 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-MemCluster: Empowering Large Language Models with Dynamic Memory for Text Clustering
Nov 19, 2025Large Language Models (LLMs) are reshaping unsupervised learning by offering an unprecedented ability to perform text clustering based on their deep semantic understanding. However, their direct application is fundamentally limited by a lack of stateful memory for iterative refinement and the difficulty of managing cluster granularity. As a result, existing methods often rely on complex pipelines with external modules, sacrificing a truly end-to-end approach. We introduce LLM-MemCluster, a novel framework that reconceptualizes clustering as a fully LLM-native task. It leverages a Dynamic Memory to instill state awareness and a Dual-Prompt Strategy to enable the model to reason about and determine the number of clusters. Evaluated on several benchmark datasets, our tuning-free framework significantly and consistently outperforms strong baselines. LLM-MemCluster presents an effective, interpretable, and truly end-to-end paradigm for LLM-based text clustering.
LoCoBench-Agent: An Interactive Benchmark for LLM Agents in Long-Context Software Engineering
Nov 17, 2025



As large language models (LLMs) evolve into sophisticated autonomous agents capable of complex software development tasks, evaluating their real-world capabilities becomes critical. While existing benchmarks like LoCoBench~\cite{qiu2025locobench} assess long-context code understanding, they focus on single-turn evaluation and cannot capture the multi-turn interactive nature, tool usage patterns, and adaptive reasoning required by real-world coding agents. We introduce \textbf{LoCoBench-Agent}, a comprehensive evaluation framework specifically designed to assess LLM agents in realistic, long-context software engineering workflows. Our framework extends LoCoBench's 8,000 scenarios into interactive agent environments, enabling systematic evaluation of multi-turn conversations, tool usage efficiency, error recovery, and architectural consistency across extended development sessions. We also introduce an evaluation methodology with 9 metrics across comprehension and efficiency dimensions. Our framework provides agents with 8 specialized tools (file operations, search, code analysis) and evaluates them across context lengths ranging from 10K to 1M tokens, enabling precise assessment of long-context performance. Through systematic evaluation of state-of-the-art models, we reveal several key findings: (1) agents exhibit remarkable long-context robustness; (2) comprehension-efficiency trade-off exists with negative correlation, where thorough exploration increases comprehension but reduces efficiency; and (3) conversation efficiency varies dramatically across models, with strategic tool usage patterns differentiating high-performing agents. As the first long-context LLM agent benchmark for software engineering, LoCoBench-Agent establishes a rigorous foundation for measuring agent capabilities, identifying performance gaps, and advancing autonomous software development at scale.
GeoGNN: Quantifying and Mitigating Semantic Drift in Text-Attributed Graphs
Nov 12, 2025Graph neural networks (GNNs) on text--attributed graphs (TAGs) typically encode node texts using pretrained language models (PLMs) and propagate these embeddings through linear neighborhood aggregation. However, the representation spaces of modern PLMs are highly non--linear and geometrically structured, where textual embeddings reside on curved semantic manifolds rather than flat Euclidean spaces. Linear aggregation on such manifolds inevitably distorts geometry and causes semantic drift--a phenomenon where aggregated representations deviate from the intrinsic manifold, losing semantic fidelity and expressive power. To quantitatively investigate this problem, this work introduces a local PCA--based metric that measures the degree of semantic drift and provides the first quantitative framework to analyze how different aggregation mechanisms affect manifold structure. Building upon these insights, we propose Geodesic Aggregation, a manifold--aware mechanism that aggregates neighbor information along geodesics via log--exp mappings on the unit sphere, ensuring that representations remain faithful to the semantic manifold during message passing. We further develop GeoGNN, a practical instantiation that integrates spherical attention with manifold interpolation. Extensive experiments across four benchmark datasets and multiple text encoders show that GeoGNN substantially mitigates semantic drift and consistently outperforms strong baselines, establishing the importance of manifold--aware aggregation in text--attributed graph learning.
ToolLibGen: Scalable Automatic Tool Creation and Aggregation for LLM Reasoning
Oct 09, 2025



Large Language Models (LLMs) equipped with external tools have demonstrated enhanced performance on complex reasoning tasks. The widespread adoption of this tool-augmented reasoning is hindered by the scarcity of domain-specific tools. For instance, in domains such as physics question answering, suitable and specialized tools are often missing. Recent work has explored automating tool creation by extracting reusable functions from Chain-of-Thought (CoT) reasoning traces; however, these approaches face a critical scalability bottleneck. As the number of generated tools grows, storing them in an unstructured collection leads to significant retrieval challenges, including an expanding search space and ambiguity between function-related tools. To address this, we propose a systematic approach to automatically refactor an unstructured collection of tools into a structured tool library. Our system first generates discrete, task-specific tools and clusters them into semantically coherent topics. Within each cluster, we introduce a multi-agent framework to consolidate scattered functionalities: a code agent refactors code to extract shared logic and creates versatile, aggregated tools, while a reviewing agent ensures that these aggregated tools maintain the complete functional capabilities of the original set. This process transforms numerous question-specific tools into a smaller set of powerful, aggregated tools without loss of functionality. Experimental results demonstrate that our approach significantly improves tool retrieval accuracy and overall reasoning performance across multiple reasoning tasks. Furthermore, our method shows enhanced scalability compared with baselines as the number of question-specific increases.
LoCoBench: A Benchmark for Long-Context Large Language Models in Complex Software Engineering
Sep 11, 2025
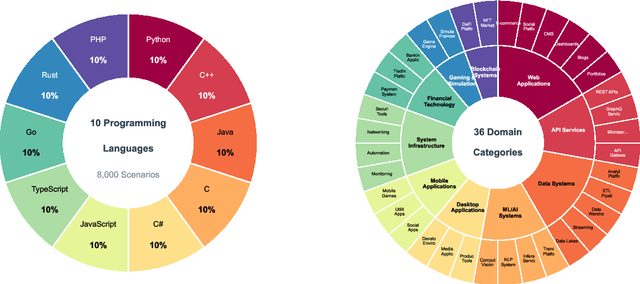

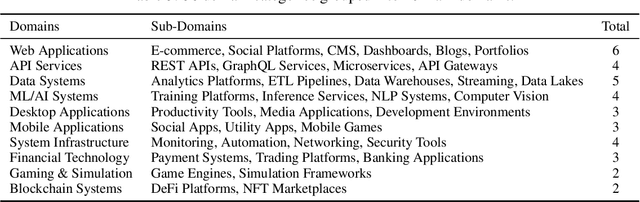
The emergence of long-context language models with context windows extending to millions of tokens has created new opportunities for sophisticated code understanding and software development evaluation. We propose LoCoBench, a comprehensive benchmark specifically designed to evaluate long-context LLMs in realistic, complex software development scenarios. Unlike existing code evaluation benchmarks that focus on single-function completion or short-context tasks, LoCoBench addresses the critical evaluation gap for long-context capabilities that require understanding entire codebases, reasoning across multiple files, and maintaining architectural consistency across large-scale software systems. Our benchmark provides 8,000 evaluation scenarios systematically generated across 10 programming languages, with context lengths spanning 10K to 1M tokens, a 100x variation that enables precise assessment of long-context performance degradation in realistic software development settings. LoCoBench introduces 8 task categories that capture essential long-context capabilities: architectural understanding, cross-file refactoring, multi-session development, bug investigation, feature implementation, code comprehension, integration testing, and security analysis. Through a 5-phase pipeline, we create diverse, high-quality scenarios that challenge LLMs to reason about complex codebases at unprecedented scale. We introduce a comprehensive evaluation framework with 17 metrics across 4 dimensions, including 8 new evaluation metrics, combined in a LoCoBench Score (LCBS). Our evaluation of state-of-the-art long-context models reveals substantial performance gaps, demonstrating that long-context understanding in complex software development represents a significant unsolved challenge that demands more attention. LoCoBench is released at: https://github.com/SalesforceAIResearch/LoCoBench.
SGCL: Unifying Self-Supervised and Supervised Learning for Graph Recommendation
Jul 17, 2025Recommender systems (RecSys) are essential for online platforms, providing personalized suggestions to users within a vast sea of information. Self-supervised graph learning seeks to harness high-order collaborative filtering signals through unsupervised augmentation on the user-item bipartite graph, primarily leveraging a multi-task learning framework that includes both supervised recommendation loss and self-supervised contrastive loss. However, this separate design introduces additional graph convolution processes and creates inconsistencies in gradient directions due to disparate losses, resulting in prolonged training times and sub-optimal performance. In this study, we introduce a unified framework of Supervised Graph Contrastive Learning for recommendation (SGCL) to address these issues. SGCL uniquely combines the training of recommendation and unsupervised contrastive losses into a cohesive supervised contrastive learning loss, aligning both tasks within a single optimization direction for exceptionally fast training. Extensive experiments on three real-world datasets show that SGCL outperforms state-of-the-art methods, achieving superior accuracy and efficiency.
From Web Search towards Agentic Deep Research: Incentivizing Search with Reasoning Agents
Jun 23, 2025Information retrieval is a cornerstone of modern knowledge acquisition, enabling billions of queries each day across diverse domains. However, traditional keyword-based search engines are increasingly inadequate for handling complex, multi-step information needs. Our position is that Large Language Models (LLMs), endowed with reasoning and agentic capabilities, are ushering in a new paradigm termed Agentic Deep Research. These systems transcend conventional information search techniques by tightly integrating autonomous reasoning, iterative retrieval, and information synthesis into a dynamic feedback loop. We trace the evolution from static web search to interactive, agent-based systems that plan, explore, and learn. We also introduce a test-time scaling law to formalize the impact of computational depth on reasoning and search. Supported by benchmark results and the rise of open-source implementations, we demonstrate that Agentic Deep Research not only significantly outperforms existing approaches, but is also poised to become the dominant paradigm for future information seeking. All the related resources, including industry products, research papers, benchmark datasets, and open-source implementations, are collected for the community in https://github.com/DavidZWZ/Awesome-Deep-Research.
Masked Language Models are Good Heterogeneous Graph Generalizers
Jun 06, 2025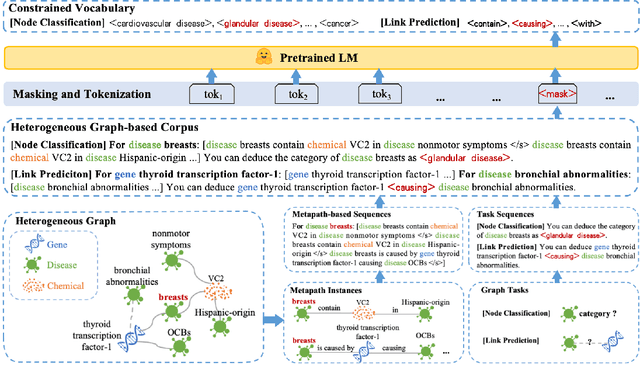
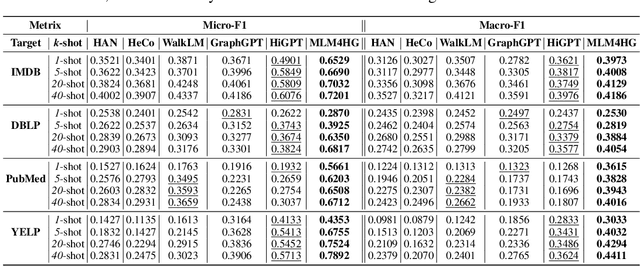
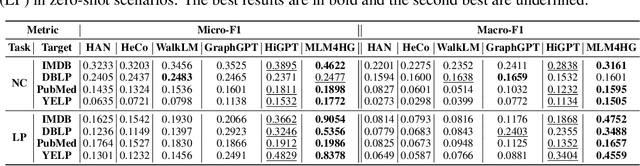
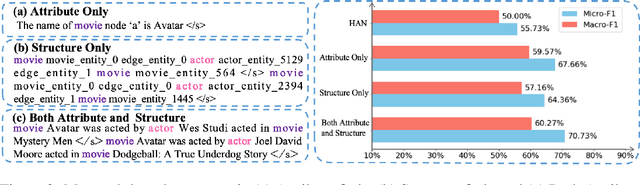
Heterogeneous graph neural networks (HGNNs) excel at capturing structural and semantic information in heterogeneous graphs (HGs), while struggling to generalize across domains and tasks. Recently, some researchers have turned to integrating HGNNs with large language models (LLMs) for more generalizable heterogeneous graph learning. However, these approaches typically extract structural information via HGNNs as HG tokens, and disparities in embedding spaces between HGNNs and LLMs have been shown to bias the LLM's comprehension of HGs. Moreover, as these HG tokens are often derived from node-level tasks, the model's ability to generalize across tasks remains limited. To this end, we propose a simple yet effective Masked Language Modeling-based method, called MLM4HG. MLM4HG introduces metapath-based textual sequences instead of HG tokens to extract structural and semantic information inherent in HGs, and designs customized textual templates to unify different graph tasks into a coherent cloze-style "mask" token prediction paradigm. Specifically, MLM4HG first converts HGs from various domains to texts based on metapaths, and subsequently combines them with the unified task texts to form a HG-based corpus. Moreover, the corpus is fed into a pretrained LM for fine-tuning with a constrained target vocabulary, enabling the fine-tuned LM to generalize to unseen target HGs. Extensive cross-domain and multi-task experiments on four real-world datasets demonstrate the superior generalization performance of MLM4HG over state-of-the-art methods in both few-shot and zero-shot scenarios. Our code is available at https://github.com/BUPT-GAMMA/MLM4HG.
PersonaAgent: When Large Language Model Agents Meet Personalization at Test Time
Jun 06, 2025Large Language Model (LLM) empowered agents have recently emerged as advanced paradigms that exhibit impressive capabilities in a wide range of domains and tasks. Despite their potential, current LLM agents often adopt a one-size-fits-all approach, lacking the flexibility to respond to users' varying needs and preferences. This limitation motivates us to develop PersonaAgent, the first personalized LLM agent framework designed to address versatile personalization tasks. Specifically, PersonaAgent integrates two complementary components - a personalized memory module that includes episodic and semantic memory mechanisms; a personalized action module that enables the agent to perform tool actions tailored to the user. At the core, the persona (defined as unique system prompt for each user) functions as an intermediary: it leverages insights from personalized memory to control agent actions, while the outcomes of these actions in turn refine the memory. Based on the framework, we propose a test-time user-preference alignment strategy that simulate the latest n interactions to optimize the persona prompt, ensuring real-time user preference alignment through textual loss feedback between simulated and ground-truth responses. Experimental evaluations demonstrate that PersonaAgent significantly outperforms other baseline methods by not only personalizing the action space effectively but also scaling during test-time real-world applications. These results underscore the feasibility and potential of our approach in delivering tailored, dynamic user experiences.
Entropy-Based Block Pruning for Efficient Large Language Models
Apr 04, 2025



As large language models continue to scale, their growing computational and storage demands pose significant challenges for real-world deployment. In this work, we investigate redundancy within Transformer-based models and propose an entropy-based pruning strategy to enhance efficiency while maintaining performance. Empirical analysis reveals that the entropy of hidden representations decreases in the early blocks but progressively increases across most subsequent blocks. This trend suggests that entropy serves as a more effective measure of information richness within computation blocks. Unlike cosine similarity, which primarily captures geometric relationships, entropy directly quantifies uncertainty and information content, making it a more reliable criterion for pruning. Extensive experiments demonstrate that our entropy-based pruning approach surpasses cosine similarity-based methods in reducing model size while preserving accuracy, offering a promising direction for efficient model deployment.