 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurGS: Interactive Scene Modeling via Discrete-State Recurrent Gaussian Fusion
Dec 20, 2025Recent advances in 3D scene representations have enabled high-fidelity novel view synthesis, yet adapting to discrete scene changes and constructing interactive 3D environments remain open challenges in vision and robotics. Existing approaches focus solely on updating a single scene without supporting novel-state synthesis. Others rely on diffusion-based object-background decoupling that works on one state at a time and cannot fuse information across multiple observations. To address these limitations, we introduce RecurGS, a recurrent fusion framework that incrementally integrates discrete Gaussian scene states into a single evolving representation capable of interaction. RecurGS detects object-level changes across consecutive states, aligns their geometric motion using semantic correspondence and Lie-algebra based SE(3) refinement, and performs recurrent updates that preserve historical structures through replay supervision. A voxelized, visibility-aware fusion module selectively incorporates newly observed regions while keeping stable areas fixed, mitigating catastrophic forgetting and enabling efficient long-horizon updates. RecurGS supports object-level manipulation, synthesizes novel scene states without requiring additional scans, and maintains photorealistic fidelity across evolving environments. Extensive experiments across synthetic and real-world datasets demonstrate that our framework delivers high-quality reconstructions with substantially improved update efficiency, providing a scalable step toward continuously interactive Gaussian worlds.
Bandwidth-Efficient Adaptive Mixture-of-Experts via Low-Rank Compensation
Dec 18, 2025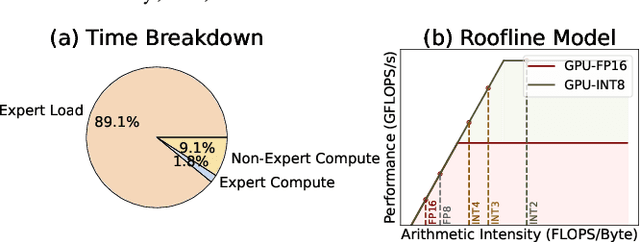

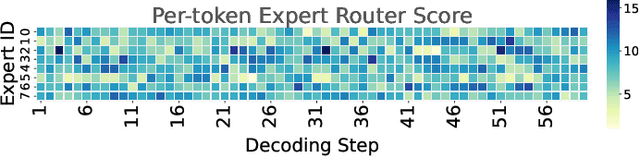
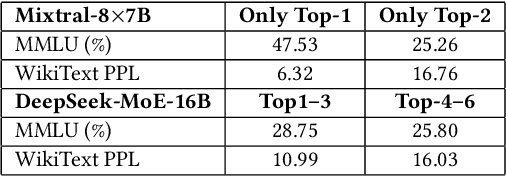
Mixture-of-Experts (MoE) models scale capacity via sparse activation but stress memory and bandwidth. Offloading alleviates GPU memory by fetching experts on demand, yet token-level routing causes irregular transfers that make inference I/O-bound. Static uniform quantization reduces traffic but degrades accuracy under aggressive compression by ignoring expert heterogeneity. We present Bandwidth-Efficient Adaptive Mixture-of-Experts via Low-Rank Compensation, which performs router-guided precision restoration using precomputed low-rank compensators. At inference time, our method transfers compact low-rank factors with Top-n (n<k) experts per token and applies compensation to them, keeping others low-bit. Integrated with offloading on GPU and GPU-NDP systems, our method delivers a superior bandwidth-accuracy trade-off and improved throughput.
SparseST: Exploiting Data Sparsity in Spatiotemporal Modeling and Prediction
Nov 18, 2025Spatiotemporal data mining (STDM) has a wide range of applications in various complex physical systems (CPS), i.e., transportation, manufacturing, healthcare, etc. Among all the proposed methods, the Convolutional Long Short-Term Memory (ConvLSTM) has proved to be generalizable and extendable in different applications and has multiple variants achieving state-of-the-art performance in various STDM applications. However, ConvLSTM and its variants are computationally expensive, which makes them inapplicable in edge devices with limited computational resources. With the emerging need for edge computing in CPS, efficient AI is essential to reduce the computational cost while preserving the model performance. Common methods of efficient AI are developed to reduce redundancy in model capacity (i.e., model pruning, compression, etc.). However, spatiotemporal data mining naturally requires extensive model capacity, as the embedded dependencies in spatiotemporal data are complex and hard to capture, which limits the model redundancy. Instead, there is a fairly high level of data and feature redundancy that introduces an unnecessary computational burden, which has been largely overlooked in existing research. Therefore, we developed a novel framework SparseST, that pioneered in exploiting data sparsity to develop an efficient spatiotemporal model. In addition, we explore and approximate the Pareto front between model performance and computational efficiency by designing a multi-objective composite loss function, which provides a practical guide for practitioners to adjust the model according to computational resource constraints and the performance requirements of downstream tasks.
SciAgent: A Unified Multi-Agent System for Generalistic Scientific Reasoning
Nov 17, 2025Recent advances in large language models have enabled AI systems to achieve expert-level performance on domain-specific scientific tasks, yet these systems remain narrow and handcrafted. We introduce SciAgent, a unified multi-agent system designed for generalistic scientific reasoning-the ability to adapt reasoning strategies across disciplines and difficulty levels. SciAgent organizes problem solving as a hierarchical process: a Coordinator Agent interprets each problem's domain and complexity, dynamically orchestrating specialized Worker Systems, each composed of interacting reasoning Sub-agents for symbolic deduction, conceptual modeling, numerical computation, and verification. These agents collaboratively assemble and refine reasoning pipelines tailored to each task. Across mathematics and physics Olympiads (IMO, IMC, IPhO, CPhO), SciAgent consistently attains or surpasses human gold-medalist performance, demonstrating both domain generality and reasoning adaptability. Additionally, SciAgent has been tested on the International Chemistry Olympiad (IChO) and selected problems from the Humanity's Last Exam (HLE) benchmark, further confirming the system's ability to generalize across diverse scientific domains. This work establishes SciAgent as a concrete step toward generalistic scientific intelligence-AI systems capable of coherent, cross-disciplinary reasoning at expert levels.
Remodeling Semantic Relationships in Vision-Language Fine-Tuning
Nov 13, 2025



Vision-language fine-tuning has emerged as an efficient paradigm for constructing multimodal foundation models. While textual context often highlights semantic relationships within an image, existing fine-tuning methods typically overlook this information when aligning vision and language, thus leading to suboptimal performance. Toward solving this problem, we propose a method that can improve multimodal alignment and fusion based on both semantics and relationships.Specifically, we first extract multilevel semantic features from different vision encoder to capture more visual cues of the relationships. Then, we learn to project the vision features to group related semantics, among which are more likely to have relationships. Finally, we fuse the visual features with the textual by using inheritable cross-attention, where we globally remove the redundant visual relationships by discarding visual-language feature pairs with low correlation. We evaluate our proposed method on eight foundation models and two downstream tasks, visual question answering and image captioning, and show that it outperforms all existing methods.
Exploring Category-level Articulated Object Pose Tracking on SE(3) Manifolds
Nov 08, 2025Articulated objects are prevalent in daily life and robotic manipulation tasks. However, compared to rigid objects, pose tracking for articulated objects remains an underexplored problem due to their inherent kinematic constraints. To address these challenges, this work proposes a novel point-pair-based pose tracking framework, termed \textbf{PPF-Tracker}. The proposed framework first performs quasi-canonicalization of point clouds in the SE(3) Lie group space, and then models articulated objects using Point Pair Features (PPF) to predict pose voting parameters by leveraging the invariance properties of SE(3). Finally, semantic information of joint axes is incorporated to impose unified kinematic constraints across all parts of the articulated object. PPF-Tracker is systematically evaluated on both synthetic datasets and real-world scenarios, demonstrating strong generalization across diverse and challenging environments. Experimental results highlight the effectiveness and robustness of PPF-Tracker in multi-frame pose tracking of articulated objects. We believe this work can foster advances in robotics, embodied intelligence, and augmented reality. Codes are available at https://github.com/mengxh20/PPFTracker.
Multi-Task Vehicle Routing Solver via Mixture of Specialized Experts under State-Decomposable MDP
Oct 24, 2025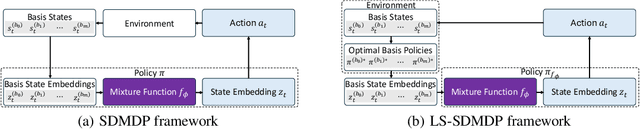
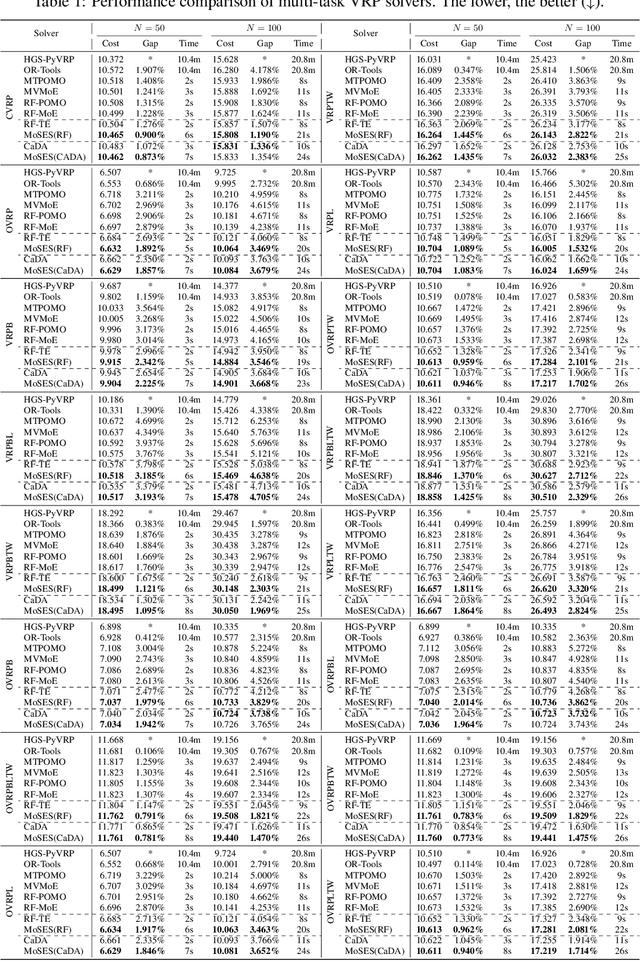
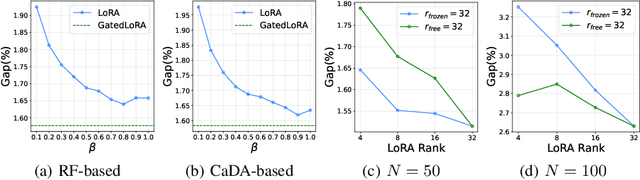
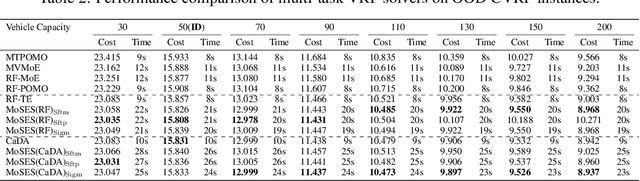
Existing neural methods for multi-task vehicle routing problems (VRPs) typically learn unified solvers to handle multiple constraints simultaneously. However, they often underutilize the compositional structure of VRP variants, each derivable from a common set of basis VRP variants. This critical oversight causes unified solvers to miss out the potential benefits of basis solvers, each specialized for a basis VRP variant. To overcome this limitation, we propose a framework that enables unified solvers to perceive the shared-component nature across VRP variants by proactively reusing basis solvers, while mitigating the exponential growth of trained neural solvers. Specifically, we introduce a State-Decomposable MDP (SDMDP) that reformulates VRPs by expressing the state space as the Cartesian product of basis state spaces associated with basis VRP variants. More crucially, this formulation inherently yields the optimal basis policy for each basis VRP variant. Furthermore, a Latent Space-based SDMDP extension is developed by incorporating both the optimal basis policies and a learnable mixture function to enable the policy reuse in the latent space. Under mild assumptions, this extension provably recovers the optimal unified policy of SDMDP through the mixture function that computes the state embedding as a mapping from the basis state embeddings generated by optimal basis policies. For practical implementation, we introduce the Mixture-of-Specialized-Experts Solver (MoSES), which realizes basis policies through specialized Low-Rank Adaptation (LoRA) experts, and implements the mixture function via an adaptive gating mechanism. Extensive experiments conducted across VRP variants showcase the superiority of MoSES over prior methods.
IMAGINE: Integrating Multi-Agent System into One Model for Complex Reasoning and Planning
Oct 16, 2025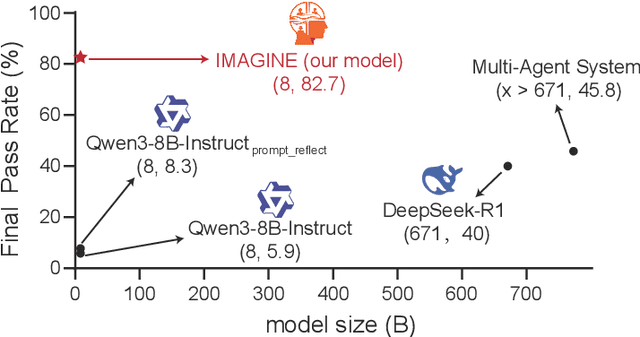
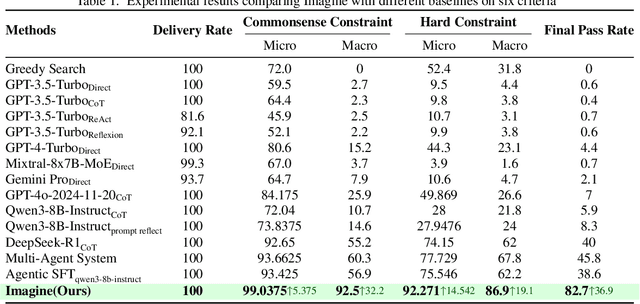
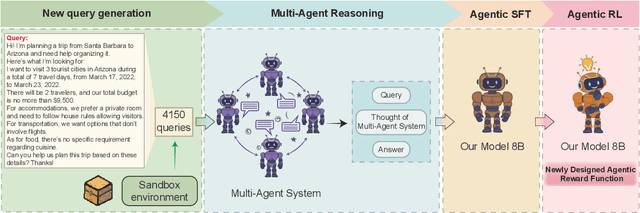

Although large language models (LLMs) have made significant strides across various tasks, they still face significant challenges in complex reasoning and planning. For example, even with carefully designed prompts and prior information explicitly provided, GPT-4o achieves only a 7% Final Pass Rate on the TravelPlanner dataset in the sole-planning mode. Similarly, even in the thinking mode, Qwen3-8B-Instruct and DeepSeek-R1-671B, only achieve Final Pass Rates of 5.9% and 40%, respectively. Although well-organized Multi-Agent Systems (MAS) can offer improved collective reasoning, they often suffer from high reasoning costs due to multi-round internal interactions, long per-response latency, and difficulties in end-to-end training. To address these challenges, we propose a general and scalable framework called IMAGINE, short for Integrating Multi-Agent System into One Model. This framework not only integrates the reasoning and planning capabilities of MAS into a single, compact model, but also significantly surpass the capabilities of the MAS through a simple end-to-end training. Through this pipeline, a single small-scale model is not only able to acquire the structured reasoning and planning capabilities of a well-organized MAS but can also significantly outperform it. Experimental results demonstrate that, when using Qwen3-8B-Instruct as the base model and training it with our method, the model achieves an 82.7% Final Pass Rate on the TravelPlanner benchmark, far exceeding the 40% of DeepSeek-R1-671B, while maintaining a much smaller model size.
MorphoBench: A Benchmark with Difficulty Adaptive to Model Reasoning
Oct 16, 2025

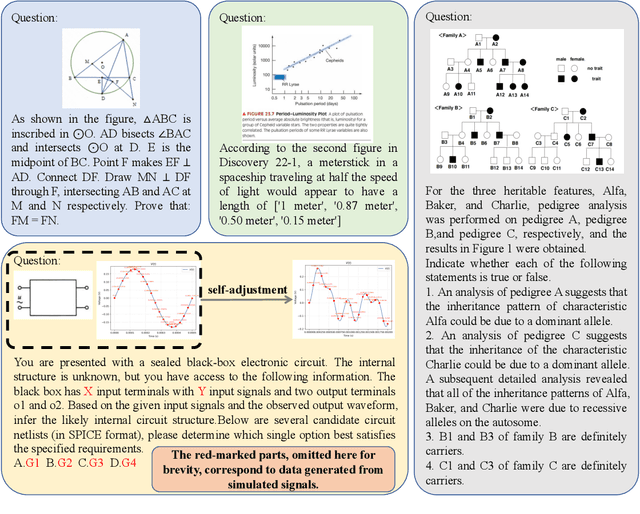
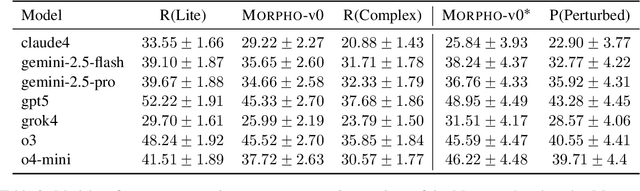
With the advancement of powerful large-scale reasoning models, effectively evaluating the reasoning capabilities of these models has become increasingly important. However, existing benchmarks designed to assess the reasoning abilities of large models tend to be limited in scope and lack the flexibility to adapt their difficulty according to the evolving reasoning capacities of the models. To address this, we propose MorphoBench, a benchmark that incorporates multidisciplinary questions to evaluate the reasoning capabilities of large models and can adjust and update question difficulty based on the reasoning abilities of advanced models. Specifically, we curate the benchmark by selecting and collecting complex reasoning questions from existing benchmarks and sources such as Olympiad-level competitions. Additionally, MorphoBench adaptively modifies the analytical challenge of questions by leveraging key statements generated during the model's reasoning process. Furthermore, it includes questions generated using simulation software, enabling dynamic adjustment of benchmark difficulty with minimal resource consumption. We have gathered over 1,300 test questions and iteratively adjusted the difficulty of MorphoBench based on the reasoning capabilities of models such as o3 and GPT-5. MorphoBench enhances the comprehensiveness and validity of model reasoning evaluation, providing reliable guidance for improving both the reasoning abilities and scientific robustness of large models. The code has been released in https://github.com/OpenDCAI/MorphoBench.
DiffVL: Diffusion-Based Visual Localization on 2D Maps via BEV-Conditioned GPS Denoising
Sep 18, 2025



Accurate visual localization is crucial for autonomous driving, yet existing methods face a fundamental dilemma: While high-definition (HD) maps provide high-precision localization references, their costly construction and maintenance hinder scalability, which drives research toward standard-definition (SD) maps like OpenStreetMap. Current SD-map-based approaches primarily focus on Bird's-Eye View (BEV) matching between images and maps, overlooking a ubiquitous signal-noisy GPS. Although GPS is readily available, it suffers from multipath errors in urban environments. We propose DiffVL, the first framework to reformulate visual localization as a GPS denoising task using diffusion models. Our key insight is that noisy GPS trajectory, when conditioned on visual BEV features and SD maps, implicitly encode the true pose distribution, which can be recovered through iterative diffusion refinement. DiffVL, unlike prior BEV-matching methods (e.g., OrienterNet) or transformer-based registration approaches, learns to reverse GPS noise perturbations by jointly modeling GPS, SD map, and visual signals, achieving sub-meter accuracy without relying on HD maps. Experiments on multiple datasets demonstrate that our method achieves state-of-the-art accuracy compared to BEV-matching baselines. Crucially, our work proves that diffusion models can enable scalable localization by treating noisy GPS as a generative prior-making a paradigm shift from traditional matching-based methods.