 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTA-GGAD: Testing-time Adaptive Graph Model for Generalist Graph Anomaly Detection
Mar 10, 2026A significant number of anomalous nodes in the real world, such as fake news, noncompliant users, malicious transactions, and malicious posts, severely compromises the health of the graph data ecosystem and urgently requires effective identification and processing. With anomalies that span multiple data domains yet exhibit vast differences in features, cross-domain detection models face severe domain shift issues, which limit their generalizability across all domains. This study identifies and quantitatively analyzes a specific feature mismatch pattern exhibited by domain shift in graph anomaly detection, which we define as the \emph{Anomaly Disassortativity} issue ($\mathcal{AD}$). Based on the modeling of the issue $\mathcal{AD}$, we introduce a novel graph foundation model for anomaly detection. It achieves cross-domain generalization in different graphs, requiring only a single training phase to perform effectively across diverse domains. The experimental findings, based on fourteen diverse real-world graphs, confirm a breakthrough in the model's cross-domain adaptation, achieving a pioneering state-of-the-art (SOTA) level in terms of detection accuracy. In summary, the proposed theory of $\mathcal{AD}$ provides a novel theoretical perspective and a practical route for future research in generalist graph anomaly detection (GGAD). The code is available at https://anonymous.4open.science/r/Anonymization-TA-GGAD/.
GCTAM: Global and Contextual Truncated Affinity Combined Maximization Model For Unsupervised Graph Anomaly Detection
Mar 02, 2026Anomalies often occur in real-world information networks/graphs, such as malevolent users, malicious comments, banned users, and fake news in social graphs. The latest graph anomaly detection methods use a novel mechanism called truncated affinity maximization (TAM) to detect anomaly nodes without using any label information and achieve impressive results. TAM maximizes the affinities among the normal nodes while truncating the affinities of the anomalous nodes to identify the anomalies. However, existing TAM-based methods truncate suspicious nodes according to a rigid threshold that ignores the specificity and high-order affinities of different nodes. This inevitably causes inefficient truncations from both normal and anomalous nodes, limiting the effectiveness of anomaly detection. To this end, this paper proposes a novel truncation model combining contextual and global affinity to truncate the anomalous nodes. The core idea of the work is to use contextual truncation to decrease the affinity of anomalous nodes, while global truncation increases the affinity of normal nodes. Extensive experiments on massive real-world datasets show that our method surpasses peer methods in most graph anomaly detection tasks. In highlights, compared with previous state-of-the-art methods, the proposed method has +15\% $\sim$ +20\% improvements in two famous real-world datasets, Amazon and YelpChi. Notably, our method works well in large datasets, Amazin-all and YelpChi-all, and achieves the best results, while most previous models cannot complete the tasks.
Multi-View Crowd Counting With Self-Supervised Learning
Sep 26, 2025Multi-view counting (MVC) methods have attracted significant research attention and stimulated remarkable progress in recent years. Despite their success, most MVC methods have focused on improving performance by following the fully supervised learning (FSL) paradigm, which often requires large amounts of annotated data. In this work, we propose SSLCounter, a novel self-supervised learning (SSL) framework for MVC that leverages neural volumetric rendering to alleviate the reliance on large-scale annotated datasets. SSLCounter learns an implicit representation w.r.t. the scene, enabling the reconstruction of continuous geometry shape and the complex, view-dependent appearance of their 2D projections via differential neural rendering. Owing to its inherent flexibility, the key idea of our method can be seamlessly integrated into exsiting frameworks. Notably, extensive experiments demonstrate that SSLCounter not only demonstrates state-of-the-art performances but also delivers competitive performance with only using 70% proportion of training data, showcasing its superior data efficiency across multiple MVC benchmarks.
NoiseHGNN: Synthesized Similarity Graph-Based Neural Network For Noised Heterogeneous Graph Representation Learning
Dec 24, 2024



Real-world graph data environments intrinsically exist noise (e.g., link and structure errors) that inevitably disturb the effectiveness of graph representation and downstream learning tasks. For homogeneous graphs, the latest works use original node features to synthesize a similarity graph that can correct the structure of the noised graph. This idea is based on the homogeneity assumption, which states that similar nodes in the homogeneous graph tend to have direct links in the original graph. However, similar nodes in heterogeneous graphs usually do not have direct links, which can not be used to correct the original noise graph. This causes a significant challenge in noised heterogeneous graph learning. To this end, this paper proposes a novel synthesized similarity-based graph neural network compatible with noised heterogeneous graph learning. First, we calculate the original feature similarities of all nodes to synthesize a similarity-based high-order graph. Second, we propose a similarity-aware encoder to embed original and synthesized graphs with shared parameters. Then, instead of graph-to-graph supervising, we synchronously supervise the original and synthesized graph embeddings to predict the same labels. Meanwhile, a target-based graph extracted from the synthesized graph contrasts the structure of the metapath-based graph extracted from the original graph to learn the mutual information. Extensive experiments in numerous real-world datasets show the proposed method achieves state-of-the-art records in the noised heterogeneous graph learning tasks. In highlights, +5$\sim$6\% improvements are observed in several noised datasets compared with previous SOTA methods. The code and datasets are available at https://github.com/kg-cc/NoiseHGNN.
CountFormer: Multi-View Crowd Counting Transformer
Jul 02, 2024



Multi-view counting (MVC) methods have shown their superiority over single-view counterparts, particularly in situations characterized by heavy occlusion and severe perspective distortions. However, hand-crafted heuristic features and identical camera layout requirements in conventional MVC methods limit their applicability and scalability in real-world scenarios.In this work, we propose a concise 3D MVC framework called \textbf{CountFormer}to elevate multi-view image-level features to a scene-level volume representation and estimate the 3D density map based on the volume features. By incorporating a camera encoding strategy, CountFormer successfully embeds camera parameters into the volume query and image-level features, enabling it to handle various camera layouts with significant differences.Furthermore, we introduce a feature lifting module capitalized on the attention mechanism to transform image-level features into a 3D volume representation for each camera view. Subsequently, the multi-view volume aggregation module attentively aggregates various multi-view volumes to create a comprehensive scene-level volume representation, allowing CountFormer to handle images captured by arbitrary dynamic camera layouts. The proposed method performs favorably against the state-of-the-art approaches across various widely used datasets, demonstrating its greater suitability for real-world deployment compared to conventional MVC frameworks.
Generalized Neural Networks for Real-Time Earthquake Early Warning
Dec 23, 2023Deep learning enhances earthquake monitoring capabilities by mining seismic waveforms directly. However, current neural networks, trained within specific areas, face challenges in generalizing to diverse regions. Here, we employ a data recombination method to create generalized earthquakes occurring at any location with arbitrary station distributions for neural network training. The trained models can then be applied to various regions with different monitoring setups for earthquake detection and parameter evaluation from continuous seismic waveform streams. This allows real-time Earthquake Early Warning (EEW) to be initiated at the very early stages of an occurring earthquake. When applied to substantial earthquake sequences across Japan and California (US), our models reliably report earthquake locations and magnitudes within 4 seconds after the first triggered station, with mean errors of 2.6-6.3 km and 0.05-0.17, respectively. These generalized neural networks facilitate global applications of real-time EEW, eliminating complex empirical configurations typically required by traditional methods.
Convolutional Embedding Makes Hierarchical Vision Transformer Stronger
Aug 01, 2022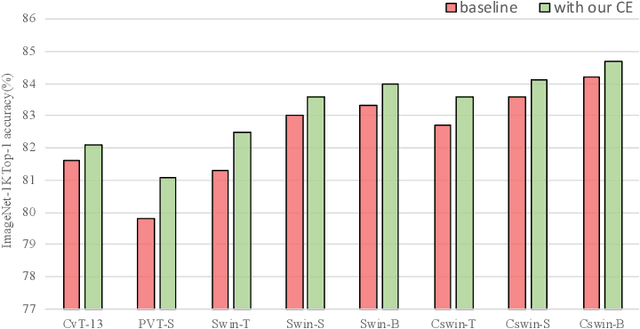
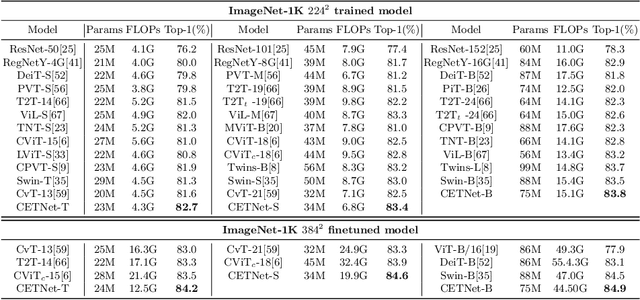
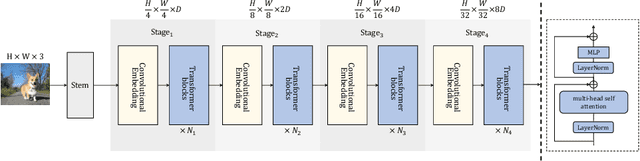
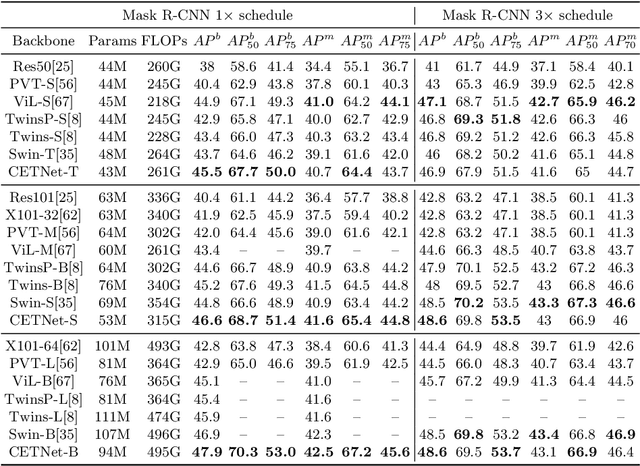
Vision Transformers (ViTs) have recently dominated a range of computer vision tasks, yet it suffers from low training data efficiency and inferior local semantic representation capability without appropriate inductive bias. Convolutional neural networks (CNNs) inherently capture regional-aware semantics, inspiring researchers to introduce CNNs back into the architecture of the ViTs to provide desirable inductive bias for ViTs. However, is the locality achieved by the micro-level CNNs embedded in ViTs good enough? In this paper, we investigate the problem by profoundly exploring how the macro architecture of the hybrid CNNs/ViTs enhances the performances of hierarchical ViTs. Particularly, we study the role of token embedding layers, alias convolutional embedding (CE), and systemically reveal how CE injects desirable inductive bias in ViTs. Besides, we apply the optimal CE configuration to 4 recently released state-of-the-art ViTs, effectively boosting the corresponding performances. Finally, a family of efficient hybrid CNNs/ViTs, dubbed CETNets, are released, which may serve as generic vision backbones. Specifically, CETNets achieve 84.9% Top-1 accuracy on ImageNet-1K (training from scratch), 48.6% box mAP on the COCO benchmark, and 51.6% mIoU on the ADE20K, substantially improving the performances of the corresponding state-of-the-art baselines.
AdaVITS: Tiny VITS for Low Computing Resource Speaker Adaptation
Jun 01, 2022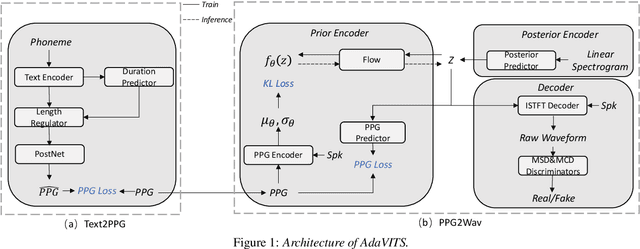

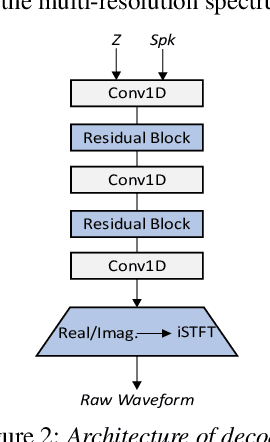
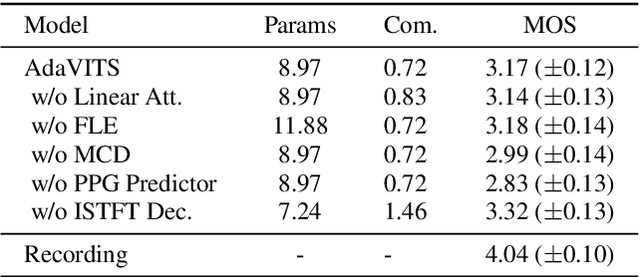
Speaker adaptation in text-to-speech synthesis (TTS) is to finetune a pre-trained TTS model to adapt to new target speakers with limited data. While much effort has been conducted towards this task, seldom work has been performed for low computational resource scenarios due to the challenges raised by the requirement of the lightweight model and less computational complexity. In this paper, a tiny VITS-based TTS model, named AdaVITS, for low computing resource speaker adaptation is proposed. To effectively reduce parameters and computational complexity of VITS, an iSTFT-based wave construction decoder is proposed to replace the upsampling-based decoder which is resource-consuming in the original VITS. Besides, NanoFlow is introduced to share the density estimate across flow blocks to reduce the parameters of the prior encoder. Furthermore, to reduce the computational complexity of the textual encoder, scaled-dot attention is replaced with linear attention. To deal with the instability caused by the simplified model, instead of using the original text encoder, phonetic posteriorgram (PPG) is utilized as linguistic feature via a text-to-PPG module, which is then used as input for the encoder. Experiment shows that AdaVITS can generate stable and natural speech in speaker adaptation with 8.97M model parameters and 0.72GFlops computational complexity.
MobRecon: Mobile-Friendly Hand Mesh Reconstruction from Monocular Image
Dec 06, 2021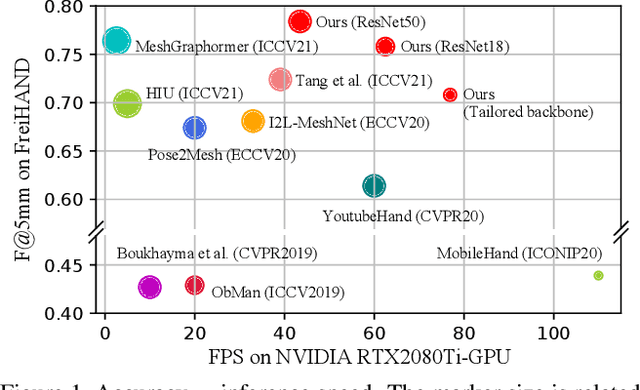
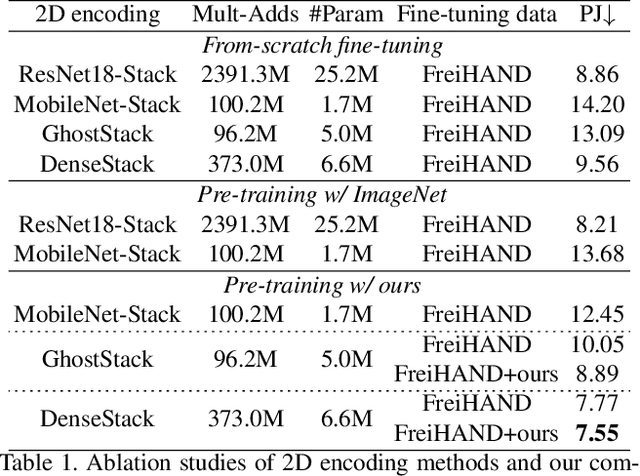


In this work, we propose a framework for single-view hand mesh reconstruction, which can simultaneously achieve high reconstruction accuracy, fast inference speed, and temporal coherence. Specifically, for 2D encoding, we propose lightweight yet effective stacked structures. Regarding 3D decoding, we provide an efficient graph operator, namely depth-separable spiral convolution. Moreover, we present a novel feature lifting module for bridging the gap between 2D and 3D representations. This module starts with a map-based position regression (MapReg) block to integrate the merits of both heatmap encoding and position regression paradigms to improve 2D accuracy and temporal coherence. Furthermore, MapReg is followed by pose pooling and pose-to-vertex lifting approaches, which transform 2D pose encodings to semantic features of 3D vertices. Overall, our hand reconstruction framework, called MobRecon, comprises affordable computational costs and miniature model size, which reaches a high inference speed of 83FPS on Apple A14 CPU. Extensive experiments on popular datasets such as FreiHAND, RHD, and HO3Dv2 demonstrate that our MobRecon achieves superior performance on reconstruction accuracy and temporal coherence. Our code is publicly available at https://github.com/SeanChenxy/HandMesh.
Hand Image Understanding via Deep Multi-Task Learning
Jul 28, 2021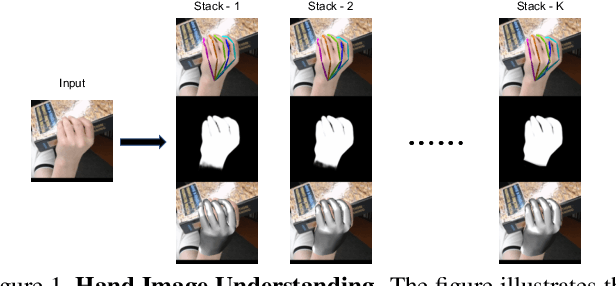

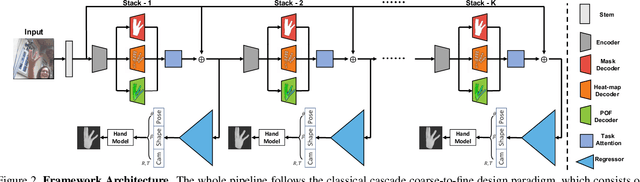
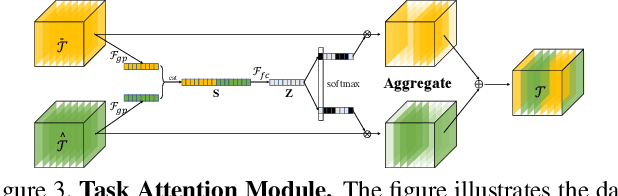
Analyzing and understanding hand information from multimedia materials like images or videos is important for many real world applications and remains active in research community. There are various works focusing on recovering hand information from single image, however, they usually solve a single task, for example, hand mask segmentation, 2D/3D hand pose estimation, or hand mesh reconstruction and perform not well in challenging scenarios. To further improve the performance of these tasks, we propose a novel Hand Image Understanding (HIU) framework to extract comprehensive information of the hand object from a single RGB image, by jointly considering the relationships between these tasks. To achieve this goal, a cascaded multi-task learning (MTL) backbone is designed to estimate the 2D heat maps, to learn the segmentation mask, and to generate the intermediate 3D information encoding, followed by a coarse-to-fine learning paradigm and a self-supervised learning strategy. Qualitative experiments demonstrate that our approach is capable of recovering reasonable mesh representations even in challenging situations. Quantitatively, our method significantly outperforms the state-of-the-art approaches on various widely-used datasets, in terms of diverse evaluation metrics.