 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain Association-based Attacking and Shielding Natural Language Processing Systems
Nov 12, 2024



Association as a gift enables people do not have to mention something in completely straightforward words and allows others to understand what they intend to refer to. In this paper, we propose a chain association-based adversarial attack against natural language processing systems, utilizing the comprehension gap between humans and machines. We first generate a chain association graph for Chinese characters based on the association paradigm for building search space of potential adversarial examples. Then, we introduce an discrete particle swarm optimization algorithm to search for the optimal adversarial examples. We conduct comprehensive experiments and show that advanced natural language processing models and applications, including large language models, are vulnerable to our attack, while humans appear good at understanding the perturbed text. We also explore two methods, including adversarial training and associative graph-based recovery, to shield systems from chain association-based attack. Since a few examples that use some derogatory terms, this paper contains materials that may be offensive or upsetting to some people.
LLMs Can Evolve Continually on Modality for X-Modal Reasoning
Oct 26, 2024Multimodal Large Language Models (MLLMs) have gained significant attention due to their impressive capabilities in multimodal understanding. However, existing methods rely heavily on extensive modal-specific pretraining and joint-modal tuning, leading to significant computational burdens when expanding to new modalities. In this paper, we propose PathWeave, a flexible and scalable framework with modal-Path sWitching and ExpAnsion abilities that enables MLLMs to continually EVolve on modalities for $\mathbb{X}$-modal reasoning. We leverage the concept of Continual Learning and develop an incremental training strategy atop pre-trained MLLMs, enabling their expansion to new modalities using uni-modal data, without executing joint-modal pretraining. In detail, a novel Adapter-in-Adapter (AnA) framework is introduced, in which uni-modal and cross-modal adapters are seamlessly integrated to facilitate efficient modality alignment and collaboration. Additionally, an MoE-based gating module is applied between two types of adapters to further enhance the multimodal interaction. To investigate the proposed method, we establish a challenging benchmark called Continual Learning of Modality (MCL), which consists of high-quality QA data from five distinct modalities: image, video, audio, depth and point cloud. Extensive experiments demonstrate the effectiveness of the proposed AnA framework on learning plasticity and memory stability during continual learning. Furthermore, PathWeave performs comparably to state-of-the-art MLLMs while concurrently reducing parameter training burdens by 98.73%. Our code locates at https://github.com/JiazuoYu/PathWeave
A Comprehensive Survey of Datasets, Theories, Variants, and Applications in Direct Preference Optimization
Oct 21, 2024With the rapid advancement of large language models (LLMs), aligning policy models with human preferences has become increasingly critical. Direct Preference Optimization (DPO) has emerged as a promising approach for alignment, acting as an RL-free alternative to Reinforcement Learning from Human Feedback (RLHF). Despite DPO's various advancements and inherent limitations, an in-depth review of these aspects is currently lacking in the literature. In this work, we present a comprehensive review of the challenges and opportunities in DPO, covering theoretical analyses, variants, relevant preference datasets, and applications. Specifically, we categorize recent studies on DPO based on key research questions to provide a thorough understanding of DPO's current landscape. Additionally, we propose several future research directions to offer insights on model alignment for the research community.
GSSF: Generalized Structural Sparse Function for Deep Cross-modal Metric Learning
Oct 20, 2024Cross-modal metric learning is a prominent research topic that bridges the semantic heterogeneity between vision and language. Existing methods frequently utilize simple cosine or complex distance metrics to transform the pairwise features into a similarity score, which suffers from an inadequate or inefficient capability for distance measurements. Consequently, we propose a Generalized Structural Sparse Function to dynamically capture thorough and powerful relationships across modalities for pair-wise similarity learning while remaining concise but efficient. Specifically, the distance metric delicately encapsulates two formats of diagonal and block-diagonal terms, automatically distinguishing and highlighting the cross-channel relevancy and dependency inside a structured and organized topology. Hence, it thereby empowers itself to adapt to the optimal matching patterns between the paired features and reaches a sweet spot between model complexity and capability. Extensive experiments on cross-modal and two extra uni-modal retrieval tasks (image-text retrieval, person re-identification, fine-grained image retrieval) have validated its superiority and flexibility over various popular retrieval frameworks. More importantly, we further discover that it can be seamlessly incorporated into multiple application scenarios, and demonstrates promising prospects from Attention Mechanism to Knowledge Distillation in a plug-and-play manner. Our code is publicly available at: https://github.com/Paranioar/GSSF.
Y-Mol: A Multiscale Biomedical Knowledge-Guided Large Language Model for Drug Development
Oct 15, 2024Large Language Models (LLMs) have recently demonstrated remarkable performance in general tasks across various fields. However, their effectiveness within specific domains such as drug development remains challenges. To solve these challenges, we introduce \textbf{Y-Mol}, forming a well-established LLM paradigm for the flow of drug development. Y-Mol is a multiscale biomedical knowledge-guided LLM designed to accomplish tasks across lead compound discovery, pre-clinic, and clinic prediction. By integrating millions of multiscale biomedical knowledge and using LLaMA2 as the base LLM, Y-Mol augments the reasoning capability in the biomedical domain by learning from a corpus of publications, knowledge graphs, and expert-designed synthetic data. The capability is further enriched with three types of drug-oriented instructions: description-based prompts from processed publications, semantic-based prompts for extracting associations from knowledge graphs, and template-based prompts for understanding expert knowledge from biomedical tools. Besides, Y-Mol offers a set of LLM paradigms that can autonomously execute the downstream tasks across the entire process of drug development, including virtual screening, drug design, pharmacological properties prediction, and drug-related interaction prediction. Our extensive evaluations of various biomedical sources demonstrate that Y-Mol significantly outperforms general-purpose LLMs in discovering lead compounds, predicting molecular properties, and identifying drug interaction events.
AdvDiffuser: Generating Adversarial Safety-Critical Driving Scenarios via Guided Diffusion
Oct 11, 2024Safety-critical scenarios are infrequent in natural driving environments but hold significant importance for the training and testing of autonomous driving systems. The prevailing approach involves generating safety-critical scenarios automatically in simulation by introducing adversarial adjustments to natural environments. These adjustments are often tailored to specific tested systems, thereby disregarding their transferability across different systems. In this paper, we propose AdvDiffuser, an adversarial framework for generating safety-critical driving scenarios through guided diffusion. By incorporating a diffusion model to capture plausible collective behaviors of background vehicles and a lightweight guide model to effectively handle adversarial scenarios, AdvDiffuser facilitates transferability. Experimental results on the nuScenes dataset demonstrate that AdvDiffuser, trained on offline driving logs, can be applied to various tested systems with minimal warm-up episode data and outperform other existing methods in terms of realism, diversity, and adversarial performance.
Underwater Object Detection in the Era of Artificial Intelligence: Current, Challenge, and Future
Oct 08, 2024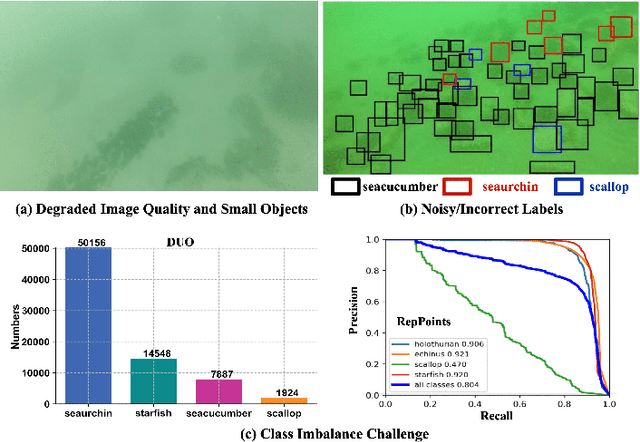

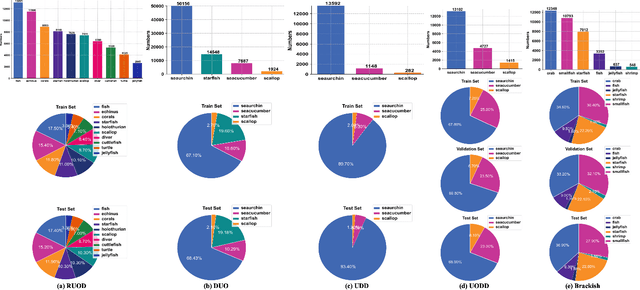
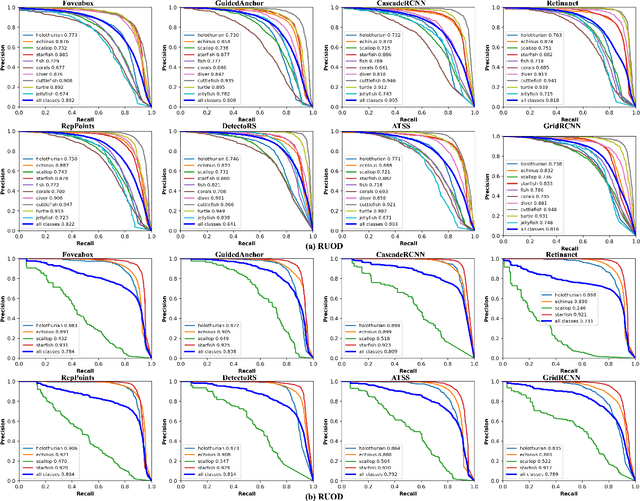
Underwater object detection (UOD), aiming to identify and localise the objects in underwater images or videos, presents significant challenges due to the optical distortion, water turbidity, and changing illumination in underwater scenes. In recent years, artificial intelligence (AI) based methods, especially deep learning methods, have shown promising performance in UOD. To further facilitate future advancements, we comprehensively study AI-based UOD. In this survey, we first categorise existing algorithms into traditional machine learning-based methods and deep learning-based methods, and summarise them by considering learning strategy, experimental dataset, utilised features or frameworks, and learning stage. Next, we discuss the potential challenges and suggest possible solutions and new directions. We also perform both quantitative and qualitative evaluations of mainstream algorithms across multiple benchmark datasets by considering the diverse and biased experimental setups. Finally, we introduce two off-the-shelf detection analysis tools, Diagnosis and TIDE, which well-examine the effects of object characteristics and various types of errors on detectors. These tools help identify the strengths and weaknesses of detectors, providing insigts for further improvement. The source codes, trained models, utilised datasets, detection results, and detection analysis tools are public available at \url{https://github.com/LongChenCV/UODReview}, and will be regularly updated.
Combing Text-based and Drag-based Editing for Precise and Flexible Image Editing
Oct 04, 2024



Precise and flexible image editing remains a fundamental challenge in computer vision. Based on the modified areas, most editing methods can be divided into two main types: global editing and local editing. In this paper, we choose the two most common editing approaches (ie text-based editing and drag-based editing) and analyze their drawbacks. Specifically, text-based methods often fail to describe the desired modifications precisely, while drag-based methods suffer from ambiguity. To address these issues, we proposed \textbf{CLIPDrag}, a novel image editing method that is the first to combine text and drag signals for precise and ambiguity-free manipulations on diffusion models. To fully leverage these two signals, we treat text signals as global guidance and drag points as local information. Then we introduce a novel global-local motion supervision method to integrate text signals into existing drag-based methods by adapting a pre-trained language-vision model like CLIP. Furthermore, we also address the problem of slow convergence in CLIPDrag by presenting a fast point-tracking method that enforces drag points moving toward correct directions. Extensive experiments demonstrate that CLIPDrag outperforms existing single drag-based methods or text-based methods.
Event-Customized Image Generation
Oct 03, 2024



Customized Image Generation, generating customized images with user-specified concepts, has raised significant attention due to its creativity and novelty. With impressive progress achieved in subject customization, some pioneer works further explored the customization of action and interaction beyond entity (i.e., human, animal, and object) appearance. However, these approaches only focus on basic actions and interactions between two entities, and their effects are limited by insufficient ''exactly same'' reference images. To extend customized image generation to more complex scenes for general real-world applications, we propose a new task: event-customized image generation. Given a single reference image, we define the ''event'' as all specific actions, poses, relations, or interactions between different entities in the scene. This task aims at accurately capturing the complex event and generating customized images with various target entities. To solve this task, we proposed a novel training-free event customization method: FreeEvent. Specifically, FreeEvent introduces two extra paths alongside the general diffusion denoising process: 1) Entity switching path: it applies cross-attention guidance and regulation for target entity generation. 2) Event transferring path: it injects the spatial feature and self-attention maps from the reference image to the target image for event generation. To further facilitate this new task, we collected two evaluation benchmarks: SWiG-Event and Real-Event. Extensive experiments and ablations have demonstrated the effectiveness of FreeEvent.
Large Language Model Aided Multi-objective Evolutionary Algorithm: a Low-cost Adaptive Approach
Oct 03, 2024Multi-objective optimization is a common problem in practical applications, and multi-objective evolutionary algorithm (MOEA) is considered as one of the effective methods to solve these problems. However, their randomness sometimes prevents algorithms from rapidly converging to global optimization, and the design of their genetic operators often requires complicated manual tuning. To overcome this challenge, this study proposes a new framework that combines a large language model (LLM) with traditional evolutionary algorithms to enhance the algorithm's search capability and generalization performance.In our framework, we employ adaptive and hybrid mechanisms to integrate the LLM with the MOEA, thereby accelerating algorithmic convergence. Specifically, we leverage an auxiliary evaluation function and automated prompt construction within the adaptive mechanism to flexibly adjust the utilization of the LLM, generating high-quality solutions that are further refined and optimized through genetic operators.Concurrently, the hybrid mechanism aims to minimize interaction costs with the LLM as much as possible.