 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoGLM: Autonomous Foundation Agents for GUIs
Oct 28, 2024



We present AutoGLM, a new series in the ChatGLM family, designed to serve as foundation agents for autonomous control of digital devices through Graphical User Interfaces (GUIs). While foundation models excel at acquiring human knowledge, they often struggle with decision-making in dynamic real-world environments, limiting their progress toward artificial general intelligence. This limitation underscores the importance of developing foundation agents capable of learning through autonomous environmental interactions by reinforcing existing models. Focusing on Web Browser and Phone as representative GUI scenarios, we have developed AutoGLM as a practical foundation agent system for real-world GUI interactions. Our approach integrates a comprehensive suite of techniques and infrastructures to create deployable agent systems suitable for user delivery. Through this development, we have derived two key insights: First, the design of an appropriate "intermediate interface" for GUI control is crucial, enabling the separation of planning and grounding behaviors, which require distinct optimization for flexibility and accuracy respectively. Second, we have developed a novel progressive training framework that enables self-evolving online curriculum reinforcement learning for AutoGLM. Our evaluations demonstrate AutoGLM's effectiveness across multiple domains. For web browsing, AutoGLM achieves a 55.2% success rate on VAB-WebArena-Lite (improving to 59.1% with a second attempt) and 96.2% on OpenTable evaluation tasks. In Android device control, AutoGLM attains a 36.2% success rate on AndroidLab (VAB-Mobile) and 89.7% on common tasks in popular Chinese APPs.
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Jun 18, 2024



We introduce ChatGLM, an evolving family of large language models that we have been developing over time. This report primarily focuses on the GLM-4 language series, which includes GLM-4, GLM-4-Air, and GLM-4-9B. They represent our most capable models that are trained with all the insights and lessons gained from the preceding three generations of ChatGLM. To date, the GLM-4 models are pre-trained on ten trillions of tokens mostly in Chinese and English, along with a small set of corpus from 24 languages, and aligned primarily for Chinese and English usage. The high-quality alignment is achieved via a multi-stage post-training process, which involves supervised fine-tuning and learning from human feedback. Evaluations show that GLM-4 1) closely rivals or outperforms GPT-4 in terms of general metrics such as MMLU, GSM8K, MATH, BBH, GPQA, and HumanEval, 2) gets close to GPT-4-Turbo in instruction following as measured by IFEval, 3) matches GPT-4 Turbo (128K) and Claude 3 for long context tasks, and 4) outperforms GPT-4 in Chinese alignments as measured by AlignBench. The GLM-4 All Tools model is further aligned to understand user intent and autonomously decide when and which tool(s) touse -- including web browser, Python interpreter, text-to-image model, and user-defined functions -- to effectively complete complex tasks. In practical applications, it matches and even surpasses GPT-4 All Tools in tasks like accessing online information via web browsing and solving math problems using Python interpreter. Over the course, we have open-sourced a series of models, including ChatGLM-6B (three generations), GLM-4-9B (128K, 1M), GLM-4V-9B, WebGLM, and CodeGeeX, attracting over 10 million downloads on Hugging face in the year 2023 alone. The open models can be accessed through https://github.com/THUDM and https://huggingface.co/THUDM.
ChatGLM-Math: Improving Math Problem-Solving in Large Language Models with a Self-Critique Pipeline
Apr 03, 2024



Large language models (LLMs) have shown excellent mastering of human language, but still struggle in real-world applications that require mathematical problem-solving. While many strategies and datasets to enhance LLMs' mathematics are developed, it remains a challenge to simultaneously maintain and improve both language and mathematical capabilities in deployed LLM systems.In this work, we tailor the Self-Critique pipeline, which addresses the challenge in the feedback learning stage of LLM alignment. We first train a general Math-Critique model from the LLM itself to provide feedback signals. Then, we sequentially employ rejective fine-tuning and direct preference optimization over the LLM's own generations for data collection. Based on ChatGLM3-32B, we conduct a series of experiments on both academic and our newly created challenging dataset, MathUserEval. Results show that our pipeline significantly enhances the LLM's mathematical problem-solving while still improving its language ability, outperforming LLMs that could be two times larger. Related techniques have been deployed to ChatGLM\footnote{\url{https://chatglm.cn}}, an online serving LLM. Related evaluation dataset and scripts are released at \url{https://github.com/THUDM/ChatGLM-Math}.
Boosting Physical Layer Black-Box Attacks with Semantic Adversaries in Semantic Communications
Mar 30, 2023



End-to-end semantic communication (ESC) system is able to improve communication efficiency by only transmitting the semantics of the input rather than raw bits. Although promising, ESC has also been shown susceptible to the crafted physical layer adversarial perturbations due to the openness of wireless channels and the sensitivity of neural models. Previous works focus more on the physical layer white-box attacks, while the challenging black-box ones, as more practical adversaries in real-world cases, are still largely under-explored. To this end, we present SemBLK, a novel method that can learn to generate destructive physical layer semantic attacks for an ESC system under the black-box setting, where the adversaries are imperceptible to humans. Specifically, 1) we first introduce a surrogate semantic encoder and train its parameters by exploring a limited number of queries to an existing ESC system. 2) Equipped with such a surrogate encoder, we then propose a novel semantic perturbation generation method to learn to boost the physical layer attacks with semantic adversaries. Experiments on two public datasets show the effectiveness of our proposed SemBLK in attacking the ESC system under the black-box setting. Finally, we provide case studies to visually justify the superiority of our physical layer semantic perturbations.
Modelling and Explaining Legal Case-based Reasoners through Classifiers
Oct 20, 2022This paper brings together two lines of research: factor-based models of case-based reasoning (CBR) and the logical specification of classifiers. Logical approaches to classifiers capture the connection between features and outcomes in classifier systems. Factor-based reasoning is a popular approach to reasoning by precedent in AI & Law. Horty (2011) has developed the factor-based models of precedent into a theory of precedential constraint. In this paper we combine the modal logic approach (binary-input classifier, BLC) to classifiers and their explanations given by Liu & Lorini (2021) with Horty's account of factor-based CBR, since both a classifier and CBR map sets of features to decisions or classifications. We reformulate case bases of Horty in the language of BCL, and give several representation results. Furthermore, we show how notions of CBR, e.g. reason, preference between reasons, can be analyzed by notions of classifier system.
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
May 29, 2022
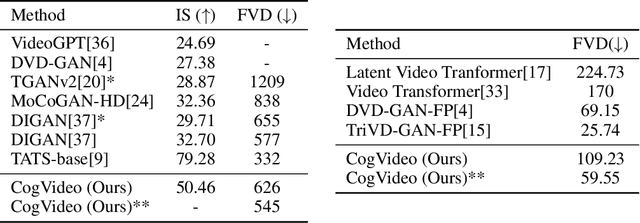
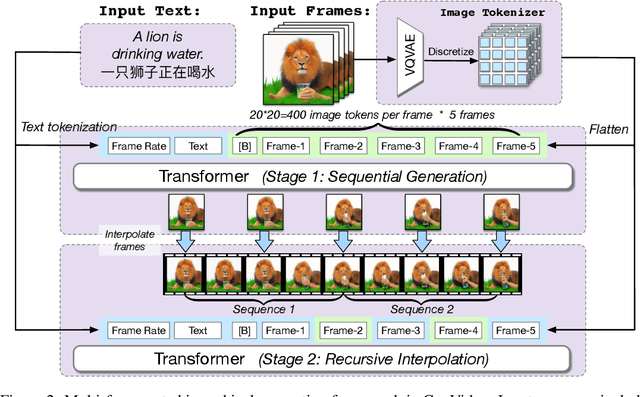

Large-scale pretrained transformers have created milestones in text (GPT-3) and text-to-image (DALL-E and CogView) generation. Its application to video generation is still facing many challenges: The potential huge computation cost makes the training from scratch unaffordable; The scarcity and weak relevance of text-video datasets hinder the model understanding complex movement semantics. In this work, we present 9B-parameter transformer CogVideo, trained by inheriting a pretrained text-to-image model, CogView2. We also propose multi-frame-rate hierarchical training strategy to better align text and video clips. As (probably) the first open-source large-scale pretrained text-to-video model, CogVideo outperforms all publicly available models at a large margin in machine and human evaluations.
A logic for binary classifiers and their explanation
May 30, 2021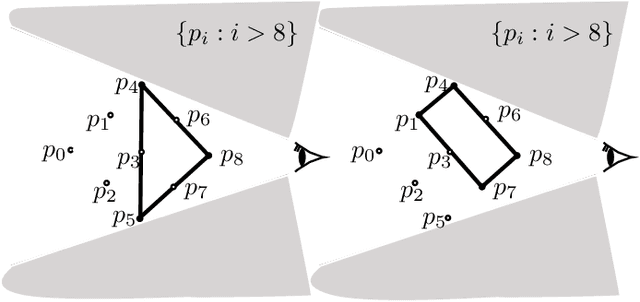
Recent years have witnessed a renewed interest in Boolean function in explaining binary classifiers in the field of explainable AI (XAI). The standard approach of Boolean function is propositional logic. We present a modal language of a ceteris paribus nature which supports reasoning about binary classifiers and their properties. We study families of decision models for binary classifiers, axiomatize them and show completeness of our axiomatics. Moreover, we prove that the variant of our modal language with finite propositional atoms interpreted over these models is NP-complete. We leverage the language to formalize counterfactual conditional as well as a bunch of notions of explanation such as abductive, contrastive and counterfactual explanations, and biases. Finally, we present two extensions of our language: a dynamic extension by the notion of assignment enabling classifier change and an epistemic extension in which the classifier's uncertainty about the actual input can be represented.