 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Transformers that Never Stop Learning
Mar 08, 2026Loss of plasticity refers to the progressive inability of a model to adapt to new tasks and poses a fundamental challenge for continual learning. While this phenomenon has been extensively studied in homogeneous neural architectures, such as multilayer perceptrons, its mechanisms in structurally heterogeneous, attention-based models such as Vision Transformers (ViTs) remain underexplored. In this work, we present a systematic investigation of loss of plasticity in ViTs, including a fine-grained diagnosis using local metrics that capture parameter diversity and utilization. Our analysis reveals that stacked attention modules exhibit increasing instability that exacerbates plasticity loss, while feed-forward network modules suffer even more pronounced degradation. Furthermore, we evaluate several approaches for mitigating plasticity loss. The results indicate that methods based on parameter re-initialization fail to recover plasticity in ViTs, whereas approaches that explicitly regulate the update process are more effective. Motivated by this insight, we propose ARROW, a geometry-aware optimizer that preserves plasticity by adaptively reshaping gradient directions using an online curvature estimate for the attention module. Extensive experiments show that ARROW effectively improves plasticity and maintains better performance on newly encountered tasks.
AdvisingWise: Supporting Academic Advising in Higher Educations Through a Human-in-the-Loop Multi-Agent Framework
Nov 07, 2025Academic advising is critical to student success in higher education, yet high student-to-advisor ratios limit advisors' capacity to provide timely support, particularly during peak periods. Recent advances in Large Language Models (LLMs) present opportunities to enhance the advising process. We present AdvisingWise, a multi-agent system that automates time-consuming tasks, such as information retrieval and response drafting, while preserving human oversight. AdvisingWise leverages authoritative institutional resources and adaptively prompts students about their academic backgrounds to generate reliable, personalized responses. All system responses undergo human advisor validation before delivery to students. We evaluate AdvisingWise through a mixed-methods approach: (1) expert evaluation on responses of 20 sample queries, (2) LLM-as-a-judge evaluation of the information retrieval strategy, and (3) a user study with 8 academic advisors to assess the system's practical utility. Our evaluation shows that AdvisingWise produces accurate, personalized responses. Advisors reported increasingly positive perceptions after using AdvisingWise, as their initial concerns about reliability and personalization diminished. We conclude by discussing the implications of human-AI synergy on the practice of academic advising.
Online Joint Assortment-Inventory Optimization under MNL Choices
Apr 04, 2023



We study an online joint assortment-inventory optimization problem, in which we assume that the choice behavior of each customer follows the Multinomial Logit (MNL) choice model, and the attraction parameters are unknown a priori. The retailer makes periodic assortment and inventory decisions to dynamically learn from the realized demands about the attraction parameters while maximizing the expected total profit over time. In this paper, we propose a novel algorithm that can effectively balance the exploration and exploitation in the online decision-making of assortment and inventory. Our algorithm builds on a new estimator for the MNL attraction parameters, a novel approach to incentivize exploration by adaptively tuning certain known and unknown parameters, and an optimization oracle to static single-cycle assortment-inventory planning problems with given parameters. We establish a regret upper bound for our algorithm and a lower bound for the online joint assortment-inventory optimization problem, suggesting that our algorithm achieves nearly optimal regret rate, provided that the static optimization oracle is exact. Then we incorporate more practical approximate static optimization oracles into our algorithm, and bound from above the impact of static optimization errors on the regret of our algorithm. At last, we perform numerical studies to demonstrate the effectiveness of our proposed algorithm.
Global Weighted Tensor Nuclear Norm for Tensor Robust Principal Component Analysis
Sep 28, 2022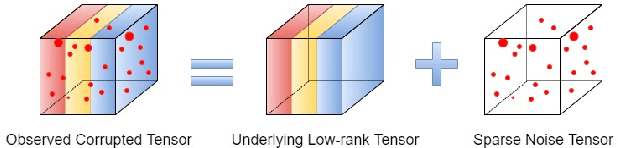
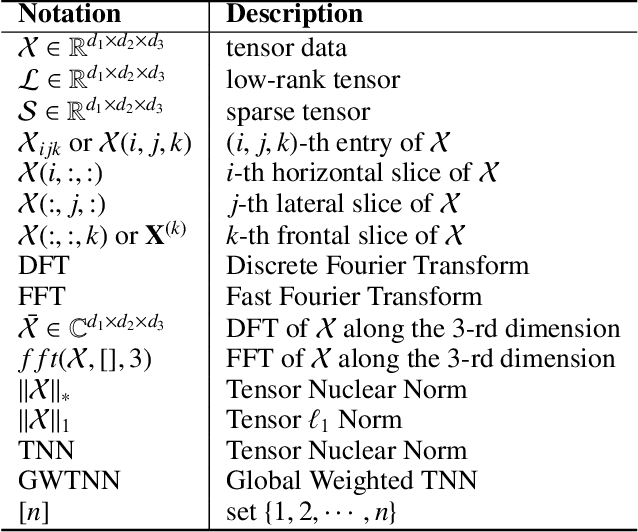
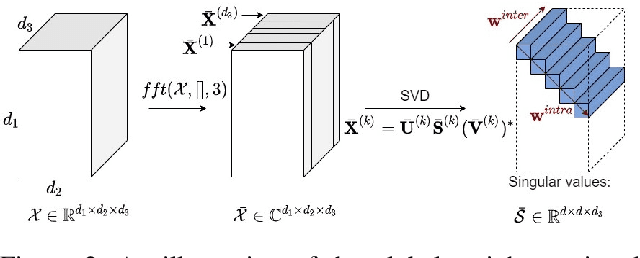
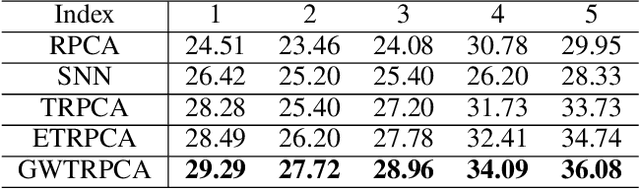
Tensor Robust Principal Component Analysis (TRPCA), which aims to recover a low-rank tensor corrupted by sparse noise, has attracted much attention in many real applications. This paper develops a new Global Weighted TRPCA method (GWTRPCA), which is the first approach simultaneously considers the significance of intra-frontal slice and inter-frontal slice singular values in the Fourier domain. Exploiting this global information, GWTRPCA penalizes the larger singular values less and assigns smaller weights to them. Hence, our method can recover the low-tubal-rank components more exactly. Moreover, we propose an effective adaptive weight learning strategy by a Modified Cauchy Estimator (MCE) since the weight setting plays a crucial role in the success of GWTRPCA. To implement the GWTRPCA method, we devise an optimization algorithm using an Alternating Direction Method of Multipliers (ADMM) method. Experiments on real-world datasets validate the effectiveness of our proposed method.
Broad Learning System Based on Maximum Correntropy Criterion
Dec 24, 2019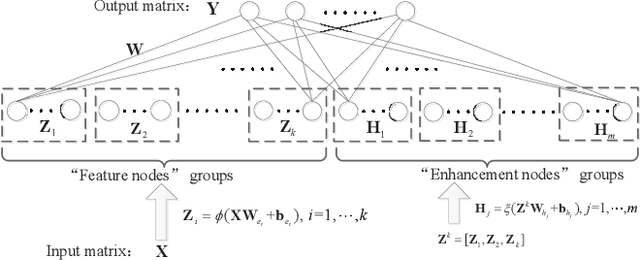
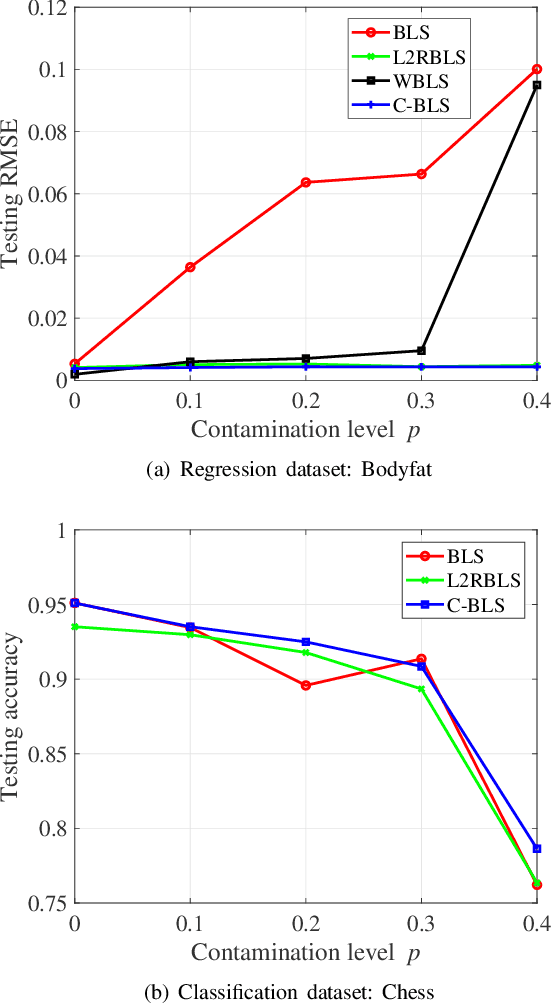
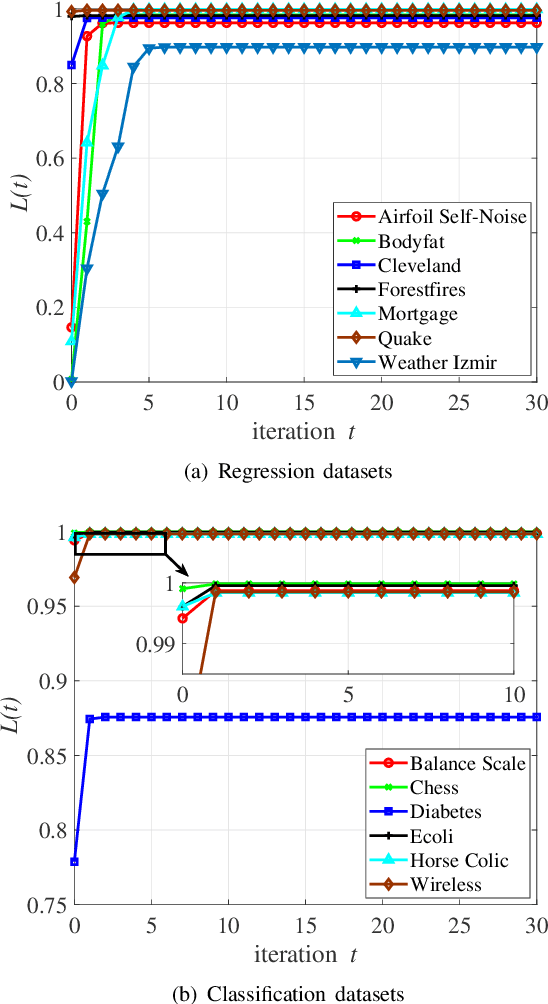
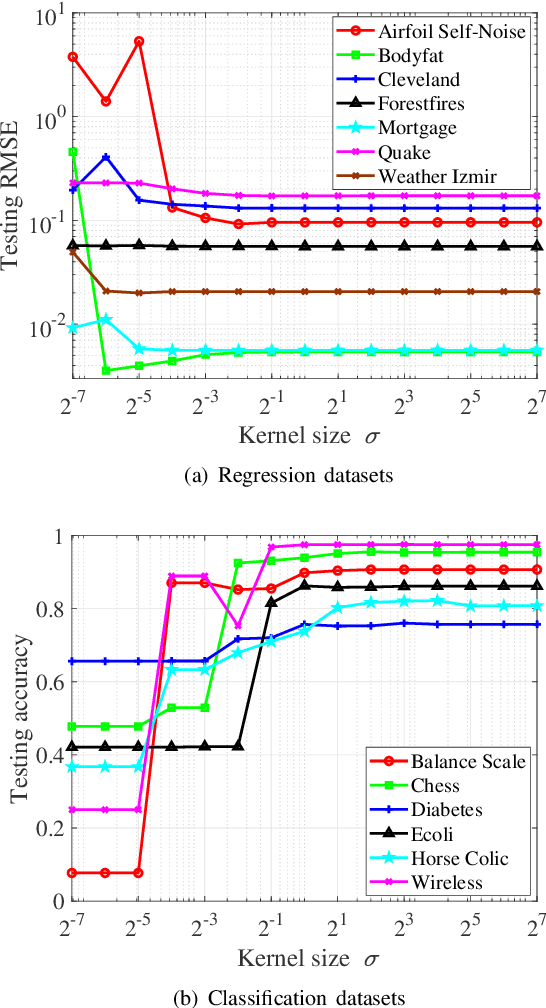
As an effective and efficient discriminative learning method, Broad Learning System (BLS) has received increasing attention due to its outstanding performance in various regression and classification problems. However, the standard BLS is derived under the minimum mean square error (MMSE) criterion, which is, of course, not always a good choice due to its sensitivity to outliers. To enhance the robustness of BLS, we propose in this work to adopt the maximum correntropy criterion (MCC) to train the output weights, obtaining a correntropy based broad learning system (C-BLS). Thanks to the inherent superiorities of MCC, the proposed C-BLS is expected to achieve excellent robustness to outliers while maintaining the original performance of the standard BLS in Gaussian or noise-free environment. In addition, three alternative incremental learning algorithms, derived from a weighted regularized least-squares solution rather than pseudoinverse formula, for C-BLS are developed.With the incremental learning algorithms, the system can be updated quickly without the entire retraining process from the beginning, when some new samples arrive or the network deems to be expanded. Experiments on various regression and classification datasets are reported to demonstrate the desirable performance of the new methods.