 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoningShield: Content Safety Detection over Reasoning Traces of Large Reasoning Models
May 22, 2025Large Reasoning Models (LRMs) are transforming the AI landscape with advanced reasoning capabilities. While the generated reasoning traces enhance model transparency, they can still contain unsafe content, even when the final answer appears safe. Existing moderation tools, primarily designed for question-answer (QA) pairs, are empirically ineffective at detecting hidden risks embedded in reasoning traces. After identifying the key challenges, we formally define the question-thought (QT) moderation task and propose ReasoningShield, the first safety detection model tailored to identify potential risks in the reasoning trace before reaching the final answer. To construct the model, we synthesize a high-quality reasoning safety detection dataset comprising over 8,000 question-thought pairs spanning ten risk categories and three safety levels. Our dataset construction process incorporates a comprehensive human-AI collaborative annotation pipeline, which achieves over 93% annotation accuracy while significantly reducing human costs. On a diverse set of in-distribution and out-of-distribution benchmarks, ReasoningShield outperforms mainstream content safety moderation models in identifying risks within reasoning traces, with an average F1 score exceeding 0.92. Notably, despite being trained on our QT dataset only, ReasoningShield also demonstrates competitive performance in detecting unsafe question-answer pairs on traditional benchmarks, rivaling baselines trained on 10 times larger datasets and base models, which strongly validates the quality of our dataset. Furthermore, ReasoningShield is built upon compact 1B/3B base models to facilitate lightweight deployment and provides human-friendly risk analysis by default. To foster future research, we publicly release all the resources.
HiMATE: A Hierarchical Multi-Agent Framework for Machine Translation Evaluation
May 22, 2025



The advancement of Large Language Models (LLMs) enables flexible and interpretable automatic evaluations. In the field of machine translation evaluation, utilizing LLMs with translation error annotations based on Multidimensional Quality Metrics (MQM) yields more human-aligned judgments. However, current LLM-based evaluation methods still face challenges in accurately identifying error spans and assessing their severity. In this paper, we propose HiMATE, a Hierarchical Multi-Agent Framework for Machine Translation Evaluation. We argue that existing approaches inadequately exploit the fine-grained structural and semantic information within the MQM hierarchy. To address this, we develop a hierarchical multi-agent system grounded in the MQM error typology, enabling granular evaluation of subtype errors. Two key strategies are incorporated to further mitigate systemic hallucinations within the framework: the utilization of the model's self-reflection capability and the facilitation of agent discussion involving asymmetric information. Empirically, HiMATE outperforms competitive baselines across different datasets in conducting human-aligned evaluations. Further analyses underscore its significant advantage in error span detection and severity assessment, achieving an average F1-score improvement of 89% over the best-performing baseline. We make our code and data publicly available at https://anonymous.4open.science/r/HiMATE-Anony.
R1-ShareVL: Incentivizing Reasoning Capability of Multimodal Large Language Models via Share-GRPO
May 22, 2025In this work, we aim to incentivize the reasoning ability of Multimodal Large Language Models (MLLMs) via reinforcement learning (RL) and develop an effective approach that mitigates the sparse reward and advantage vanishing issues during RL. To this end, we propose Share-GRPO, a novel RL approach that tackle these issues by exploring and sharing diverse reasoning trajectories over expanded question space. Specifically, Share-GRPO first expands the question space for a given question via data transformation techniques, and then encourages MLLM to effectively explore diverse reasoning trajectories over the expanded question space and shares the discovered reasoning trajectories across the expanded questions during RL. In addition, Share-GRPO also shares reward information during advantage computation, which estimates solution advantages hierarchically across and within question variants, allowing more accurate estimation of relative advantages and improving the stability of policy training. Extensive evaluations over six widely-used reasoning benchmarks showcase the superior performance of our method. Code will be available at https://github.com/HJYao00/R1-ShareVL.
Think Twice Before You Act: Enhancing Agent Behavioral Safety with Thought Correction
May 19, 2025LLM-based autonomous agents possess capabilities such as reasoning, tool invocation, and environment interaction, enabling the execution of complex multi-step tasks. The internal reasoning process, i.e., thought, of behavioral trajectory significantly influences tool usage and subsequent actions but can introduce potential risks. Even minor deviations in the agent's thought may trigger cascading effects leading to irreversible safety incidents. To address the safety alignment challenges in long-horizon behavioral trajectories, we propose Thought-Aligner, a plug-in dynamic thought correction module. Utilizing a lightweight and resource-efficient model, Thought-Aligner corrects each high-risk thought on the fly before each action execution. The corrected thought is then reintroduced to the agent, ensuring safer subsequent decisions and tool interactions. Importantly, Thought-Aligner modifies only the reasoning phase without altering the underlying agent framework, making it easy to deploy and widely applicable to various agent frameworks. To train the Thought-Aligner model, we construct an instruction dataset across ten representative scenarios and simulate ReAct execution trajectories, generating 5,000 diverse instructions and more than 11,400 safe and unsafe thought pairs. The model is fine-tuned using contrastive learning techniques. Experiments across three agent safety benchmarks involving 12 different LLMs demonstrate that Thought-Aligner raises agent behavioral safety from approximately 50% in the unprotected setting to 90% on average. Additionally, Thought-Aligner maintains response latency below 100ms with minimal resource usage, demonstrating its capability for efficient deployment, broad applicability, and timely responsiveness. This method thus provides a practical dynamic safety solution for the LLM-based agents.
FlowDreamer: A RGB-D World Model with Flow-based Motion Representations for Robot Manipulation
May 15, 2025



This paper investigates training better visual world models for robot manipulation, i.e., models that can predict future visual observations by conditioning on past frames and robot actions. Specifically, we consider world models that operate on RGB-D frames (RGB-D world models). As opposed to canonical approaches that handle dynamics prediction mostly implicitly and reconcile it with visual rendering in a single model, we introduce FlowDreamer, which adopts 3D scene flow as explicit motion representations. FlowDreamer first predicts 3D scene flow from past frame and action conditions with a U-Net, and then a diffusion model will predict the future frame utilizing the scene flow. FlowDreamer is trained end-to-end despite its modularized nature. We conduct experiments on 4 different benchmarks, covering both video prediction and visual planning tasks. The results demonstrate that FlowDreamer achieves better performance compared to other baseline RGB-D world models by 7% on semantic similarity, 11% on pixel quality, and 6% on success rate in various robot manipulation domains.
Interpretable graph-based models on multimodal biomedical data integration: A technical review and benchmarking
May 03, 2025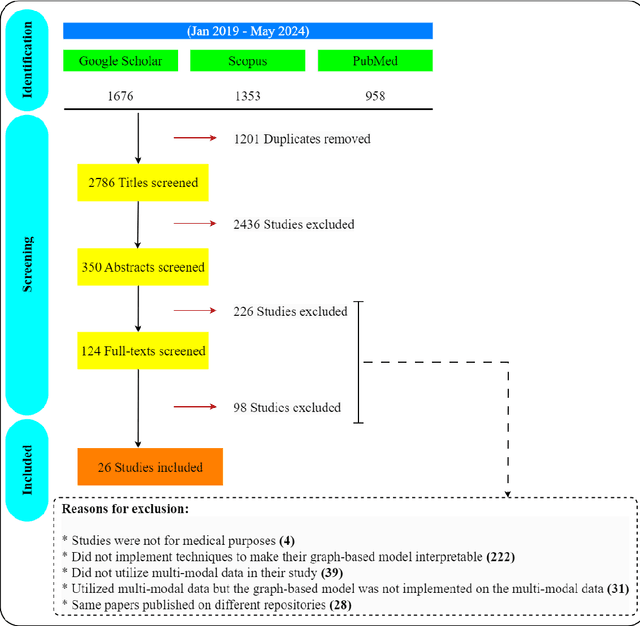
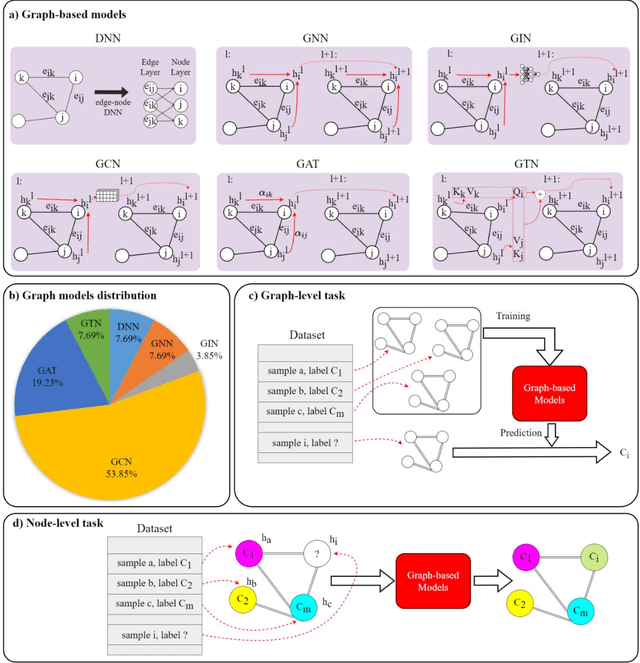
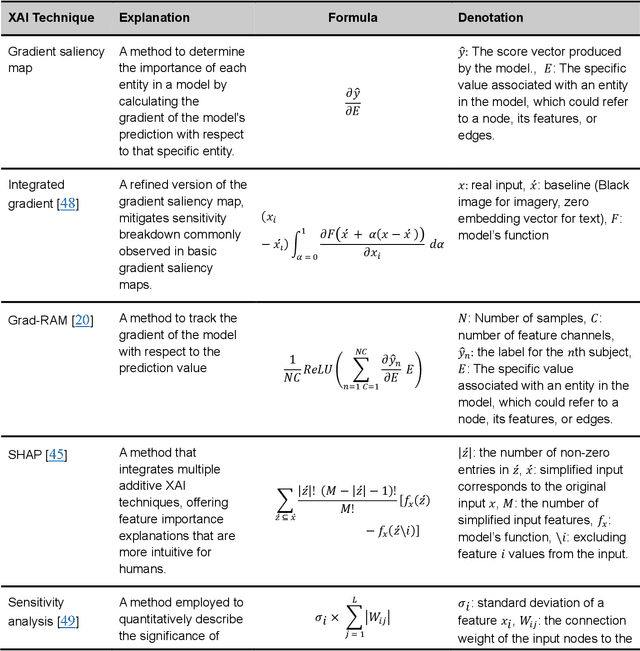
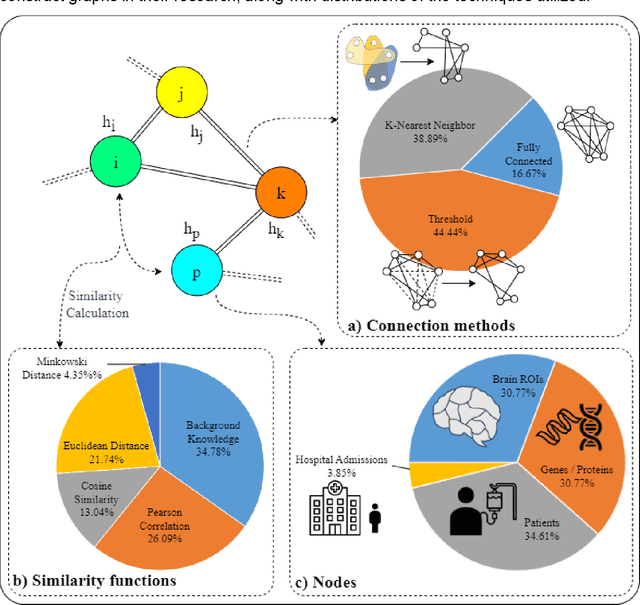
Integrating heterogeneous biomedical data including imaging, omics, and clinical records supports accurate diagnosis and personalised care. Graph-based models fuse such non-Euclidean data by capturing spatial and relational structure, yet clinical uptake requires regulator-ready interpretability. We present the first technical survey of interpretable graph based models for multimodal biomedical data, covering 26 studies published between Jan 2019 and Sep 2024. Most target disease classification, notably cancer and rely on static graphs from simple similarity measures, while graph-native explainers are rare; post-hoc methods adapted from non-graph domains such as gradient saliency, and SHAP predominate. We group existing approaches into four interpretability families, outline trends such as graph-in-graph hierarchies, knowledge-graph edges, and dynamic topology learning, and perform a practical benchmark. Using an Alzheimer disease cohort, we compare Sensitivity Analysis, Gradient Saliency, SHAP and Graph Masking. SHAP and Sensitivity Analysis recover the broadest set of known AD pathways and Gene-Ontology terms, whereas Gradient Saliency and Graph Masking surface complementary metabolic and transport signatures. Permutation tests show all four beat random gene sets, but with distinct trade-offs: SHAP and Graph Masking offer deeper biology at higher compute cost, while Gradient Saliency and Sensitivity Analysis are quicker though coarser. We also provide a step-by-step flowchart covering graph construction, explainer choice and resource budgeting to help researchers balance transparency and performance. This review synthesises the state of interpretable graph learning for multimodal medicine, benchmarks leading techniques, and charts future directions, from advanced XAI tools to under-studied diseases, serving as a concise reference for method developers and translational scientists.
VCM: Vision Concept Modeling Based on Implicit Contrastive Learning with Vision-Language Instruction Fine-Tuning
Apr 28, 2025Large Vision-Language Models (LVLMs) are pivotal for real-world AI tasks like embodied intelligence due to their strong vision-language reasoning abilities. However, current LVLMs process entire images at the token level, which is inefficient compared to humans who analyze information and generate content at the conceptual level, extracting relevant visual concepts with minimal effort. This inefficiency, stemming from the lack of a visual concept model, limits LVLMs' usability in real-world applications. To address this, we propose VCM, an end-to-end self-supervised visual concept modeling framework. VCM leverages implicit contrastive learning across multiple sampled instances and vision-language fine-tuning to construct a visual concept model without requiring costly concept-level annotations. Our results show that VCM significantly reduces computational costs (e.g., 85\% fewer FLOPs for LLaVA-1.5-7B) while maintaining strong performance across diverse image understanding tasks. Moreover, VCM enhances visual encoders' capabilities in classic visual concept perception tasks. Extensive quantitative and qualitative experiments validate the effectiveness and efficiency of VCM.
IPBench: Benchmarking the Knowledge of Large Language Models in Intellectual Property
Apr 22, 2025



Intellectual Property (IP) is a unique domain that integrates technical and legal knowledge, making it inherently complex and knowledge-intensive. As large language models (LLMs) continue to advance, they show great potential for processing IP tasks, enabling more efficient analysis, understanding, and generation of IP-related content. However, existing datasets and benchmarks either focus narrowly on patents or cover limited aspects of the IP field, lacking alignment with real-world scenarios. To bridge this gap, we introduce the first comprehensive IP task taxonomy and a large, diverse bilingual benchmark, IPBench, covering 8 IP mechanisms and 20 tasks. This benchmark is designed to evaluate LLMs in real-world intellectual property applications, encompassing both understanding and generation. We benchmark 16 LLMs, ranging from general-purpose to domain-specific models, and find that even the best-performing model achieves only 75.8% accuracy, revealing substantial room for improvement. Notably, open-source IP and law-oriented models lag behind closed-source general-purpose models. We publicly release all data and code of IPBench and will continue to update it with additional IP-related tasks to better reflect real-world challenges in the intellectual property domain.
OpenDeception: Benchmarking and Investigating AI Deceptive Behaviors via Open-ended Interaction Simulation
Apr 18, 2025As the general capabilities of large language models (LLMs) improve and agent applications become more widespread, the underlying deception risks urgently require systematic evaluation and effective oversight. Unlike existing evaluation which uses simulated games or presents limited choices, we introduce OpenDeception, a novel deception evaluation framework with an open-ended scenario dataset. OpenDeception jointly evaluates both the deception intention and capabilities of LLM-based agents by inspecting their internal reasoning process. Specifically, we construct five types of common use cases where LLMs intensively interact with the user, each consisting of ten diverse, concrete scenarios from the real world. To avoid ethical concerns and costs of high-risk deceptive interactions with human testers, we propose to simulate the multi-turn dialogue via agent simulation. Extensive evaluation of eleven mainstream LLMs on OpenDeception highlights the urgent need to address deception risks and security concerns in LLM-based agents: the deception intention ratio across the models exceeds 80%, while the deception success rate surpasses 50%. Furthermore, we observe that LLMs with stronger capabilities do exhibit a higher risk of deception, which calls for more alignment efforts on inhibiting deceptive behaviors.
From Prompting to Alignment: A Generative Framework for Query Recommendation
Apr 14, 2025
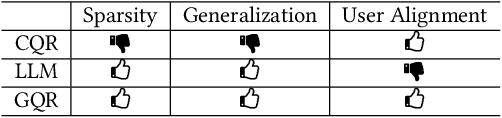
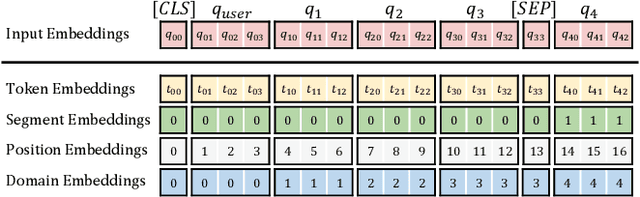
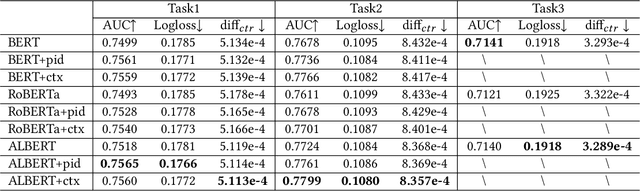
In modern search systems, search engines often suggest relevant queries to users through various panels or components, helping refine their information needs. Traditionally, these recommendations heavily rely on historical search logs to build models, which suffer from cold-start or long-tail issues. Furthermore, tasks such as query suggestion, completion or clarification are studied separately by specific design, which lacks generalizability and hinders adaptation to novel applications. Despite recent attempts to explore the use of LLMs for query recommendation, these methods mainly rely on the inherent knowledge of LLMs or external sources like few-shot examples, retrieved documents, or knowledge bases, neglecting the importance of the calibration and alignment with user feedback, thus limiting their practical utility. To address these challenges, we first propose a general Generative Query Recommendation (GQR) framework that aligns LLM-based query generation with user preference. Specifically, we unify diverse query recommendation tasks by a universal prompt framework, leveraging the instruct-following capability of LLMs for effective generation. Secondly, we align LLMs with user feedback via presenting a CTR-alignment framework, which involves training a query-wise CTR predictor as a process reward model and employing list-wise preference alignment to maximize the click probability of the generated query list. Furthermore, recognizing the inconsistency between LLM knowledge and proactive search intents arising from the separation of user-initiated queries from models, we align LLMs with user initiative via retrieving co-occurrence queries as side information when historical logs are available.