 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFineViT: Progressively Unlocking Fine-Grained Perception with Dense Recaptions
Mar 18, 2026While Multimodal Large Language Models (MLLMs) have experienced rapid advancements, their visual encoders frequently remain a performance bottleneck. Conventional CLIP-based encoders struggle with dense spatial tasks due to the loss of visual details caused by low-resolution pretraining and the reliance on noisy, coarse web-crawled image-text pairs. To overcome these limitations, we introduce FineViT, a novel vision encoder specifically designed to unlock fine-grained perception. By replacing coarse web data with dense recaptions, we systematically mitigate information loss through a progressive training paradigm.: first, the encoder is trained from scratch at a high native resolution on billions of global recaptioned image-text pairs, establishing a robust, detail rich semantic foundation. Subsequently, we further enhance its local perception through LLM alignment, utilizing our curated FineCap-450M dataset that comprises over $450$ million high quality local captions. Extensive experiments validate the effectiveness of the progressive strategy. FineViT achieves state-of-the-art zero-shot recognition and retrieval performance, especially in long-context retrieval, and consistently outperforms multimodal visual encoders such as SigLIP2 and Qwen-ViT when integrated into MLLMs. We hope FineViT could serve as a powerful new baseline for fine-grained visual perception.
One-bit Supervision for Image Classification
Sep 16, 2020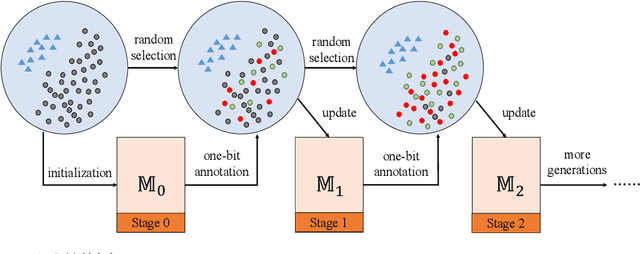

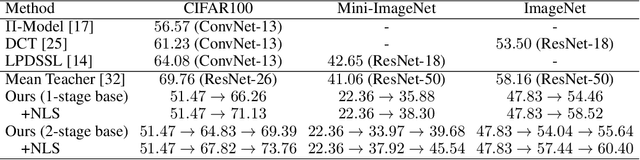
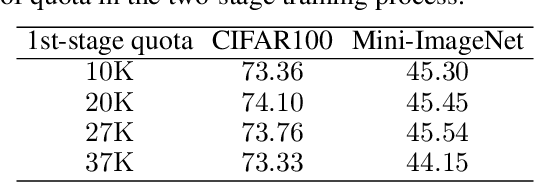
This paper presents one-bit supervision, a novel setting of learning from incomplete annotations, in the scenario of image classification. Instead of training a model upon the accurate label of each sample, our setting requires the model to query with a predicted label of each sample and learn from the answer whether the guess is correct. This provides one bit (yes or no) of information, and more importantly, annotating each sample becomes much easier than finding the accurate label from many candidate classes. There are two keys to training a model upon one-bit supervision: improving the guess accuracy and making use of incorrect guesses. For these purposes, we propose a multi-stage training paradigm which incorporates negative label suppression into an off-the-shelf semi-supervised learning algorithm. In three popular image classification benchmarks, our approach claims higher efficiency in utilizing the limited amount of annotations.