 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeuLEAD-TabPFN: Uncertainty-aware Dependency-based Anomaly Detection with TabPFN
Apr 22, 2026Anomaly detection in tabular data is challenging due to high dimensionality, complex feature dependencies, and heterogeneous noise. Many existing methods rely on proximity-based cues and may miss anomalies caused by violations of complex feature dependencies. Dependency-based anomaly detection provides a principled alternative by identifying anomalies as violations of dependencies among features. However, existing methods often struggle to model such dependencies robustly and to scale to high-dimensional data with complex dependency structures. To address these challenges, we propose uLEAD-TabPFN, a dependency-based anomaly detection framework built on Prior-Data Fitted Networks (PFNs). uLEAD-TabPFN identifies anomalies as violations of conditional dependencies in a learned latent space, leveraging frozen PFNs for dependency estimation. Combined with uncertainty-aware scoring, the proposed framework enables robust and scalable anomaly detection. Experiments on 57 tabular datasets from ADBench show that uLEAD-TabPFN achieves particularly strong performance in medium- and high-dimensional settings, where it attains the top average rank. On high-dimensional datasets, uLEAD-TabPFN improves the average ROC-AUC by nearly 20\% over the average baseline and by approximately 2.8\% over the best-performing baseline, while maintaining overall superior performance compared to state-of-the-art methods. Further analysis shows that uLEAD-TabPFN provides complementary anomaly detection capability, achieving strong performance on datasets where many existing methods struggle.
Disentangled Instrumental Variables for Causal Inference with Networked Observational Data
Feb 08, 2026Instrumental variables (IVs) are crucial for addressing unobservable confounders, yet their stringent exogeneity assumptions pose significant challenges in networked data. Existing methods typically rely on modelling neighbour information when recovering IVs, thereby inevitably mixing shared environment-induced endogenous correlations and individual-specific exogenous variation, leading the resulting IVs to inherit dependence on unobserved confounders and to violate exogeneity. To overcome this challenge, we propose $\underline{Dis}$entangled $\underline{I}$nstrumental $\underline{V}$ariables (DisIV) framework, a novel method for causal inference based on networked observational data with latent confounders. DisIV exploits network homogeneity as an inductive bias and employs a structural disentanglement mechanism to extract individual-specific components that serve as latent IVs. The causal validity of the extracted IVs is constrained through explicit orthogonality and exclusion conditions. Extensive semi-synthetic experiments on real-world datasets demonstrate that DisIV consistently outperforms state-of-the-art baselines in causal effect estimation under network-induced confounding.
A Novel Generative Model with Causality Constraint for Mitigating Biases in Recommender Systems
May 22, 2025Accurately predicting counterfactual user feedback is essential for building effective recommender systems. However, latent confounding bias can obscure the true causal relationship between user feedback and item exposure, ultimately degrading recommendation performance. Existing causal debiasing approaches often rely on strong assumptions-such as the availability of instrumental variables (IVs) or strong correlations between latent confounders and proxy variables-that are rarely satisfied in real-world scenarios. To address these limitations, we propose a novel generative framework called Latent Causality Constraints for Debiasing representation learning in Recommender Systems (LCDR). Specifically, LCDR leverages an identifiable Variational Autoencoder (iVAE) as a causal constraint to align the latent representations learned by a standard Variational Autoencoder (VAE) through a unified loss function. This alignment allows the model to leverage even weak or noisy proxy variables to recover latent confounders effectively. The resulting representations are then used to improve recommendation performance. Extensive experiments on three real-world datasets demonstrate that LCDR consistently outperforms existing methods in both mitigating bias and improving recommendation accuracy.
Counterfactual Samples Constructing and Training for Commonsense Statements Estimation
Dec 29, 2024



Plausibility Estimation (PE) plays a crucial role for enabling language models to objectively comprehend the real world. While large language models (LLMs) demonstrate remarkable capabilities in PE tasks but sometimes produce trivial commonsense errors due to the complexity of commonsense knowledge. They lack two key traits of an ideal PE model: a) Language-explainable: relying on critical word segments for decisions, and b) Commonsense-sensitive: detecting subtle linguistic variations in commonsense. To address these issues, we propose a novel model-agnostic method, referred to as Commonsense Counterfactual Samples Generating (CCSG). By training PE models with CCSG, we encourage them to focus on critical words, thereby enhancing both their language-explainable and commonsense-sensitive capabilities. Specifically, CCSG generates counterfactual samples by strategically replacing key words and introducing low-level dropout within sentences. These counterfactual samples are then incorporated into a sentence-level contrastive training framework to further enhance the model's learning process. Experimental results across nine diverse datasets demonstrate the effectiveness of CCSG in addressing commonsense reasoning challenges, with our CCSG method showing 3.07% improvement against the SOTA methods.
Leaning Time-Varying Instruments for Identifying Causal Effects in Time-Series Data
Nov 26, 2024



Querying causal effects from time-series data is important across various fields, including healthcare, economics, climate science, and epidemiology. However, this task becomes complex in the existence of time-varying latent confounders, which affect both treatment and outcome variables over time and can introduce bias in causal effect estimation. Traditional instrumental variable (IV) methods are limited in addressing such complexities due to the need for predefined IVs or strong assumptions that do not hold in dynamic settings. To tackle these issues, we develop a novel Time-varying Conditional Instrumental Variables (CIV) for Debiasing causal effect estimation, referred to as TDCIV. TDCIV leverages Long Short-Term Memory (LSTM) and Variational Autoencoder (VAE) models to disentangle and learn the representations of time-varying CIV and its conditioning set from proxy variables without prior knowledge. Under the assumptions of the Markov property and availability of proxy variables, we theoretically establish the validity of these learned representations for addressing the biases from time-varying latent confounders, thus enabling accurate causal effect estimation. Our proposed TDCIV is the first to effectively learn time-varying CIV and its associated conditioning set without relying on domain-specific knowledge.
Linking Model Intervention to Causal Interpretation in Model Explanation
Oct 21, 2024



Intervention intuition is often used in model explanation where the intervention effect of a feature on the outcome is quantified by the difference of a model prediction when the feature value is changed from the current value to the baseline value. Such a model intervention effect of a feature is inherently association. In this paper, we will study the conditions when an intuitive model intervention effect has a causal interpretation, i.e., when it indicates whether a feature is a direct cause of the outcome. This work links the model intervention effect to the causal interpretation of a model. Such an interpretation capability is important since it indicates whether a machine learning model is trustworthy to domain experts. The conditions also reveal the limitations of using a model intervention effect for causal interpretation in an environment with unobserved features. Experiments on semi-synthetic datasets have been conducted to validate theorems and show the potential for using the model intervention effect for model interpretation.
Mitigating Dual Latent Confounding Biases in Recommender Systems
Oct 16, 2024



Recommender systems are extensively utilised across various areas to predict user preferences for personalised experiences and enhanced user engagement and satisfaction. Traditional recommender systems, however, are complicated by confounding bias, particularly in the presence of latent confounders that affect both item exposure and user feedback. Existing debiasing methods often fail to capture the complex interactions caused by latent confounders in interaction data, especially when dual latent confounders affect both the user and item sides. To address this, we propose a novel debiasing method that jointly integrates the Instrumental Variables (IV) approach and identifiable Variational Auto-Encoder (iVAE) for Debiased representation learning in Recommendation systems, referred to as IViDR. Specifically, IViDR leverages the embeddings of user features as IVs to address confounding bias caused by latent confounders between items and user feedback, and reconstructs the embedding of items to obtain debiased interaction data. Moreover, IViDR employs an Identifiable Variational Auto-Encoder (iVAE) to infer identifiable representations of latent confounders between item exposure and user feedback from both the original and debiased interaction data. Additionally, we provide theoretical analyses of the soundness of using IV and the identifiability of the latent representations. Extensive experiments on both synthetic and real-world datasets demonstrate that IViDR outperforms state-of-the-art models in reducing bias and providing reliable recommendations.
Multi-Cause Deconfounding for Recommender Systems with Latent Confounders
Oct 16, 2024



In recommender systems, various latent confounding factors (e.g., user social environment and item public attractiveness) can affect user behavior, item exposure, and feedback in distinct ways. These factors may directly or indirectly impact user feedback and are often shared across items or users, making them multi-cause latent confounders. However, existing methods typically fail to account for latent confounders between users and their feedback, as well as those between items and user feedback simultaneously. To address the problem of multi-cause latent confounders, we propose a multi-cause deconfounding method for recommender systems with latent confounders (MCDCF). MCDCF leverages multi-cause causal effect estimation to learn substitutes for latent confounders associated with both users and items, using user behaviour data. Specifically, MCDCF treats the multiple items that users interact with and the multiple users that interact with items as treatment variables, enabling it to learn substitutes for the latent confounders that influence the estimation of causality between users and their feedback, as well as between items and user feedback. Additionally, we theoretically demonstrate the soundness of our MCDCF method. Extensive experiments on three real-world datasets demonstrate that our MCDCF method effectively recovers latent confounders related to users and items, reducing bias and thereby improving recommendation accuracy.
Towards Fair Graph Representation Learning in Social Networks
Oct 15, 2024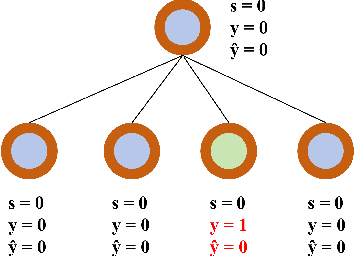
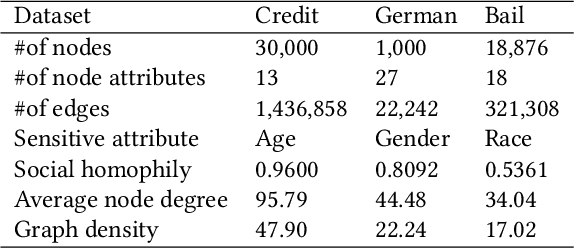
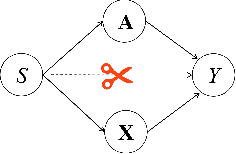
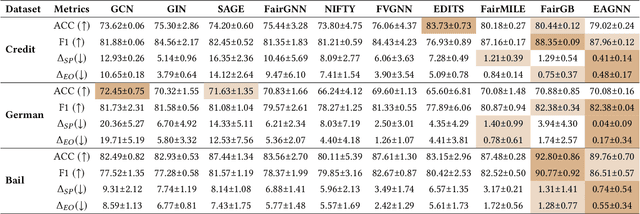
With the widespread use of Graph Neural Networks (GNNs) for representation learning from network data, the fairness of GNN models has raised great attention lately. Fair GNNs aim to ensure that node representations can be accurately classified, but not easily associated with a specific group. Existing advanced approaches essentially enhance the generalisation of node representation in combination with data augmentation strategy, and do not directly impose constraints on the fairness of GNNs. In this work, we identify that a fundamental reason for the unfairness of GNNs in social network learning is the phenomenon of social homophily, i.e., users in the same group are more inclined to congregate. The message-passing mechanism of GNNs can cause users in the same group to have similar representations due to social homophily, leading model predictions to establish spurious correlations with sensitive attributes. Inspired by this reason, we propose a method called Equity-Aware GNN (EAGNN) towards fair graph representation learning. Specifically, to ensure that model predictions are independent of sensitive attributes while maintaining prediction performance, we introduce constraints for fair representation learning based on three principles: sufficiency, independence, and separation. We theoretically demonstrate that our EAGNN method can effectively achieve group fairness. Extensive experiments on three datasets with varying levels of social homophily illustrate that our EAGNN method achieves the state-of-the-art performance across two fairness metrics and offers competitive effectiveness.
TSI: A Multi-View Representation Learning Approach for Time Series Forecasting
Sep 30, 2024



As the growing demand for long sequence time-series forecasting in real-world applications, such as electricity consumption planning, the significance of time series forecasting becomes increasingly crucial across various domains. This is highlighted by recent advancements in representation learning within the field. This study introduces a novel multi-view approach for time series forecasting that innovatively integrates trend and seasonal representations with an Independent Component Analysis (ICA)-based representation. Recognizing the limitations of existing methods in representing complex and high-dimensional time series data, this research addresses the challenge by combining TS (trend and seasonality) and ICA (independent components) perspectives. This approach offers a holistic understanding of time series data, going beyond traditional models that often miss nuanced, nonlinear relationships. The efficacy of TSI model is demonstrated through comprehensive testing on various benchmark datasets, where it shows superior performance over current state-of-the-art models, particularly in multivariate forecasting. This method not only enhances the accuracy of forecasting but also contributes significantly to the field by providing a more in-depth understanding of time series data. The research which uses ICA for a view lays the groundwork for further exploration and methodological advancements in time series forecasting, opening new avenues for research and practical applications.