 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivileged Knowledge Distillation for Online Action Detection
Dec 03, 2020

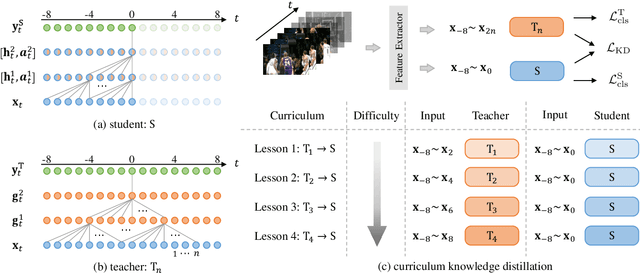
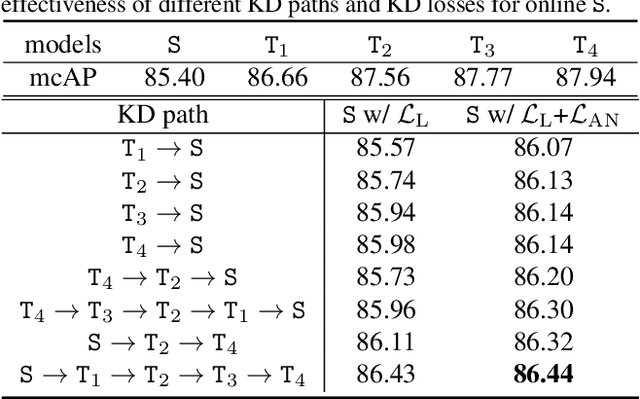
Online Action Detection (OAD) in videos is proposed as a per-frame labeling task to address the real-time prediction tasks that can only obtain the previous and current video frames. This paper presents a novel learning-with-privileged based framework for online action detection where the future frames only observable at the training stages are considered as a form of privileged information. Knowledge distillation is employed to transfer the privileged information from the offline teacher to the online student. We note that this setting is different from conventional KD because the difference between the teacher and student models mostly lies in input data rather than the network architecture. We propose Privileged Knowledge Distillation (PKD) which (i) schedules a curriculum learning procedure and (ii) inserts auxiliary nodes to the student model, both for shrinking the information gap and improving learning performance. Compared to other OAD methods that explicitly predict future frames, our approach avoids learning unpredictable unnecessary yet inconsistent visual contents and achieves state-of-the-art accuracy on two popular OAD benchmarks, TVSeries and THUMOS14.
Batch Normalization with Enhanced Linear Transformation
Nov 28, 2020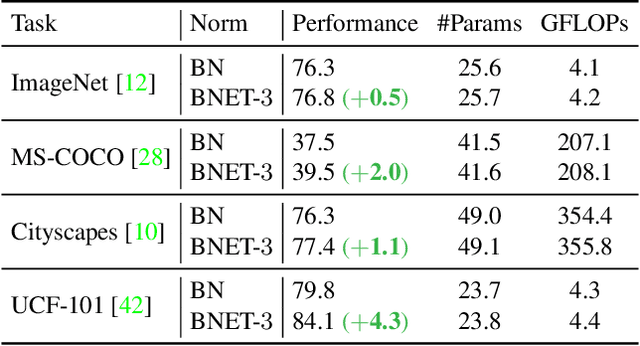
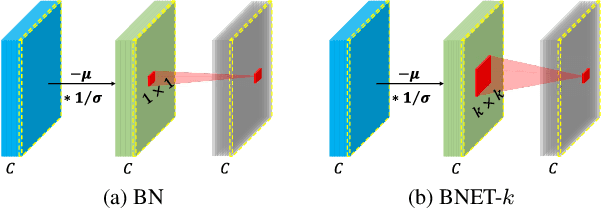
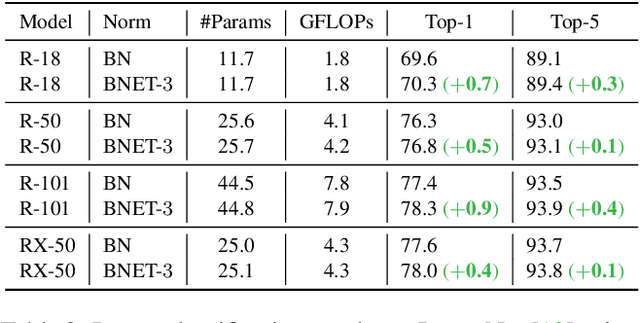
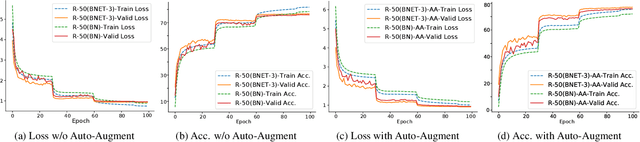
Batch normalization (BN) is a fundamental unit in modern deep networks, in which a linear transformation module was designed for improving BN's flexibility of fitting complex data distributions. In this paper, we demonstrate properly enhancing this linear transformation module can effectively improve the ability of BN. Specifically, rather than using a single neuron, we propose to additionally consider each neuron's neighborhood for calculating the outputs of the linear transformation. Our method, named BNET, can be implemented with 2-3 lines of code in most deep learning libraries. Despite the simplicity, BNET brings consistent performance gains over a wide range of backbones and visual benchmarks. Moreover, we verify that BNET accelerates the convergence of network training and enhances spatial information by assigning the important neurons with larger weights accordingly. The code is available at https://github.com/yuhuixu1993/BNET.
Omni-GAN: On the Secrets of cGANs and Beyond
Nov 26, 2020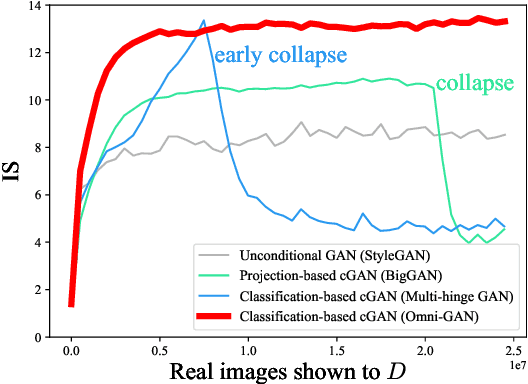
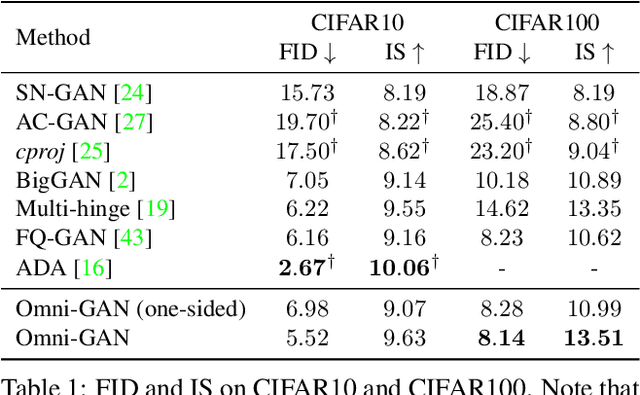
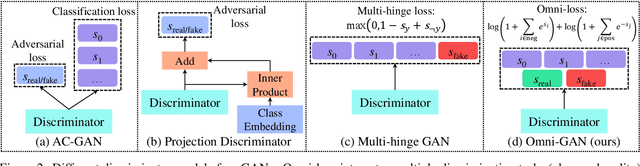
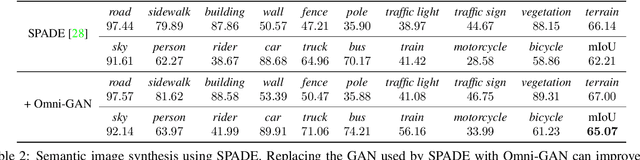
It has been an important problem to design a proper discriminator for conditional generative adversarial networks (cGANs). In this paper, we investigate two popular choices, the projection-based and classification-based discriminators, and reveal that both of them suffer some kind of drawbacks that affect the learning ability of cGANs. Then, we present our solution that trains a powerful discriminator and avoids over-fitting with regularization. In addition, we unify multiple targets (class, domain, reality, etc.) into one loss function to enable a wider range of applications. Our algorithm, named \textbf{Omni-GAN}, achieves competitive performance on a few popular benchmarks. More importantly, Omni-GAN enjoys both high generation quality and low risks in mode collapse, offering new possibilities for optimizing cGANs.Code is available at \url{https://github.com/PeterouZh/Omni-GAN-PyTorch}.
Heterogeneous Contrastive Learning: Encoding Spatial Information for Compact Visual Representations
Nov 19, 2020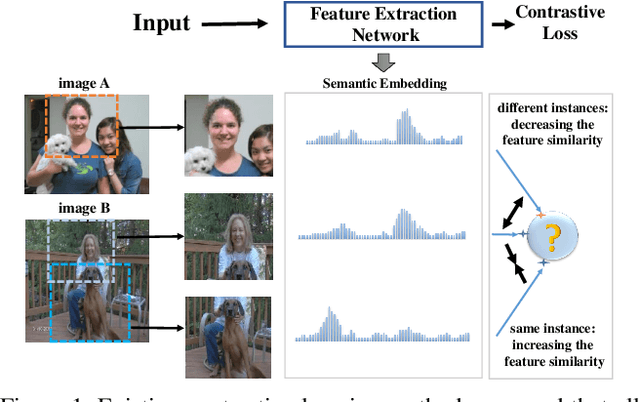
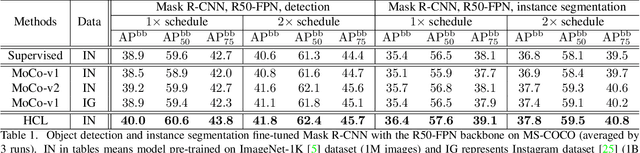
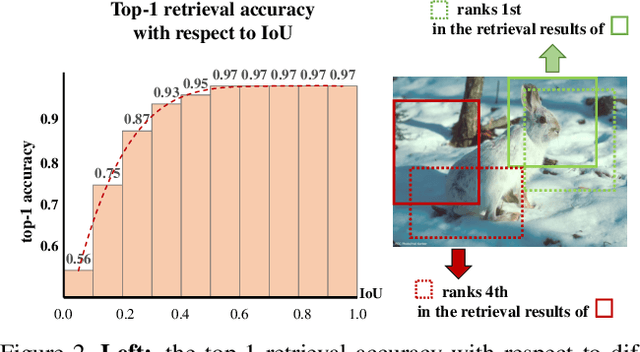
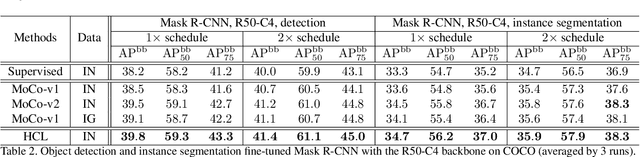
Contrastive learning has achieved great success in self-supervised visual representation learning, but existing approaches mostly ignored spatial information which is often crucial for visual representation. This paper presents heterogeneous contrastive learning (HCL), an effective approach that adds spatial information to the encoding stage to alleviate the learning inconsistency between the contrastive objective and strong data augmentation operations. We demonstrate the effectiveness of HCL by showing that (i) it achieves higher accuracy in instance discrimination and (ii) it surpasses existing pre-training methods in a series of downstream tasks while shrinking the pre-training costs by half. More importantly, we show that our approach achieves higher efficiency in visual representations, and thus delivers a key message to inspire the future research of self-supervised visual representation learning.
Can Semantic Labels Assist Self-Supervised Visual Representation Learning?
Nov 17, 2020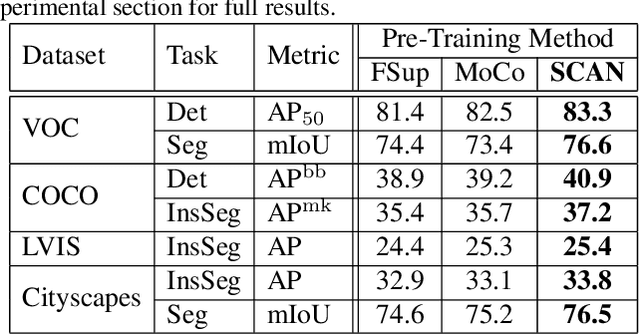

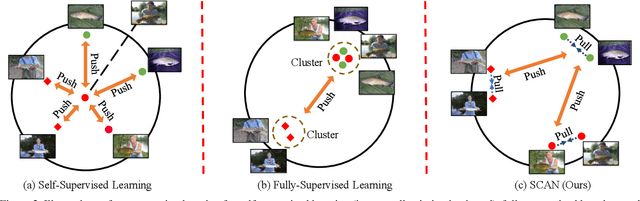
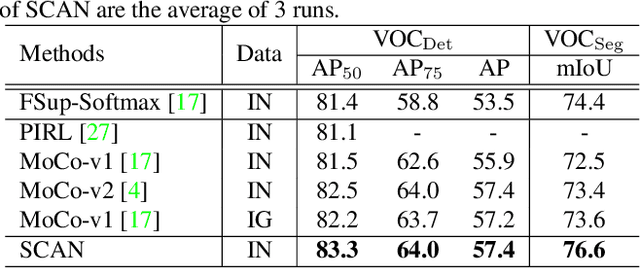
Recently, contrastive learning has largely advanced the progress of unsupervised visual representation learning. Pre-trained on ImageNet, some self-supervised algorithms reported higher transfer learning performance compared to fully-supervised methods, seeming to deliver the message that human labels hardly contribute to learning transferrable visual features. In this paper, we defend the usefulness of semantic labels but point out that fully-supervised and self-supervised methods are pursuing different kinds of features. To alleviate this issue, we present a new algorithm named Supervised Contrastive Adjustment in Neighborhood (SCAN) that maximally prevents the semantic guidance from damaging the appearance feature embedding. In a series of downstream tasks, SCAN achieves superior performance compared to previous fully-supervised and self-supervised methods, and sometimes the gain is significant. More importantly, our study reveals that semantic labels are useful in assisting self-supervised methods, opening a new direction for the community.
One-bit Supervision for Image Classification
Sep 16, 2020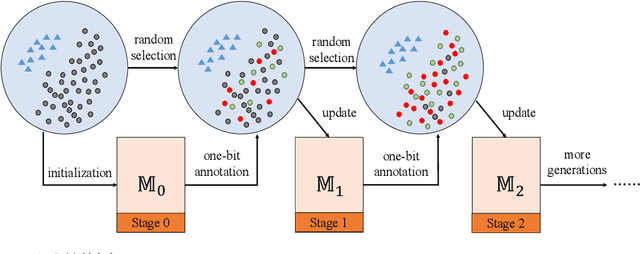

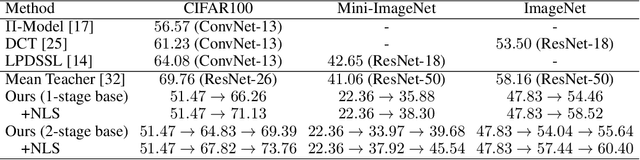
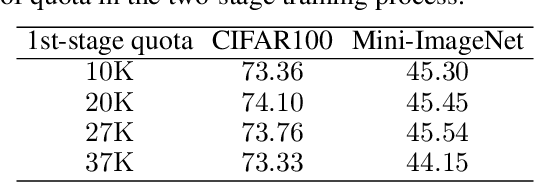
This paper presents one-bit supervision, a novel setting of learning from incomplete annotations, in the scenario of image classification. Instead of training a model upon the accurate label of each sample, our setting requires the model to query with a predicted label of each sample and learn from the answer whether the guess is correct. This provides one bit (yes or no) of information, and more importantly, annotating each sample becomes much easier than finding the accurate label from many candidate classes. There are two keys to training a model upon one-bit supervision: improving the guess accuracy and making use of incorrect guesses. For these purposes, we propose a multi-stage training paradigm which incorporates negative label suppression into an off-the-shelf semi-supervised learning algorithm. In three popular image classification benchmarks, our approach claims higher efficiency in utilizing the limited amount of annotations.
Reinforced Axial Refinement Network for Monocular 3D Object Detection
Aug 31, 2020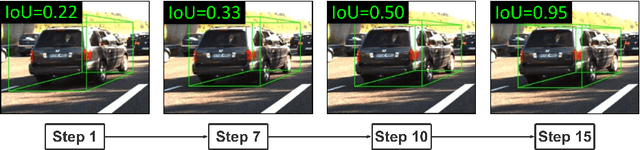
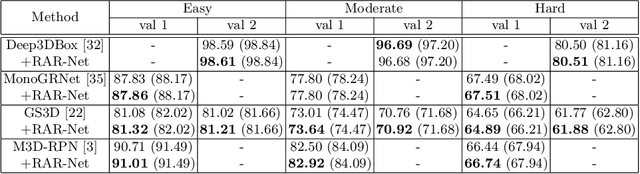
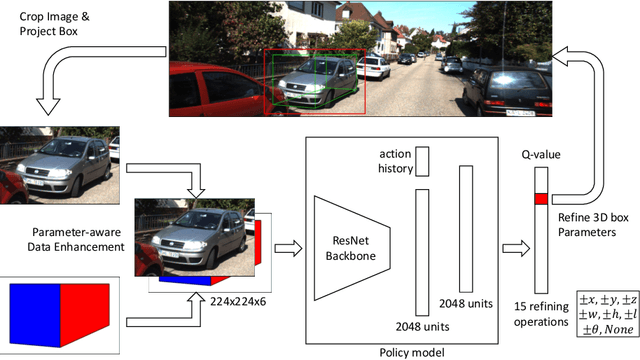
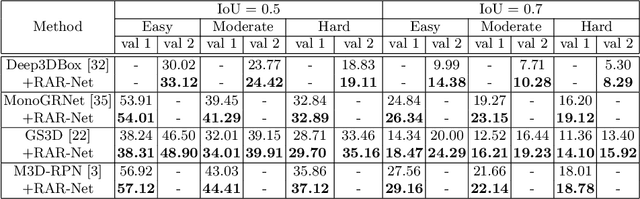
Monocular 3D object detection aims to extract the 3D position and properties of objects from a 2D input image. This is an ill-posed problem with a major difficulty lying in the information loss by depth-agnostic cameras. Conventional approaches sample 3D bounding boxes from the space and infer the relationship between the target object and each of them, however, the probability of effective samples is relatively small in the 3D space. To improve the efficiency of sampling, we propose to start with an initial prediction and refine it gradually towards the ground truth, with only one 3d parameter changed in each step. This requires designing a policy which gets a reward after several steps, and thus we adopt reinforcement learning to optimize it. The proposed framework, Reinforced Axial Refinement Network (RAR-Net), serves as a post-processing stage which can be freely integrated into existing monocular 3D detection methods, and improve the performance on the KITTI dataset with small extra computational costs.
Weight-Sharing Neural Architecture Search: A Battle to Shrink the Optimization Gap
Aug 05, 2020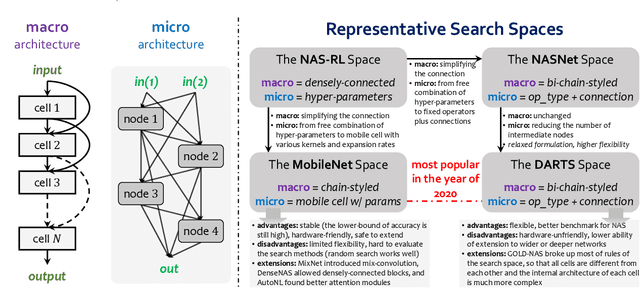
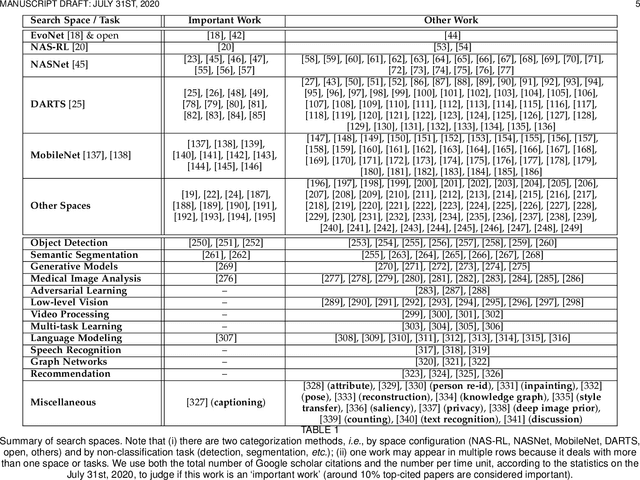
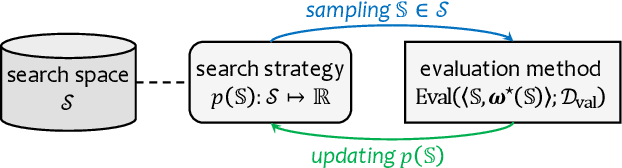
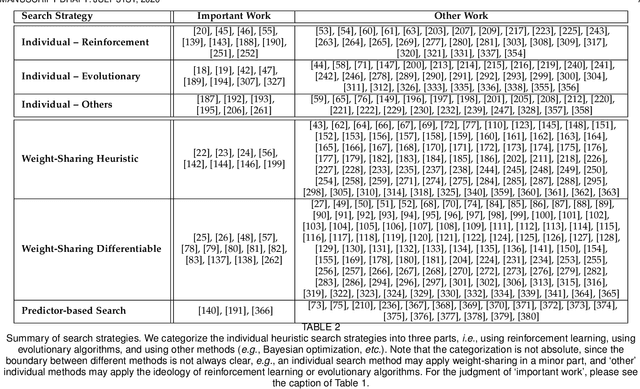
Neural architecture search (NAS) has attracted increasing attentions in both academia and industry. In the early age, researchers mostly applied individual search methods which sample and evaluate the candidate architectures separately and thus incur heavy computational overheads. To alleviate the burden, weight-sharing methods were proposed in which exponentially many architectures share weights in the same super-network, and the costly training procedure is performed only once. These methods, though being much faster, often suffer the issue of instability. This paper provides a literature review on NAS, in particular the weight-sharing methods, and points out that the major challenge comes from the optimization gap between the super-network and the sub-architectures. From this perspective, we summarize existing approaches into several categories according to their efforts in bridging the gap, and analyze both advantages and disadvantages of these methodologies. Finally, we share our opinions on the future directions of NAS and AutoML. Due to the expertise of the authors, this paper mainly focuses on the application of NAS to computer vision problems and may bias towards the work in our group.
Corner Proposal Network for Anchor-free, Two-stage Object Detection
Jul 27, 2020
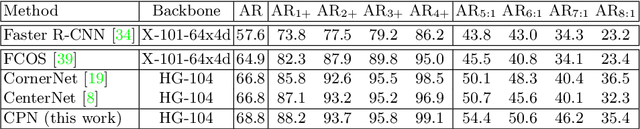

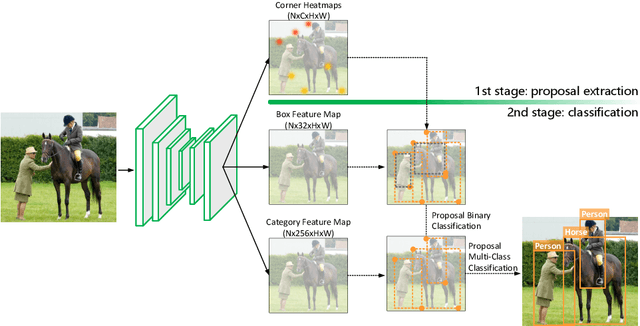
The goal of object detection is to determine the class and location of objects in an image. This paper proposes a novel anchor-free, two-stage framework which first extracts a number of object proposals by finding potential corner keypoint combinations and then assigns a class label to each proposal by a standalone classification stage. We demonstrate that these two stages are effective solutions for improving recall and precision, respectively, and they can be integrated into an end-to-end network. Our approach, dubbed Corner Proposal Network (CPN), enjoys the ability to detect objects of various scales and also avoids being confused by a large number of false-positive proposals. On the MS-COCO dataset, CPN achieves an AP of 49.2% which is competitive among state-of-the-art object detection methods. CPN also fits the scenario of computational efficiency, which achieves an AP of 41.6%/39.7% at 26.2/43.3 FPS, surpassing most competitors with the same inference speed. Code is available at https://github.com/Duankaiwen/CPNDet
Social Adaptive Module for Weakly-supervised Group Activity Recognition
Jul 18, 2020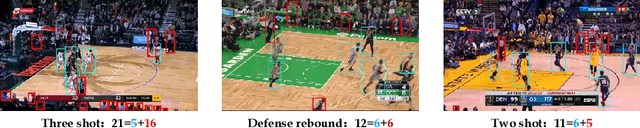
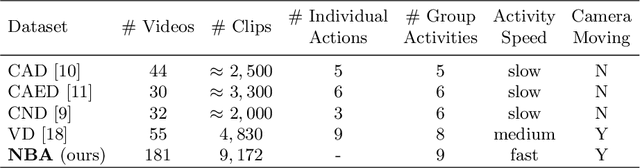

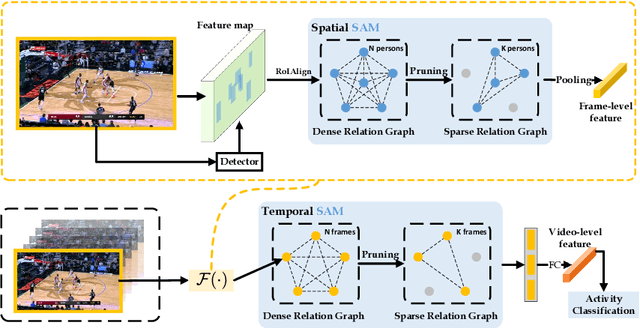
This paper presents a new task named weakly-supervised group activity recognition (GAR) which differs from conventional GAR tasks in that only video-level labels are available, yet the important persons within each frame are not provided even in the training data. This eases us to collect and annotate a large-scale NBA dataset and thus raise new challenges to GAR. To mine useful information from weak supervision, we present a key insight that key instances are likely to be related to each other, and thus design a social adaptive module (SAM) to reason about key persons and frames from noisy data. Experiments show significant improvement on the NBA dataset as well as the popular volleyball dataset. In particular, our model trained on video-level annotation achieves comparable accuracy to prior algorithms which required strong labels.