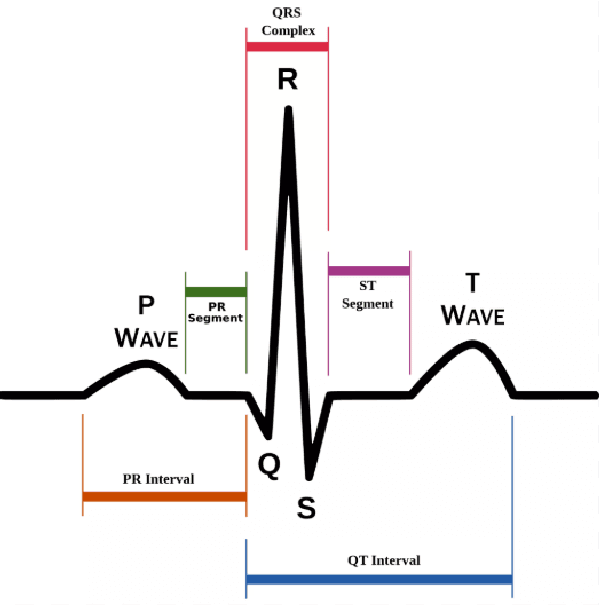

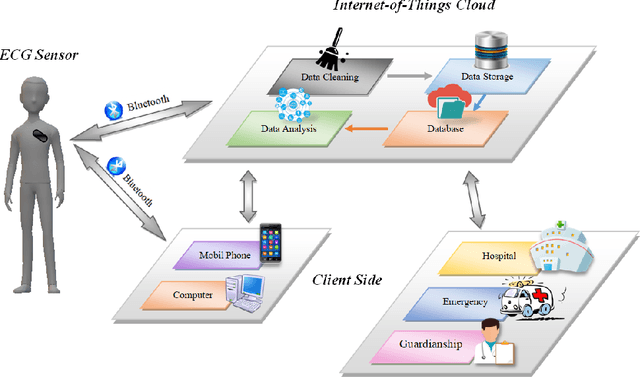
Cardiovascular disease has become one of the most significant threats endangering human life and health. Recently, Electrocardiogram (ECG) monitoring has been transformed into remote cardiac monitoring by Holter surveillance. However, the widely used Holter can bring a great deal of discomfort and inconvenience to the individuals who carry them. We developed a new wireless ECG patch in this work and applied a deep learning framework based on the Convolutional Neural Network (CNN) and Long Short-term Memory (LSTM) models. However, we find that the models using the existing techniques are not able to differentiate two main heartbeat types (Supraventricular premature beat and Atrial fibrillation) in our newly obtained dataset, resulting in low accuracy of 58.0 %. We proposed a semi-supervised method to process the badly labelled data samples with using the confidence-level-based training. The experiment results conclude that the proposed method can approach an average accuracy of 90.2 %, i.e., 5.4 % higher than the accuracy of conventional ECG classification methods.
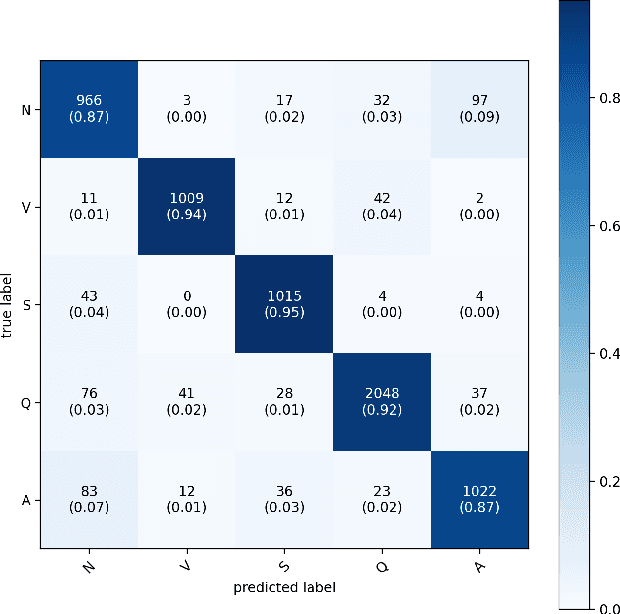
Negative-ResNet: Noisy Ambulatory Electrocardiogram Signal Classification Scheme
Jan 25, 2022
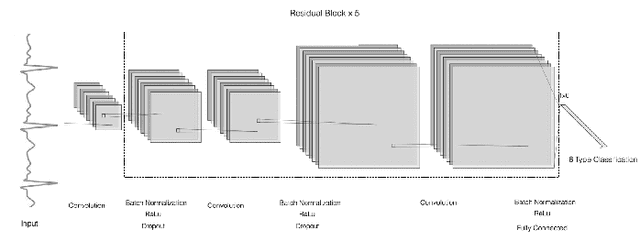
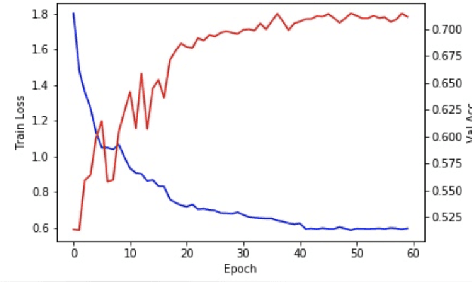
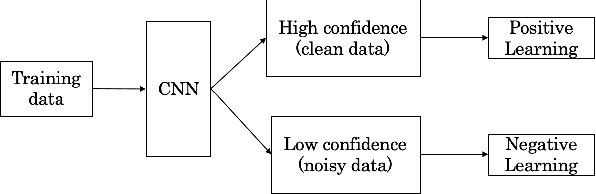
With recently successful applications of deep learning in computer vision and general signal processing, deep learning has shown many unique advantages in medical signal processing. However, data labelling quality has become one of the most significant issues for AI applications, especially when it requires domain knowledge (e.g. medical image labelling). In addition, there might be noisy labels in practical datasets, which might impair the training process of neural networks. In this work, we propose a semi-supervised algorithm for training data samples with noisy labels by performing selected Positive Learning (PL) and Negative Learning (NL). To verify the effectiveness of the proposed scheme, we designed a portable ECG patch -- iRealCare -- and applied the algorithm on a real-life dataset. Our experimental results show that we can achieve an accuracy of 91.0 %, which is 6.2 % higher than a normal training process with ResNet. There are 65 patients in our dataset and we randomly picked 2 patients to perform validation.