 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Question Answering Dataset for Temporal-Sensitive Retrieval-Augmented Generation
Aug 17, 2025We introduce ChronoQA, a large-scale benchmark dataset for Chinese question answering, specifically designed to evaluate temporal reasoning in Retrieval-Augmented Generation (RAG) systems. ChronoQA is constructed from over 300,000 news articles published between 2019 and 2024, and contains 5,176 high-quality questions covering absolute, aggregate, and relative temporal types with both explicit and implicit time expressions. The dataset supports both single- and multi-document scenarios, reflecting the real-world requirements for temporal alignment and logical consistency. ChronoQA features comprehensive structural annotations and has undergone multi-stage validation, including rule-based, LLM-based, and human evaluation, to ensure data quality. By providing a dynamic, reliable, and scalable resource, ChronoQA enables structured evaluation across a wide range of temporal tasks, and serves as a robust benchmark for advancing time-sensitive retrieval-augmented question answering systems.
From Prompting to Alignment: A Generative Framework for Query Recommendation
Apr 14, 2025
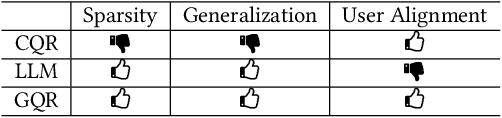
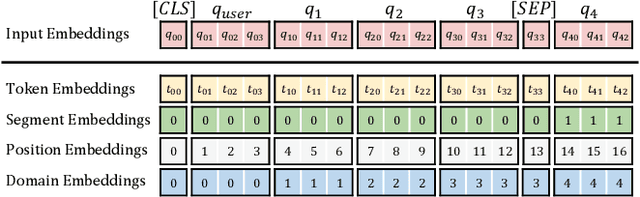
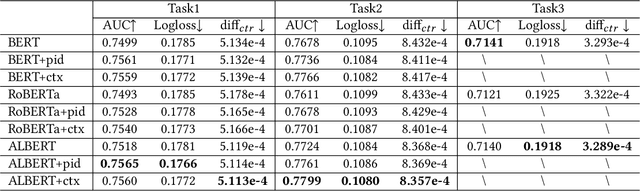
In modern search systems, search engines often suggest relevant queries to users through various panels or components, helping refine their information needs. Traditionally, these recommendations heavily rely on historical search logs to build models, which suffer from cold-start or long-tail issues. Furthermore, tasks such as query suggestion, completion or clarification are studied separately by specific design, which lacks generalizability and hinders adaptation to novel applications. Despite recent attempts to explore the use of LLMs for query recommendation, these methods mainly rely on the inherent knowledge of LLMs or external sources like few-shot examples, retrieved documents, or knowledge bases, neglecting the importance of the calibration and alignment with user feedback, thus limiting their practical utility. To address these challenges, we first propose a general Generative Query Recommendation (GQR) framework that aligns LLM-based query generation with user preference. Specifically, we unify diverse query recommendation tasks by a universal prompt framework, leveraging the instruct-following capability of LLMs for effective generation. Secondly, we align LLMs with user feedback via presenting a CTR-alignment framework, which involves training a query-wise CTR predictor as a process reward model and employing list-wise preference alignment to maximize the click probability of the generated query list. Furthermore, recognizing the inconsistency between LLM knowledge and proactive search intents arising from the separation of user-initiated queries from models, we align LLMs with user initiative via retrieving co-occurrence queries as side information when historical logs are available.
Enhancing Pre-trained Models with Text Structure Knowledge for Question Generation
Sep 09, 2022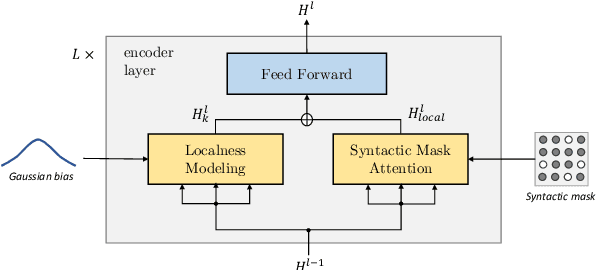
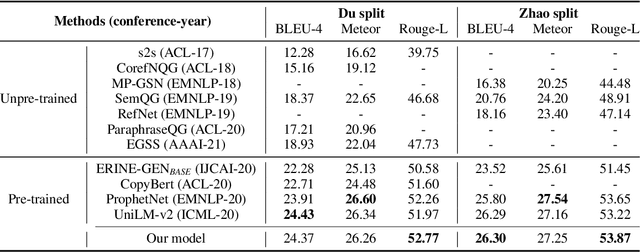
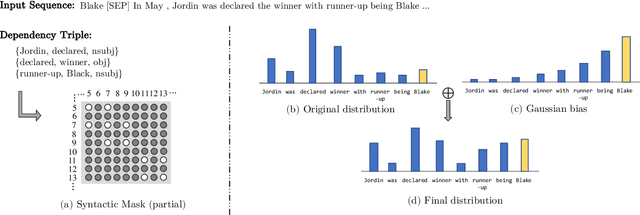

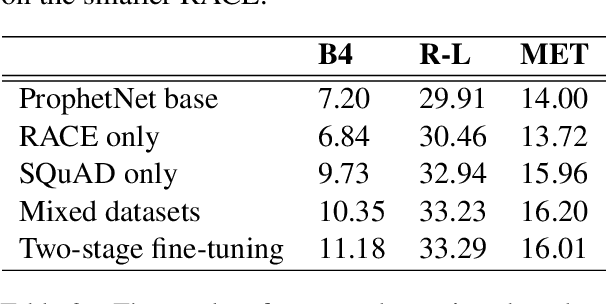
Today the pre-trained language models achieve great success for question generation (QG) task and significantly outperform traditional sequence-to-sequence approaches. However, the pre-trained models treat the input passage as a flat sequence and are thus not aware of the text structure of input passage. For QG task, we model text structure as answer position and syntactic dependency, and propose answer localness modeling and syntactic mask attention to address these limitations. Specially, we present localness modeling with a Gaussian bias to enable the model to focus on answer-surrounded context, and propose a mask attention mechanism to make the syntactic structure of input passage accessible in question generation process. Experiments on SQuAD dataset show that our proposed two modules improve performance over the strong pre-trained model ProphetNet, and combing them together achieves very competitive results with the state-of-the-art pre-trained model.
Asking Questions Like Educational Experts: Automatically Generating Question-Answer Pairs on Real-World Examination Data
Sep 17, 2021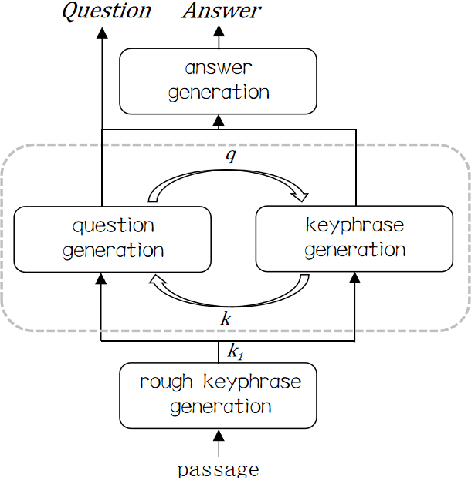

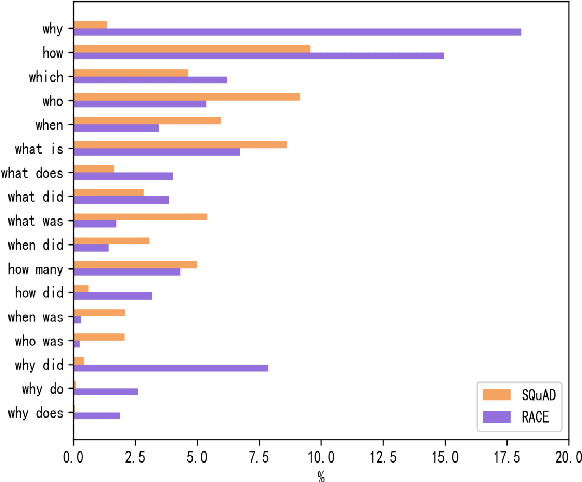
Generating high quality question-answer pairs is a hard but meaningful task. Although previous works have achieved great results on answer-aware question generation, it is difficult to apply them into practical application in the education field. This paper for the first time addresses the question-answer pair generation task on the real-world examination data, and proposes a new unified framework on RACE. To capture the important information of the input passage we first automatically generate(rather than extracting) keyphrases, thus this task is reduced to keyphrase-question-answer triplet joint generation. Accordingly, we propose a multi-agent communication model to generate and optimize the question and keyphrases iteratively, and then apply the generated question and keyphrases to guide the generation of answers. To establish a solid benchmark, we build our model on the strong generative pre-training model. Experimental results show that our model makes great breakthroughs in the question-answer pair generation task. Moreover, we make a comprehensive analysis on our model, suggesting new directions for this challenging task.
Enhancing Question Generation with Commonsense Knowledge
Jun 19, 2021
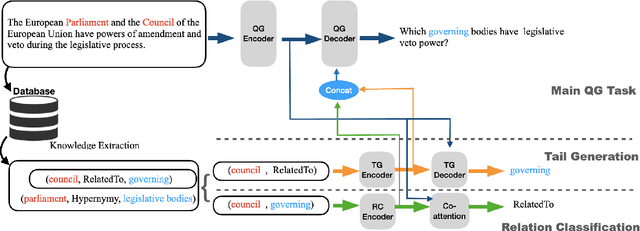
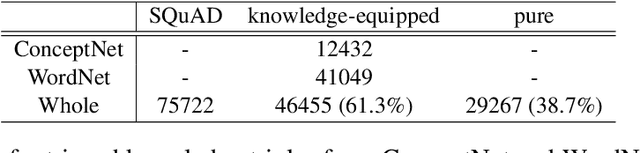
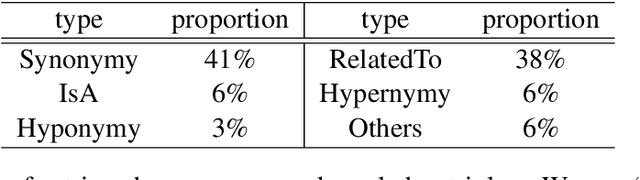
Question generation (QG) is to generate natural and grammatical questions that can be answered by a specific answer for a given context. Previous sequence-to-sequence models suffer from a problem that asking high-quality questions requires commonsense knowledge as backgrounds, which in most cases can not be learned directly from training data, resulting in unsatisfactory questions deprived of knowledge. In this paper, we propose a multi-task learning framework to introduce commonsense knowledge into question generation process. We first retrieve relevant commonsense knowledge triples from mature databases and select triples with the conversion information from source context to question. Based on these informative knowledge triples, we design two auxiliary tasks to incorporate commonsense knowledge into the main QG model, where one task is Concept Relation Classification and the other is Tail Concept Generation. Experimental results on SQuAD show that our proposed methods are able to noticeably improve the QG performance on both automatic and human evaluation metrics, demonstrating that incorporating external commonsense knowledge with multi-task learning can help the model generate human-like and high-quality questions.
EQG-RACE: Examination-Type Question Generation
Dec 11, 2020
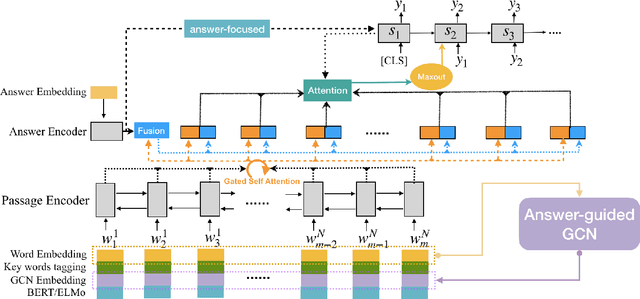

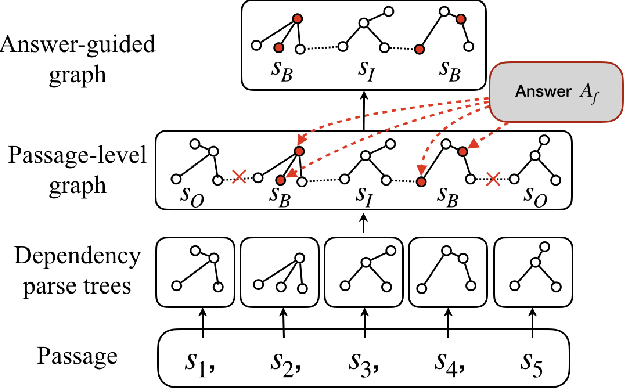
Question Generation (QG) is an essential component of the automatic intelligent tutoring systems, which aims to generate high-quality questions for facilitating the reading practice and assessments. However, existing QG technologies encounter several key issues concerning the biased and unnatural language sources of datasets which are mainly obtained from the Web (e.g. SQuAD). In this paper, we propose an innovative Examination-type Question Generation approach (EQG-RACE) to generate exam-like questions based on a dataset extracted from RACE. Two main strategies are employed in EQG-RACE for dealing with discrete answer information and reasoning among long contexts. A Rough Answer and Key Sentence Tagging scheme is utilized to enhance the representations of input. An Answer-guided Graph Convolutional Network (AG-GCN) is designed to capture structure information in revealing the inter-sentences and intra-sentence relations. Experimental results show a state-of-the-art performance of EQG-RACE, which is apparently superior to the baselines. In addition, our work has established a new QG prototype with a reshaped dataset and QG method, which provides an important benchmark for related research in future work. We will make our data and code publicly available for further research.