 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePROL : Rehearsal Free Continual Learning in Streaming Data via Prompt Online Learning
Jul 16, 2025



The data privacy constraint in online continual learning (OCL), where the data can be seen only once, complicates the catastrophic forgetting problem in streaming data. A common approach applied by the current SOTAs in OCL is with the use of memory saving exemplars or features from previous classes to be replayed in the current task. On the other hand, the prompt-based approach performs excellently in continual learning but with the cost of a growing number of trainable parameters. The first approach may not be applicable in practice due to data openness policy, while the second approach has the issue of throughput associated with the streaming data. In this study, we propose a novel prompt-based method for online continual learning that includes 4 main components: (1) single light-weight prompt generator as a general knowledge, (2) trainable scaler-and-shifter as specific knowledge, (3) pre-trained model (PTM) generalization preserving, and (4) hard-soft updates mechanism. Our proposed method achieves significantly higher performance than the current SOTAs in CIFAR100, ImageNet-R, ImageNet-A, and CUB dataset. Our complexity analysis shows that our method requires a relatively smaller number of parameters and achieves moderate training time, inference time, and throughput. For further study, the source code of our method is available at https://github.com/anwarmaxsum/PROL.
Bind-Your-Avatar: Multi-Talking-Character Video Generation with Dynamic 3D-mask-based Embedding Router
Jun 24, 2025
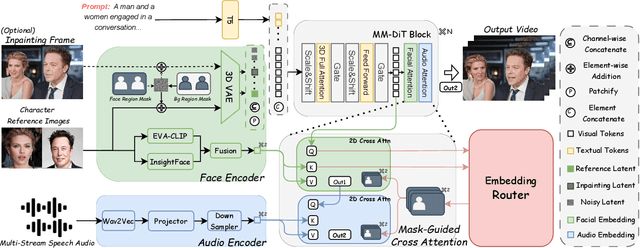
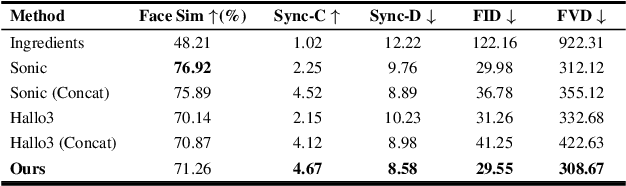
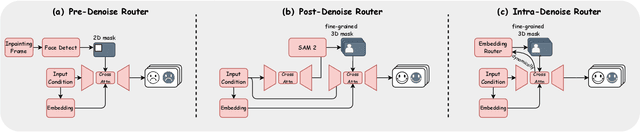
Recent years have witnessed remarkable advances in audio-driven talking head generation. However, existing approaches predominantly focus on single-character scenarios. While some methods can create separate conversation videos between two individuals, the critical challenge of generating unified conversation videos with multiple physically co-present characters sharing the same spatial environment remains largely unaddressed. This setting presents two key challenges: audio-to-character correspondence control and the lack of suitable datasets featuring multi-character talking videos within the same scene. To address these challenges, we introduce Bind-Your-Avatar, an MM-DiT-based model specifically designed for multi-talking-character video generation in the same scene. Specifically, we propose (1) A novel framework incorporating a fine-grained Embedding Router that binds `who' and `speak what' together to address the audio-to-character correspondence control. (2) Two methods for implementing a 3D-mask embedding router that enables frame-wise, fine-grained control of individual characters, with distinct loss functions based on observed geometric priors and a mask refinement strategy to enhance the accuracy and temporal smoothness of the predicted masks. (3) The first dataset, to the best of our knowledge, specifically constructed for multi-talking-character video generation, and accompanied by an open-source data processing pipeline, and (4) A benchmark for the dual-talking-characters video generation, with extensive experiments demonstrating superior performance over multiple state-of-the-art methods.
S2R-Bench: A Sim-to-Real Evaluation Benchmark for Autonomous Driving
May 24, 2025



Safety is a long-standing and the final pursuit in the development of autonomous driving systems, with a significant portion of safety challenge arising from perception. How to effectively evaluate the safety as well as the reliability of perception algorithms is becoming an emerging issue. Despite its critical importance, existing perception methods exhibit a limitation in their robustness, primarily due to the use of benchmarks are entierly simulated, which fail to align predicted results with actual outcomes, particularly under extreme weather conditions and sensor anomalies that are prevalent in real-world scenarios. To fill this gap, in this study, we propose a Sim-to-Real Evaluation Benchmark for Autonomous Driving (S2R-Bench). We collect diverse sensor anomaly data under various road conditions to evaluate the robustness of autonomous driving perception methods in a comprehensive and realistic manner. This is the first corruption robustness benchmark based on real-world scenarios, encompassing various road conditions, weather conditions, lighting intensities, and time periods. By comparing real-world data with simulated data, we demonstrate the reliability and practical significance of the collected data for real-world applications. We hope that this dataset will advance future research and contribute to the development of more robust perception models for autonomous driving. This dataset is released on https://github.com/adept-thu/S2R-Bench.
A Novel Generative Model with Causality Constraint for Mitigating Biases in Recommender Systems
May 22, 2025Accurately predicting counterfactual user feedback is essential for building effective recommender systems. However, latent confounding bias can obscure the true causal relationship between user feedback and item exposure, ultimately degrading recommendation performance. Existing causal debiasing approaches often rely on strong assumptions-such as the availability of instrumental variables (IVs) or strong correlations between latent confounders and proxy variables-that are rarely satisfied in real-world scenarios. To address these limitations, we propose a novel generative framework called Latent Causality Constraints for Debiasing representation learning in Recommender Systems (LCDR). Specifically, LCDR leverages an identifiable Variational Autoencoder (iVAE) as a causal constraint to align the latent representations learned by a standard Variational Autoencoder (VAE) through a unified loss function. This alignment allows the model to leverage even weak or noisy proxy variables to recover latent confounders effectively. The resulting representations are then used to improve recommendation performance. Extensive experiments on three real-world datasets demonstrate that LCDR consistently outperforms existing methods in both mitigating bias and improving recommendation accuracy.
Federated Large Language Models: Feasibility, Robustness, Security and Future Directions
May 13, 2025The integration of Large Language Models (LLMs) and Federated Learning (FL) presents a promising solution for joint training on distributed data while preserving privacy and addressing data silo issues. However, this emerging field, known as Federated Large Language Models (FLLM), faces significant challenges, including communication and computation overheads, heterogeneity, privacy and security concerns. Current research has primarily focused on the feasibility of FLLM, but future trends are expected to emphasize enhancing system robustness and security. This paper provides a comprehensive review of the latest advancements in FLLM, examining challenges from four critical perspectives: feasibility, robustness, security, and future directions. We present an exhaustive survey of existing studies on FLLM feasibility, introduce methods to enhance robustness in the face of resource, data, and task heterogeneity, and analyze novel risks associated with this integration, including privacy threats and security challenges. We also review the latest developments in defense mechanisms and explore promising future research directions, such as few-shot learning, machine unlearning, and IP protection. This survey highlights the pressing need for further research to enhance system robustness and security while addressing the unique challenges posed by the integration of FL and LLM.
Two Tasks, One Goal: Uniting Motion and Planning for Excellent End To End Autonomous Driving Performance
Apr 17, 2025End-to-end autonomous driving has made impressive progress in recent years. Former end-to-end autonomous driving approaches often decouple planning and motion tasks, treating them as separate modules. This separation overlooks the potential benefits that planning can gain from learning out-of-distribution data encountered in motion tasks. However, unifying these tasks poses significant challenges, such as constructing shared contextual representations and handling the unobservability of other vehicles' states. To address these challenges, we propose TTOG, a novel two-stage trajectory generation framework. In the first stage, a diverse set of trajectory candidates is generated, while the second stage focuses on refining these candidates through vehicle state information. To mitigate the issue of unavailable surrounding vehicle states, TTOG employs a self-vehicle data-trained state estimator, subsequently extended to other vehicles. Furthermore, we introduce ECSA (equivariant context-sharing scene adapter) to enhance the generalization of scene representations across different agents. Experimental results demonstrate that TTOG achieves state-of-the-art performance across both planning and motion tasks. Notably, on the challenging open-loop nuScenes dataset, TTOG reduces the L2 distance by 36.06\%. Furthermore, on the closed-loop Bench2Drive dataset, our approach achieves a 22\% improvement in the driving score (DS), significantly outperforming existing baselines.
RASA: Replace Anyone, Say Anything -- A Training-Free Framework for Audio-Driven and Universal Portrait Video Editing
Mar 14, 2025Portrait video editing focuses on modifying specific attributes of portrait videos, guided by audio or video streams. Previous methods typically either concentrate on lip-region reenactment or require training specialized models to extract keypoints for motion transfer to a new identity. In this paper, we introduce a training-free universal portrait video editing framework that provides a versatile and adaptable editing strategy. This framework supports portrait appearance editing conditioned on the changed first reference frame, as well as lip editing conditioned on varied speech, or a combination of both. It is based on a Unified Animation Control (UAC) mechanism with source inversion latents to edit the entire portrait, including visual-driven shape control, audio-driven speaking control, and inter-frame temporal control. Furthermore, our method can be adapted to different scenarios by adjusting the initial reference frame, enabling detailed editing of portrait videos with specific head rotations and facial expressions. This comprehensive approach ensures a holistic and flexible solution for portrait video editing. The experimental results show that our model can achieve more accurate and synchronized lip movements for the lip editing task, as well as more flexible motion transfer for the appearance editing task. Demo is available at https://alice01010101.github.io/RASA/.
LREF: A Novel LLM-based Relevance Framework for E-commerce
Mar 12, 2025



Query and product relevance prediction is a critical component for ensuring a smooth user experience in e-commerce search. Traditional studies mainly focus on BERT-based models to assess the semantic relevance between queries and products. However, the discriminative paradigm and limited knowledge capacity of these approaches restrict their ability to comprehend the relevance between queries and products fully. With the rapid advancement of Large Language Models (LLMs), recent research has begun to explore their application to industrial search systems, as LLMs provide extensive world knowledge and flexible optimization for reasoning processes. Nonetheless, directly leveraging LLMs for relevance prediction tasks introduces new challenges, including a high demand for data quality, the necessity for meticulous optimization of reasoning processes, and an optimistic bias that can result in over-recall. To overcome the above problems, this paper proposes a novel framework called the LLM-based RElevance Framework (LREF) aimed at enhancing e-commerce search relevance. The framework comprises three main stages: supervised fine-tuning (SFT) with Data Selection, Multiple Chain of Thought (Multi-CoT) tuning, and Direct Preference Optimization (DPO) for de-biasing. We evaluate the performance of the framework through a series of offline experiments on large-scale real-world datasets, as well as online A/B testing. The results indicate significant improvements in both offline and online metrics. Ultimately, the model was deployed in a well-known e-commerce application, yielding substantial commercial benefits.
Accelerating Diffusion Transformer via Gradient-Optimized Cache
Mar 07, 2025



Feature caching has emerged as an effective strategy to accelerate diffusion transformer (DiT) sampling through temporal feature reuse. It is a challenging problem since (1) Progressive error accumulation from cached blocks significantly degrades generation quality, particularly when over 50\% of blocks are cached; (2) Current error compensation approaches neglect dynamic perturbation patterns during the caching process, leading to suboptimal error correction. To solve these problems, we propose the Gradient-Optimized Cache (GOC) with two key innovations: (1) Cached Gradient Propagation: A gradient queue dynamically computes the gradient differences between cached and recomputed features. These gradients are weighted and propagated to subsequent steps, directly compensating for the approximation errors introduced by caching. (2) Inflection-Aware Optimization: Through statistical analysis of feature variation patterns, we identify critical inflection points where the denoising trajectory changes direction. By aligning gradient updates with these detected phases, we prevent conflicting gradient directions during error correction. Extensive evaluations on ImageNet demonstrate GOC's superior trade-off between efficiency and quality. With 50\% cached blocks, GOC achieves IS 216.28 (26.3\% higher) and FID 3.907 (43\% lower) compared to baseline DiT, while maintaining identical computational costs. These improvements persist across various cache ratios, demonstrating robust adaptability to different acceleration requirements.
Don't Shake the Wheel: Momentum-Aware Planning in End-to-End Autonomous Driving
Mar 05, 2025



End-to-end autonomous driving frameworks enable seamless integration of perception and planning but often rely on one-shot trajectory prediction, which may lead to unstable control and vulnerability to occlusions in single-frame perception. To address this, we propose the Momentum-Aware Driving (MomAD) framework, which introduces trajectory momentum and perception momentum to stabilize and refine trajectory predictions. MomAD comprises two core components: (1) Topological Trajectory Matching (TTM) employs Hausdorff Distance to select the optimal planning query that aligns with prior paths to ensure coherence;(2) Momentum Planning Interactor (MPI) cross-attends the selected planning query with historical queries to expand static and dynamic perception files. This enriched query, in turn, helps regenerate long-horizon trajectory and reduce collision risks. To mitigate noise arising from dynamic environments and detection errors, we introduce robust instance denoising during training, enabling the planning model to focus on critical signals and improve its robustness. We also propose a novel Trajectory Prediction Consistency (TPC) metric to quantitatively assess planning stability. Experiments on the nuScenes dataset demonstrate that MomAD achieves superior long-term consistency (>=3s) compared to SOTA methods. Moreover, evaluations on the curated Turning-nuScenes shows that MomAD reduces the collision rate by 26% and improves TPC by 0.97m (33.45%) over a 6s prediction horizon, while closedloop on Bench2Drive demonstrates an up to 16.3% improvement in success rate.