 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMC-BERT: Efficient Language Pre-Training via a Meta Controller
Jun 16, 2020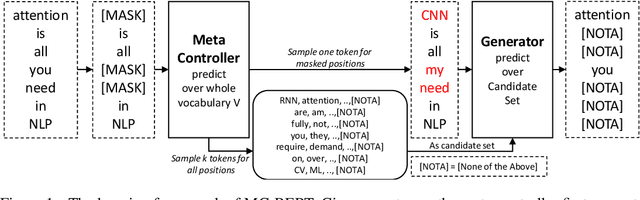

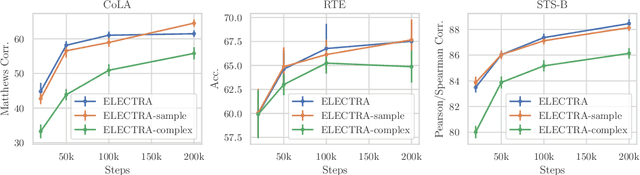

Pre-trained contextual representations (e.g., BERT) have become the foundation to achieve state-of-the-art results on many NLP tasks. However, large-scale pre-training is computationally expensive. ELECTRA, an early attempt to accelerate pre-training, trains a discriminative model that predicts whether each input token was replaced by a generator. Our studies reveal that ELECTRA's success is mainly due to its reduced complexity of the pre-training task: the binary classification (replaced token detection) is more efficient to learn than the generation task (masked language modeling). However, such a simplified task is less semantically informative. To achieve better efficiency and effectiveness, we propose a novel meta-learning framework, MC-BERT. The pre-training task is a multi-choice cloze test with a reject option, where a meta controller network provides training input and candidates. Results over GLUE natural language understanding benchmark demonstrate that our proposed method is both efficient and effective: it outperforms baselines on GLUE semantic tasks given the same computational budget.
Multi-modal Feature Fusion with Feature Attention for VATEX Captioning Challenge 2020
Jun 05, 2020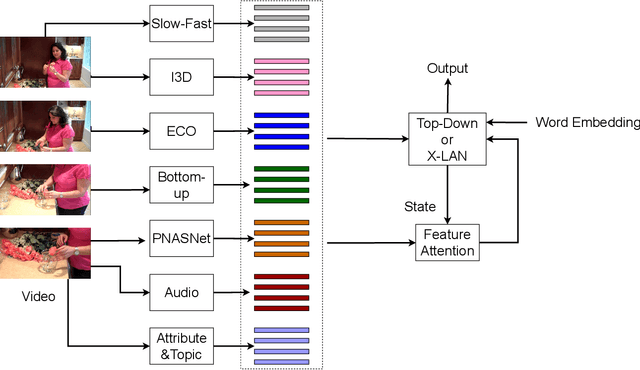

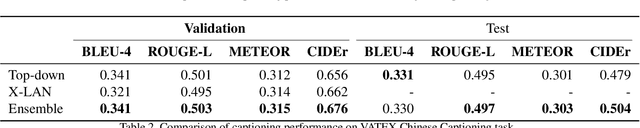
This report describes our model for VATEX Captioning Challenge 2020. First, to gather information from multiple domains, we extract motion, appearance, semantic and audio features. Then we design a feature attention module to attend on different feature when decoding. We apply two types of decoders, top-down and X-LAN and ensemble these models to get the final result. The proposed method outperforms official baseline with a significant gap. We achieve 76.0 CIDEr and 50.0 CIDEr on English and Chinese private test set. We rank 2nd on both English and Chinese private test leaderboard.
(Locally) Differentially Private Combinatorial Semi-Bandits
Jun 01, 2020
In this paper, we study Combinatorial Semi-Bandits (CSB) that is an extension of classic Multi-Armed Bandits (MAB) under Differential Privacy (DP) and stronger Local Differential Privacy (LDP) setting. Since the server receives more information from users in CSB, it usually causes additional dependence on the dimension of data, which is a notorious side-effect for privacy preserving learning. However for CSB under two common smoothness assumptions \cite{kveton2015tight,chen2016combinatorial}, we show it is possible to remove this side-effect. In detail, for $B_{\infty}$-bounded smooth CSB under either $\varepsilon$-LDP or $\varepsilon$-DP, we prove the optimal regret bound is $\Theta(\frac{mB^2_{\infty}\ln T } {\Delta\epsilon^2})$ or $\tilde{\Theta}(\frac{mB^2_{\infty}\ln T} { \Delta\epsilon})$ respectively, where $T$ is time period, $\Delta$ is the gap of rewards and $m$ is the number of base arms, by proposing novel algorithms and matching lower bounds. For $B_1$-bounded smooth CSB under $\varepsilon$-DP, we also prove the optimal regret bound is $\tilde{\Theta}(\frac{mKB^2_1\ln T} {\Delta\epsilon})$ with both upper bound and lower bound, where $K$ is the maximum number of feedback in each round. All above results nearly match corresponding non-private optimal rates, which imply there is no additional price for (locally) differentially private CSB in above common settings.
Locally Differentially Private (Contextual) Bandits Learning
Jun 01, 2020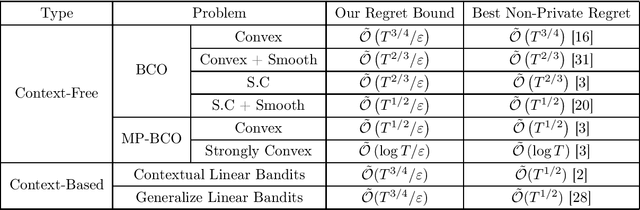
We study locally differentially private (LDP) bandits learning in this paper. First, we propose simple black-box reduction frameworks that can solve a large family of context-free bandits learning problems with LDP guarantee. Based on our frameworks, we can improve previous best results for private bandits learning with one-point feedback, such as private Bandits Convex Optimization etc, and obtain the first results for Bandits Convex Optimization (BCO) with multi-point feedback under LDP. LDP guarantee and black-box nature make our frameworks more attractive in real applications compared with previous specifically designed and relatively weaker differentially private (DP) context-free bandits algorithms. Further, we also extend our algorithm to Generalized Linear Bandits with regret bound $\tilde{\mathcal{O}}(T^{3/4}/\varepsilon)$ under $(\varepsilon, \delta)$-LDP which is conjectured to be optimal. Note given existing $\Omega(T)$ lower bound for DP contextual linear bandits (Shariff&Sheffe,NeurIPS2018), our result shows a fundamental difference between LDP and DP contextual bandits learning.
METASET: Exploring Shape and Property Spaces for Data-Driven Metamaterials Design
Jun 01, 2020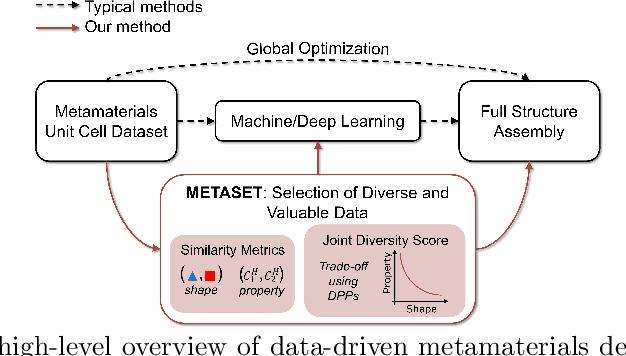



Data-driven design of mechanical metamaterials is an increasingly popular method to combat costly physical simulations and immense, often intractable, geometrical design spaces. Using a precomputed dataset of unit cells, a multiscale structure can be quickly filled via combinatorial search algorithms, and machine learning models can be trained to accelerate the process. However, the dependence on data induces a unique challenge: An imbalanced dataset containing more of certain shapes or physical properties than others can be detrimental to the efficacy of the approaches and any models built on those sets. In answer, we posit that a smaller yet diverse set of unit cells leads to scalable search and unbiased learning. To select such subsets, we propose METASET, a methodology that 1) uses similarity metrics and positive semi-definite kernels to jointly measure the closeness of unit cells in both shape and property spaces, and 2) incorporates Determinantal Point Processes for efficient subset selection. Moreover, METASET allows the trade-off between shape and property diversity so that subsets can be tuned for various applications. Through the design of 2D metamaterials with target displacement profiles, we demonstrate that smaller, diverse subsets can indeed improve the search process as well as structural performance. We also apply METASET to eliminate inherent overlaps in a dataset of 3D unit cells created with symmetry rules, distilling it down to the most unique families. Our diverse subsets are provided publicly for use by any designer.
Boosting Few-Shot Learning With Adaptive Margin Loss
May 28, 2020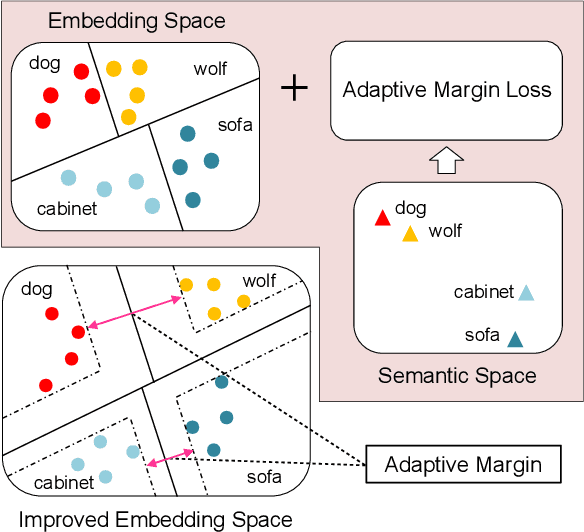
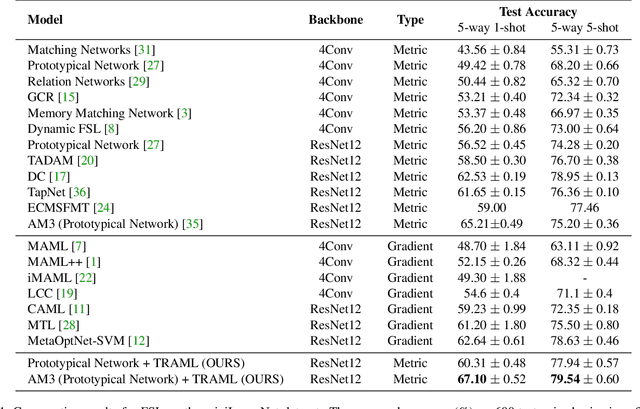
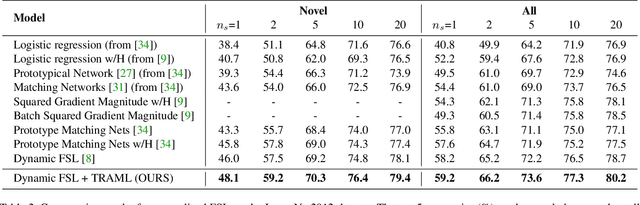
Few-shot learning (FSL) has attracted increasing attention in recent years but remains challenging, due to the intrinsic difficulty in learning to generalize from a few examples. This paper proposes an adaptive margin principle to improve the generalization ability of metric-based meta-learning approaches for few-shot learning problems. Specifically, we first develop a class-relevant additive margin loss, where semantic similarity between each pair of classes is considered to separate samples in the feature embedding space from similar classes. Further, we incorporate the semantic context among all classes in a sampled training task and develop a task-relevant additive margin loss to better distinguish samples from different classes. Our adaptive margin method can be easily extended to a more realistic generalized FSL setting. Extensive experiments demonstrate that the proposed method can boost the performance of current metric-based meta-learning approaches, under both the standard FSL and generalized FSL settings.
Improve bone age assessment by learning from anatomical local regions
May 27, 2020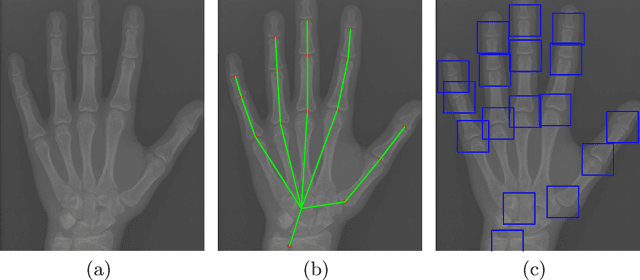

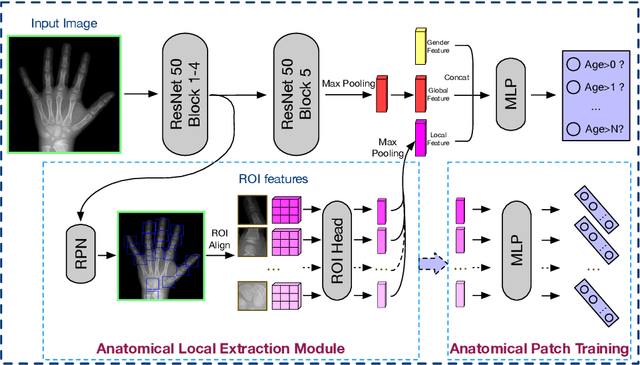
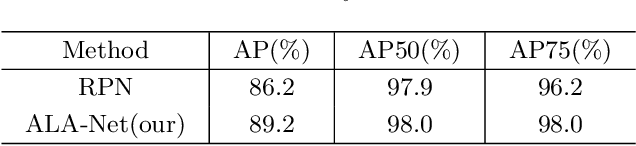
Skeletal bone age assessment (BAA), as an essential imaging examination, aims at evaluating the biological and structural maturation of human bones. In the clinical practice, Tanner and Whitehouse (TW2) method is a widely-used method for radiologists to perform BAA. The TW2 method splits the hands into Region Of Interests (ROI) and analyzes each of the anatomical ROI separately to estimate the bone age. Because of considering the analysis of local information, the TW2 method shows accurate results in practice. Following the spirit of TW2, we propose a novel model called Anatomical Local-Aware Network (ALA-Net) for automatic bone age assessment. In ALA-Net, anatomical local extraction module is introduced to learn the hand structure and extract local information. Moreover, we design an anatomical patch training strategy to provide extra regularization during the training process. Our model can detect the anatomical ROIs and estimate bone age jointly in an end-to-end manner. The experimental results show that our ALA-Net achieves a new state-of-the-art single model performance of 3.91 mean absolute error (MAE) on the public available RSNA dataset. Since the design of our model is well consistent with the well recognized TW2 method, it is interpretable and reliable for clinical usage.
MART: Memory-Augmented Recurrent Transformer for Coherent Video Paragraph Captioning
May 11, 2020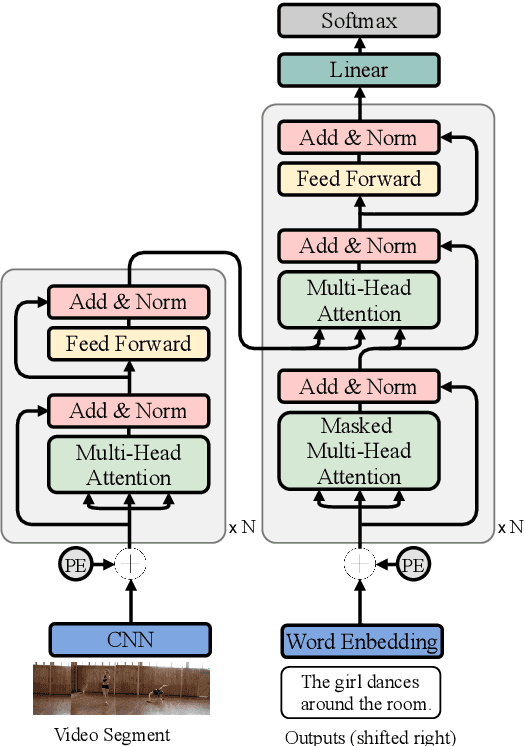
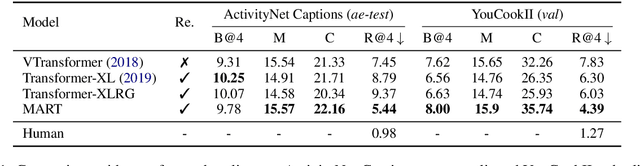
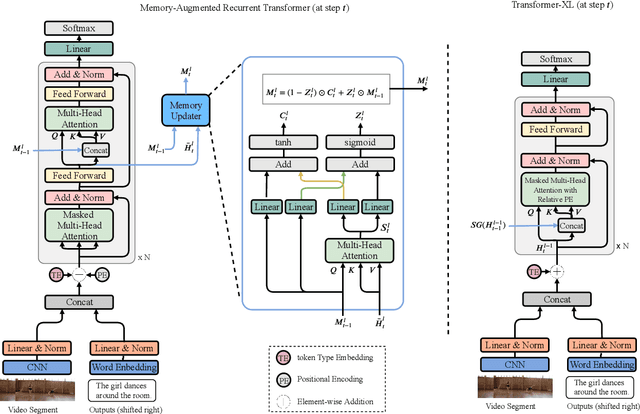
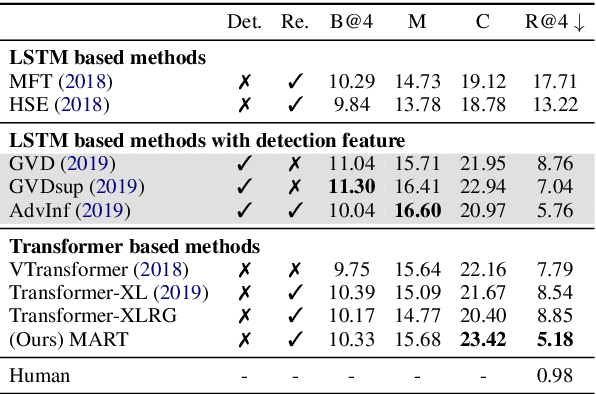
Generating multi-sentence descriptions for videos is one of the most challenging captioning tasks due to its high requirements for not only visual relevance but also discourse-based coherence across the sentences in the paragraph. Towards this goal, we propose a new approach called Memory-Augmented Recurrent Transformer (MART), which uses a memory module to augment the transformer architecture. The memory module generates a highly summarized memory state from the video segments and the sentence history so as to help better prediction of the next sentence (w.r.t. coreference and repetition aspects), thus encouraging coherent paragraph generation. Extensive experiments, human evaluations, and qualitative analyses on two popular datasets ActivityNet Captions and YouCookII show that MART generates more coherent and less repetitive paragraph captions than baseline methods, while maintaining relevance to the input video events. All code is available open-source at: https://github.com/jayleicn/recurrent-transformer
Memory Enhanced Global-Local Aggregation for Video Object Detection
Mar 26, 2020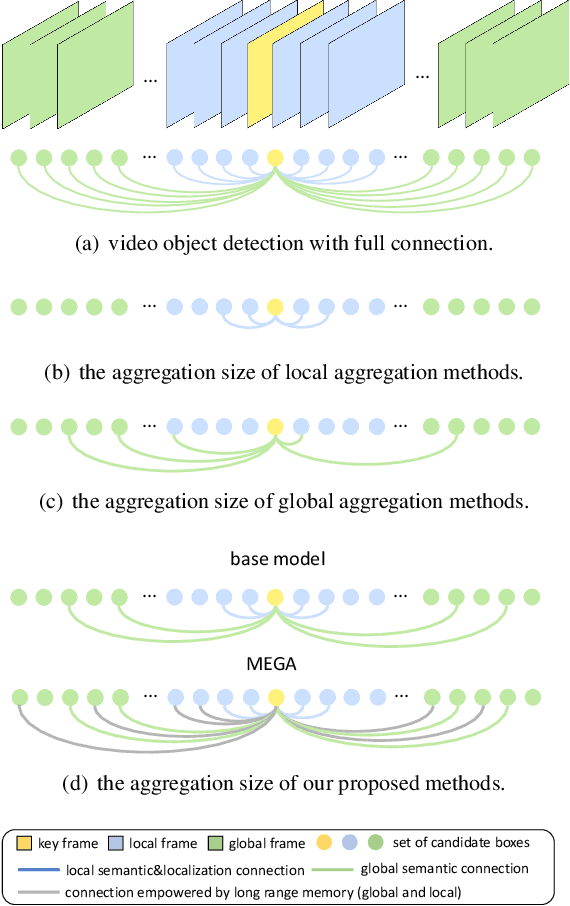
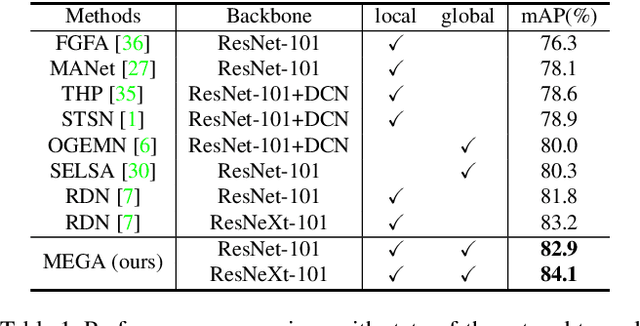
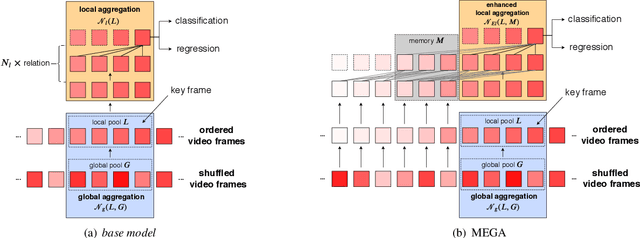
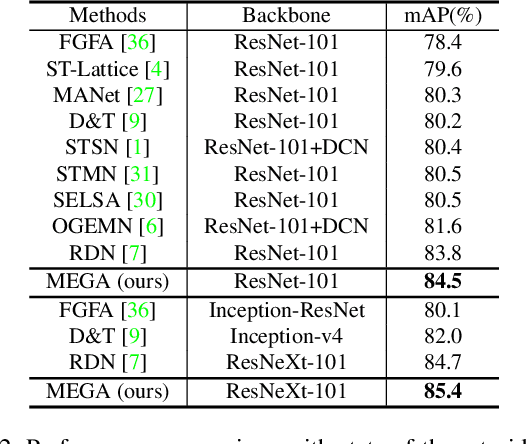
How do humans recognize an object in a piece of video? Due to the deteriorated quality of single frame, it may be hard for people to identify an occluded object in this frame by just utilizing information within one image. We argue that there are two important cues for humans to recognize objects in videos: the global semantic information and the local localization information. Recently, plenty of methods adopt the self-attention mechanisms to enhance the features in key frame with either global semantic information or local localization information. In this paper we introduce memory enhanced global-local aggregation (MEGA) network, which is among the first trials that takes full consideration of both global and local information. Furthermore, empowered by a novel and carefully-designed Long Range Memory (LRM) module, our proposed MEGA could enable the key frame to get access to much more content than any previous methods. Enhanced by these two sources of information, our method achieves state-of-the-art performance on ImageNet VID dataset. Code is available at \url{https://github.com/Scalsol/mega.pytorch}.
FocalMix: Semi-Supervised Learning for 3D Medical Image Detection
Mar 20, 2020
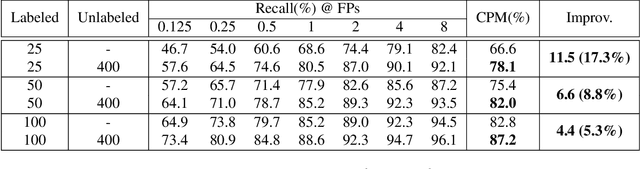
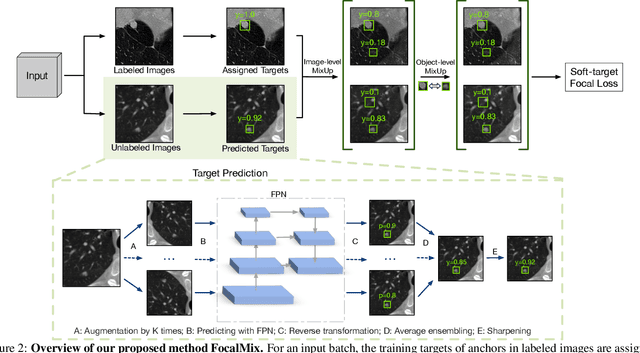
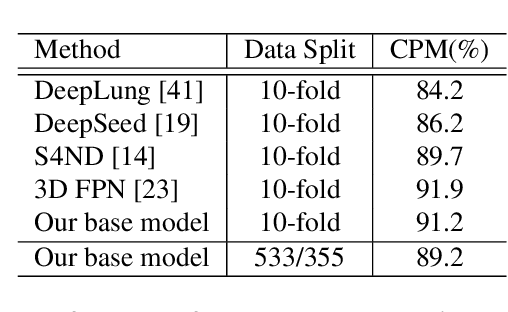
Applying artificial intelligence techniques in medical imaging is one of the most promising areas in medicine. However, most of the recent success in this area highly relies on large amounts of carefully annotated data, whereas annotating medical images is a costly process. In this paper, we propose a novel method, called FocalMix, which, to the best of our knowledge, is the first to leverage recent advances in semi-supervised learning (SSL) for 3D medical image detection. We conducted extensive experiments on two widely used datasets for lung nodule detection, LUNA16 and NLST. Results show that our proposed SSL methods can achieve a substantial improvement of up to 17.3% over state-of-the-art supervised learning approaches with 400 unlabeled CT scans.