 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeroFlow: Overcoming Catastrophic Forgetting is Easier than You Think
Jan 03, 2025



Backpropagation provides a generalized configuration for overcoming catastrophic forgetting. Like, SGD and Adam are commonly used for weight updates in continual learning and continual pre-training. In practice, permission to access gradient information is not always granted (the gradient ban), such as black-box APIs, hardware limitations, and non-differentiable systems. To bridge this gap, we introduce the first benchmark ZeroFlow to evaluate gradient-free optimization algorithms for overcoming forgetting. This benchmark examines a suite of forward pass methods across multiple methods, forgetting scenarios, and datasets. We find that forward passes alone are enough to overcome forgetting. Our findings reveal new optimization principles that highlight the potential of forward-pass in mitigating forgetting, managing task conflicts, and reducing memory demands, alongside novel enhancements that further mitigate forgetting with just one forward pass. This work provides essential insights and tools for advancing forward pass methods to overcome forgetting.
VisionReward: Fine-Grained Multi-Dimensional Human Preference Learning for Image and Video Generation
Dec 30, 2024We present a general strategy to aligning visual generation models -- both image and video generation -- with human preference. To start with, we build VisionReward -- a fine-grained and multi-dimensional reward model. We decompose human preferences in images and videos into multiple dimensions, each represented by a series of judgment questions, linearly weighted and summed to an interpretable and accurate score. To address the challenges of video quality assessment, we systematically analyze various dynamic features of videos, which helps VisionReward surpass VideoScore by 17.2% and achieve top performance for video preference prediction. Based on VisionReward, we develop a multi-objective preference learning algorithm that effectively addresses the issue of confounding factors within preference data. Our approach significantly outperforms existing image and video scoring methods on both machine metrics and human evaluation. All code and datasets are provided at https://github.com/THUDM/VisionReward.
DreamPolish: Domain Score Distillation With Progressive Geometry Generation
Nov 03, 2024



We introduce DreamPolish, a text-to-3D generation model that excels in producing refined geometry and high-quality textures. In the geometry construction phase, our approach leverages multiple neural representations to enhance the stability of the synthesis process. Instead of relying solely on a view-conditioned diffusion prior in the novel sampled views, which often leads to undesired artifacts in the geometric surface, we incorporate an additional normal estimator to polish the geometry details, conditioned on viewpoints with varying field-of-views. We propose to add a surface polishing stage with only a few training steps, which can effectively refine the artifacts attributed to limited guidance from previous stages and produce 3D objects with more desirable geometry. The key topic of texture generation using pretrained text-to-image models is to find a suitable domain in the vast latent distribution of these models that contains photorealistic and consistent renderings. In the texture generation phase, we introduce a novel score distillation objective, namely domain score distillation (DSD), to guide neural representations toward such a domain. We draw inspiration from the classifier-free guidance (CFG) in textconditioned image generation tasks and show that CFG and variational distribution guidance represent distinct aspects in gradient guidance and are both imperative domains for the enhancement of texture quality. Extensive experiments show our proposed model can produce 3D assets with polished surfaces and photorealistic textures, outperforming existing state-of-the-art methods.
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Aug 12, 2024We introduce CogVideoX, a large-scale diffusion transformer model designed for generating videos based on text prompts. To efficently model video data, we propose to levearge a 3D Variational Autoencoder (VAE) to compress videos along both spatial and temporal dimensions. To improve the text-video alignment, we propose an expert transformer with the expert adaptive LayerNorm to facilitate the deep fusion between the two modalities. By employing a progressive training technique, CogVideoX is adept at producing coherent, long-duration videos characterized by significant motions. In addition, we develop an effective text-video data processing pipeline that includes various data preprocessing strategies and a video captioning method. It significantly helps enhance the performance of CogVideoX, improving both generation quality and semantic alignment. Results show that CogVideoX demonstrates state-of-the-art performance across both multiple machine metrics and human evaluations. The model weights of both the 3D Causal VAE and CogVideoX are publicly available at https://github.com/THUDM/CogVideo.
Inf-DiT: Upsampling Any-Resolution Image with Memory-Efficient Diffusion Transformer
May 08, 2024



Diffusion models have shown remarkable performance in image generation in recent years. However, due to a quadratic increase in memory during generating ultra-high-resolution images (e.g. 4096*4096), the resolution of generated images is often limited to 1024*1024. In this work. we propose a unidirectional block attention mechanism that can adaptively adjust the memory overhead during the inference process and handle global dependencies. Building on this module, we adopt the DiT structure for upsampling and develop an infinite super-resolution model capable of upsampling images of various shapes and resolutions. Comprehensive experiments show that our model achieves SOTA performance in generating ultra-high-resolution images in both machine and human evaluation. Compared to commonly used UNet structures, our model can save more than 5x memory when generating 4096*4096 images. The project URL is https://github.com/THUDM/Inf-DiT.
CogView3: Finer and Faster Text-to-Image Generation via Relay Diffusion
Mar 08, 2024



Recent advancements in text-to-image generative systems have been largely driven by diffusion models. However, single-stage text-to-image diffusion models still face challenges, in terms of computational efficiency and the refinement of image details. To tackle the issue, we propose CogView3, an innovative cascaded framework that enhances the performance of text-to-image diffusion. CogView3 is the first model implementing relay diffusion in the realm of text-to-image generation, executing the task by first creating low-resolution images and subsequently applying relay-based super-resolution. This methodology not only results in competitive text-to-image outputs but also greatly reduces both training and inference costs. Our experimental results demonstrate that CogView3 outperforms SDXL, the current state-of-the-art open-source text-to-image diffusion model, by 77.0\% in human evaluations, all while requiring only about 1/2 of the inference time. The distilled variant of CogView3 achieves comparable performance while only utilizing 1/10 of the inference time by SDXL.
Multi-Agent Collaboration Framework for Recommender Systems
Feb 23, 2024



LLM-based agents have gained considerable attention for their decision-making skills and ability to handle complex tasks. Recognizing the current gap in leveraging agent capabilities for multi-agent collaboration in recommendation systems, we introduce MACRec, a novel framework designed to enhance recommendation systems through multi-agent collaboration. Unlike existing work on using agents for user/item simulation, we aim to deploy multi-agents to tackle recommendation tasks directly. In our framework, recommendation tasks are addressed through the collaborative efforts of various specialized agents, including Manager, User/Item Analyst, Reflector, Searcher, and Task Interpreter, with different working flows. Furthermore, we provide application examples of how developers can easily use MACRec on various recommendation tasks, including rating prediction, sequential recommendation, conversational recommendation, and explanation generation of recommendation results. The framework and demonstration video are publicly available at https://github.com/wzf2000/MACRec.
Relay Diffusion: Unifying diffusion process across resolutions for image synthesis
Sep 04, 2023Diffusion models achieved great success in image synthesis, but still face challenges in high-resolution generation. Through the lens of discrete cosine transformation, we find the main reason is that \emph{the same noise level on a higher resolution results in a higher Signal-to-Noise Ratio in the frequency domain}. In this work, we present Relay Diffusion Model (RDM), which transfers a low-resolution image or noise into an equivalent high-resolution one for diffusion model via blurring diffusion and block noise. Therefore, the diffusion process can continue seamlessly in any new resolution or model without restarting from pure noise or low-resolution conditioning. RDM achieves state-of-the-art FID on CelebA-HQ and sFID on ImageNet 256$\times$256, surpassing previous works such as ADM, LDM and DiT by a large margin. All the codes and checkpoints are open-sourced at \url{https://github.com/THUDM/RelayDiffusion}.
GLM-130B: An Open Bilingual Pre-trained Model
Oct 05, 2022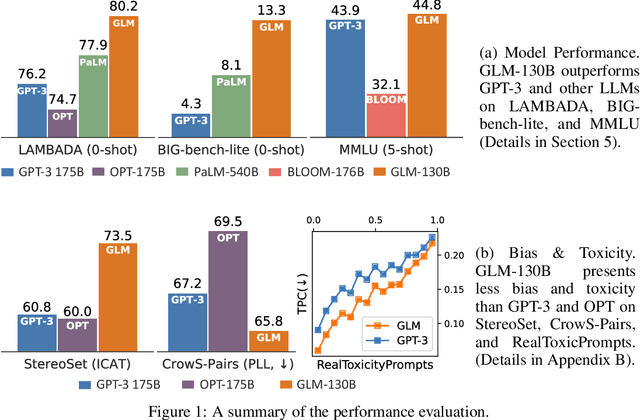
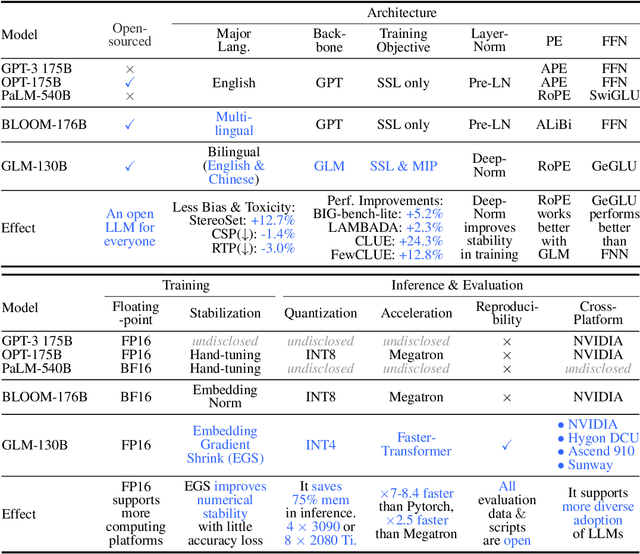

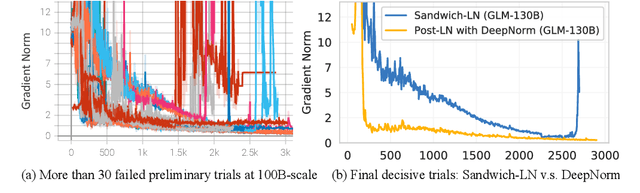
We introduce GLM-130B, a bilingual (English and Chinese) pre-trained language model with 130 billion parameters. It is an attempt to open-source a 100B-scale model at least as good as GPT-3 and unveil how models of such a scale can be successfully pre-trained. Over the course of this effort, we face numerous unexpected technical and engineering challenges, particularly on loss spikes and disconvergence. In this paper, we introduce the training process of GLM-130B including its design choices, training strategies for both efficiency and stability, and engineering efforts. The resultant GLM-130B model offers significant outperformance over GPT-3 175B on a wide range of popular English benchmarks while the performance advantage is not observed in OPT-175B and BLOOM-176B. It also consistently and significantly outperforms ERNIE TITAN 3.0 260B -- the largest Chinese language model -- across related benchmarks. Finally, we leverage a unique scaling property of GLM-130B to reach INT4 quantization, without quantization aware training and with almost no performance loss, making it the first among 100B-scale models. More importantly, the property allows its effective inference on 4$\times$RTX 3090 (24G) or 8$\times$RTX 2080 Ti (11G) GPUs, the most ever affordable GPUs required for using 100B-scale models. The GLM-130B model weights are publicly accessible and its code, training logs, related toolkit, and lessons learned are open-sourced at https://github.com/THUDM/GLM-130B .
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
May 29, 2022
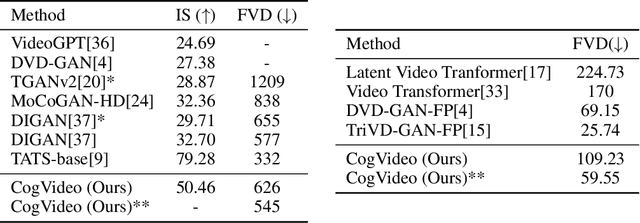
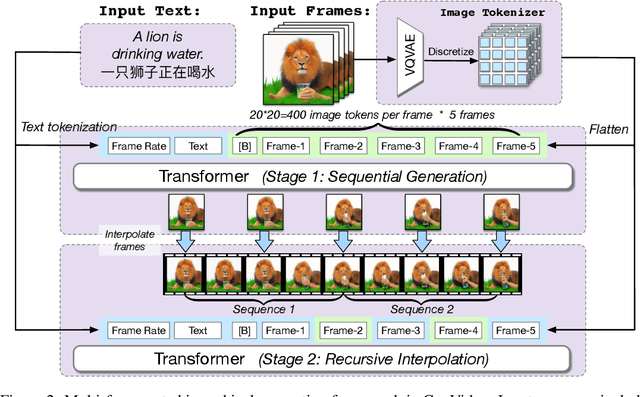

Large-scale pretrained transformers have created milestones in text (GPT-3) and text-to-image (DALL-E and CogView) generation. Its application to video generation is still facing many challenges: The potential huge computation cost makes the training from scratch unaffordable; The scarcity and weak relevance of text-video datasets hinder the model understanding complex movement semantics. In this work, we present 9B-parameter transformer CogVideo, trained by inheriting a pretrained text-to-image model, CogView2. We also propose multi-frame-rate hierarchical training strategy to better align text and video clips. As (probably) the first open-source large-scale pretrained text-to-video model, CogVideo outperforms all publicly available models at a large margin in machine and human evaluations.