 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 3D Restoration and Reconstruction in Real-world Adverse Conditions: RealX3D Challenge Results
Apr 05, 2026This paper presents a comprehensive review of the NTIRE 2026 3D Restoration and Reconstruction (3DRR) Challenge, detailing the proposed methods and results. The challenge seeks to identify robust reconstruction pipelines that are robust under real-world adverse conditions, specifically extreme low-light and smoke-degraded environments, as captured by our RealX3D benchmark. A total of 279 participants registered for the competition, of whom 33 teams submitted valid results. We thoroughly evaluate the submitted approaches against state-of-the-art baselines, revealing significant progress in 3D reconstruction under adverse conditions. Our analysis highlights shared design principles among top-performing methods and provides insights into effective strategies for handling 3D scene degradation.
SegviGen: Repurposing 3D Generative Model for Part Segmentation
Mar 17, 2026We introduce SegviGen, a framework that repurposes native 3D generative models for 3D part segmentation. Existing pipelines either lift strong 2D priors into 3D via distillation or multi-view mask aggregation, often suffering from cross-view inconsistency and blurred boundaries, or explore native 3D discriminative segmentation, which typically requires large-scale annotated 3D data and substantial training resources. In contrast, SegviGen leverages the structured priors encoded in pretrained 3D generative model to induce segmentation through distinctive part colorization, establishing a novel and efficient framework for part segmentation. Specifically, SegviGen encodes a 3D asset and predicts part-indicative colors on active voxels of a geometry-aligned reconstruction. It supports interactive part segmentation, full segmentation, and full segmentation with 2D guidance in a unified framework. Extensive experiments show that SegviGen improves over the prior state of the art by 40% on interactive part segmentation and by 15% on full segmentation, while using only 0.32% of the labeled training data. It demonstrates that pretrained 3D generative priors transfer effectively to 3D part segmentation, enabling strong performance with limited supervision. See our project page at https://fenghora.github.io/SegviGen-Page/.
VoxHammer: Training-Free Precise and Coherent 3D Editing in Native 3D Space
Aug 26, 2025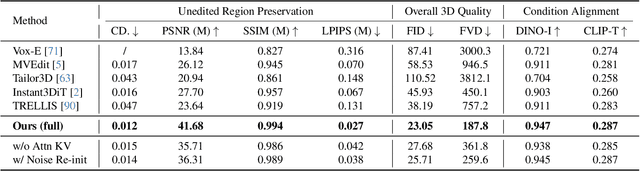
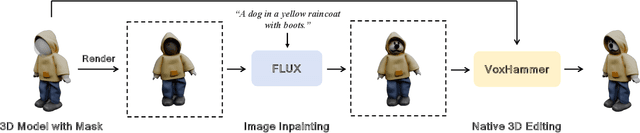

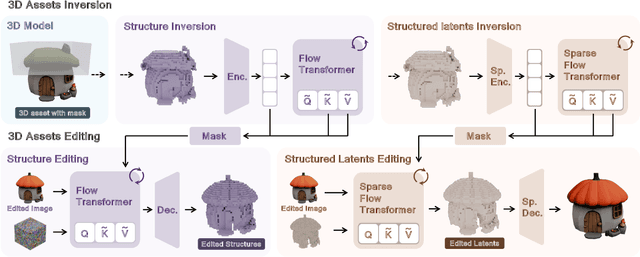
3D local editing of specified regions is crucial for game industry and robot interaction. Recent methods typically edit rendered multi-view images and then reconstruct 3D models, but they face challenges in precisely preserving unedited regions and overall coherence. Inspired by structured 3D generative models, we propose VoxHammer, a novel training-free approach that performs precise and coherent editing in 3D latent space. Given a 3D model, VoxHammer first predicts its inversion trajectory and obtains its inverted latents and key-value tokens at each timestep. Subsequently, in the denoising and editing phase, we replace the denoising features of preserved regions with the corresponding inverted latents and cached key-value tokens. By retaining these contextual features, this approach ensures consistent reconstruction of preserved areas and coherent integration of edited parts. To evaluate the consistency of preserved regions, we constructed Edit3D-Bench, a human-annotated dataset comprising hundreds of samples, each with carefully labeled 3D editing regions. Experiments demonstrate that VoxHammer significantly outperforms existing methods in terms of both 3D consistency of preserved regions and overall quality. Our method holds promise for synthesizing high-quality edited paired data, thereby laying the data foundation for in-context 3D generation. See our project page at https://huanngzh.github.io/VoxHammer-Page/.
AnimaX: Animating the Inanimate in 3D with Joint Video-Pose Diffusion Models
Jun 24, 2025We present AnimaX, a feed-forward 3D animation framework that bridges the motion priors of video diffusion models with the controllable structure of skeleton-based animation. Traditional motion synthesis methods are either restricted to fixed skeletal topologies or require costly optimization in high-dimensional deformation spaces. In contrast, AnimaX effectively transfers video-based motion knowledge to the 3D domain, supporting diverse articulated meshes with arbitrary skeletons. Our method represents 3D motion as multi-view, multi-frame 2D pose maps, and enables joint video-pose diffusion conditioned on template renderings and a textual motion prompt. We introduce shared positional encodings and modality-aware embeddings to ensure spatial-temporal alignment between video and pose sequences, effectively transferring video priors to motion generation task. The resulting multi-view pose sequences are triangulated into 3D joint positions and converted into mesh animation via inverse kinematics. Trained on a newly curated dataset of 160,000 rigged sequences, AnimaX achieves state-of-the-art results on VBench in generalization, motion fidelity, and efficiency, offering a scalable solution for category-agnostic 3D animation. Project page: \href{https://anima-x.github.io/}{https://anima-x.github.io/}.
Personalize Anything for Free with Diffusion Transformer
Mar 16, 2025



Personalized image generation aims to produce images of user-specified concepts while enabling flexible editing. Recent training-free approaches, while exhibit higher computational efficiency than training-based methods, struggle with identity preservation, applicability, and compatibility with diffusion transformers (DiTs). In this paper, we uncover the untapped potential of DiT, where simply replacing denoising tokens with those of a reference subject achieves zero-shot subject reconstruction. This simple yet effective feature injection technique unlocks diverse scenarios, from personalization to image editing. Building upon this observation, we propose \textbf{Personalize Anything}, a training-free framework that achieves personalized image generation in DiT through: 1) timestep-adaptive token replacement that enforces subject consistency via early-stage injection and enhances flexibility through late-stage regularization, and 2) patch perturbation strategies to boost structural diversity. Our method seamlessly supports layout-guided generation, multi-subject personalization, and mask-controlled editing. Evaluations demonstrate state-of-the-art performance in identity preservation and versatility. Our work establishes new insights into DiTs while delivering a practical paradigm for efficient personalization.
AGFSync: Leveraging AI-Generated Feedback for Preference Optimization in Text-to-Image Generation
Mar 24, 2024



Text-to-Image (T2I) diffusion models have achieved remarkable success in image generation. Despite their progress, challenges remain in both prompt-following ability, image quality and lack of high-quality datasets, which are essential for refining these models. As acquiring labeled data is costly, we introduce AGFSync, a framework that enhances T2I diffusion models through Direct Preference Optimization (DPO) in a fully AI-driven approach. AGFSync utilizes Vision-Language Models (VLM) to assess image quality across style, coherence, and aesthetics, generating feedback data within an AI-driven loop. By applying AGFSync to leading T2I models such as SD v1.4, v1.5, and SDXL, our extensive experiments on the TIFA dataset demonstrate notable improvements in VQA scores, aesthetic evaluations, and performance on the HPSv2 benchmark, consistently outperforming the base models. AGFSync's method of refining T2I diffusion models paves the way for scalable alignment techniques.
M$^3$Fair: Mitigating Bias in Healthcare Data through Multi-Level and Multi-Sensitive-Attribute Reweighting Method
Jun 07, 2023
In the data-driven artificial intelligence paradigm, models heavily rely on large amounts of training data. However, factors like sampling distribution imbalance can lead to issues of bias and unfairness in healthcare data. Sensitive attributes, such as race, gender, age, and medical condition, are characteristics of individuals that are commonly associated with discrimination or bias. In healthcare AI, these attributes can play a significant role in determining the quality of care that individuals receive. For example, minority groups often receive fewer procedures and poorer-quality medical care than white individuals in US. Therefore, detecting and mitigating bias in data is crucial to enhancing health equity. Bias mitigation methods include pre-processing, in-processing, and post-processing. Among them, Reweighting (RW) is a widely used pre-processing method that performs well in balancing machine learning performance and fairness performance. RW adjusts the weights for samples within each (group, label) combination, where these weights are utilized in loss functions. However, RW is limited to considering only a single sensitive attribute when mitigating bias and assumes that each sensitive attribute is equally important. This may result in potential inaccuracies when addressing intersectional bias. To address these limitations, we propose M3Fair, a multi-level and multi-sensitive-attribute reweighting method by extending the RW method to multiple sensitive attributes at multiple levels. Our experiments on real-world datasets show that the approach is effective, straightforward, and generalizable in addressing the healthcare fairness issues.