 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBandwidth-Efficient Adaptive Mixture-of-Experts via Low-Rank Compensation
Dec 18, 2025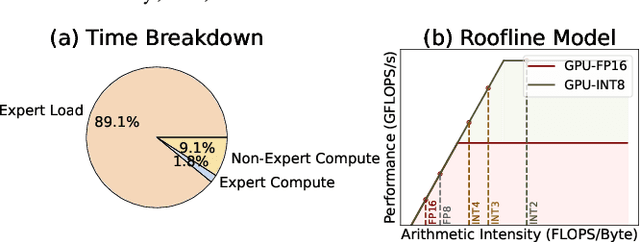

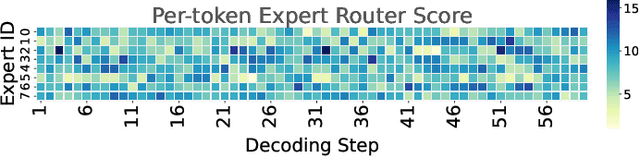
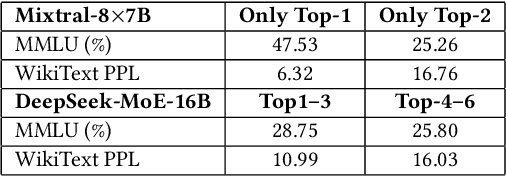
Mixture-of-Experts (MoE) models scale capacity via sparse activation but stress memory and bandwidth. Offloading alleviates GPU memory by fetching experts on demand, yet token-level routing causes irregular transfers that make inference I/O-bound. Static uniform quantization reduces traffic but degrades accuracy under aggressive compression by ignoring expert heterogeneity. We present Bandwidth-Efficient Adaptive Mixture-of-Experts via Low-Rank Compensation, which performs router-guided precision restoration using precomputed low-rank compensators. At inference time, our method transfers compact low-rank factors with Top-n (n<k) experts per token and applies compensation to them, keeping others low-bit. Integrated with offloading on GPU and GPU-NDP systems, our method delivers a superior bandwidth-accuracy trade-off and improved throughput.
Sparse Attention Remapping with Clustering for Efficient LLM Decoding on PIM
May 09, 2025Transformer-based models are the foundation of modern machine learning, but their execution, particularly during autoregressive decoding in large language models (LLMs), places significant pressure on memory systems due to frequent memory accesses and growing key-value (KV) caches. This creates a bottleneck in memory bandwidth, especially as context lengths increase. Processing-in-memory (PIM) architectures are a promising solution, offering high internal bandwidth and compute parallelism near memory. However, current PIM designs are primarily optimized for dense attention and struggle with the dynamic, irregular access patterns introduced by modern KV cache sparsity techniques. Consequently, they suffer from workload imbalance, reducing throughput and resource utilization. In this work, we propose STARC, a novel sparsity-optimized data mapping scheme tailored specifically for efficient LLM decoding on PIM architectures. STARC clusters KV pairs by semantic similarity and maps them to contiguous memory regions aligned with PIM bank structures. During decoding, queries retrieve relevant tokens at cluster granularity by matching against precomputed centroids, enabling selective attention and parallel processing without frequent reclustering or data movement overhead. Experiments on the HBM-PIM system show that, compared to common token-wise sparsity methods, STARC reduces attention-layer latency by 19%--31% and energy consumption by 19%--27%. Under a KV cache budget of 1024, it achieves up to 54%--74% latency reduction and 45%--67% energy reduction compared to full KV cache retrieval. Meanwhile, STARC maintains model accuracy comparable to state-of-the-art sparse attention methods, demonstrating its effectiveness in enabling efficient and hardware-friendly long-context LLM inference on PIM architectures.