 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlending-target Domain Adaptation by Adversarial Meta-Adaptation Networks
Jul 08, 2019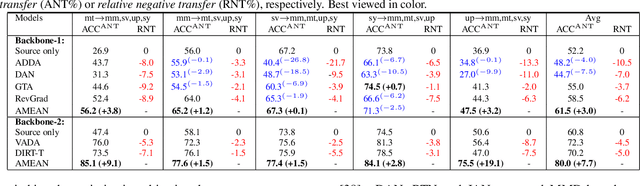
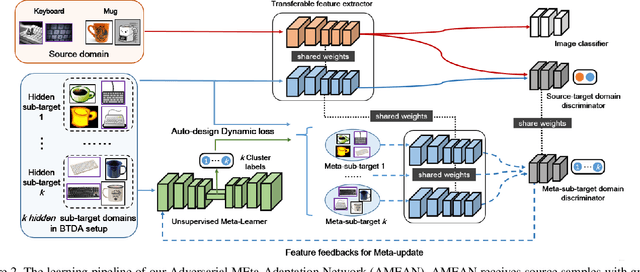
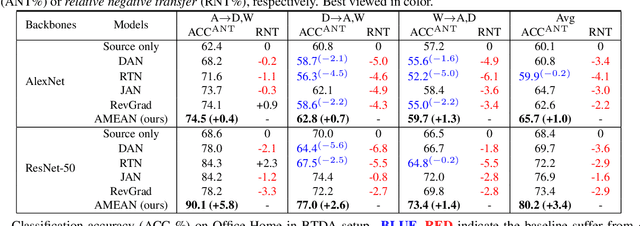
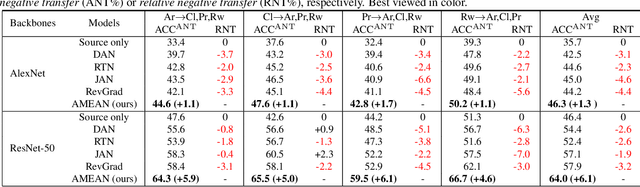
(Unsupervised) Domain Adaptation (DA) seeks for classifying target instances when solely provided with source labeled and target unlabeled examples for training. Learning domain-invariant features helps to achieve this goal, whereas it underpins unlabeled samples drawn from a single or multiple explicit target domains (Multi-target DA). In this paper, we consider a more realistic transfer scenario: our target domain is comprised of multiple sub-targets implicitly blended with each other, so that learners could not identify which sub-target each unlabeled sample belongs to. This Blending-target Domain Adaptation (BTDA) scenario commonly appears in practice and threatens the validities of most existing DA algorithms, due to the presence of domain gaps and categorical misalignments among these hidden sub-targets. To reap the transfer performance gains in this new scenario, we propose Adversarial Meta-Adaptation Network (AMEAN). AMEAN entails two adversarial transfer learning processes. The first is a conventional adversarial transfer to bridge our source and mixed target domains. To circumvent the intra-target category misalignment, the second process presents as ``learning to adapt'': It deploys an unsupervised meta-learner receiving target data and their ongoing feature-learning feedbacks, to discover target clusters as our ``meta-sub-target'' domains. These meta-sub-targets auto-design our meta-sub-target DA loss, which empirically eliminates the implicit category mismatching in our mixed target. We evaluate AMEAN and a variety of DA algorithms in three benchmarks under the BTDA setup. Empirical results show that BTDA is a quite challenging transfer setup for most existing DA algorithms, yet AMEAN significantly outperforms these state-of-the-art baselines and effectively restrains the negative transfer effects in BTDA.
Contextualized Spatial-Temporal Network for Taxi Origin-Destination Demand Prediction
May 15, 2019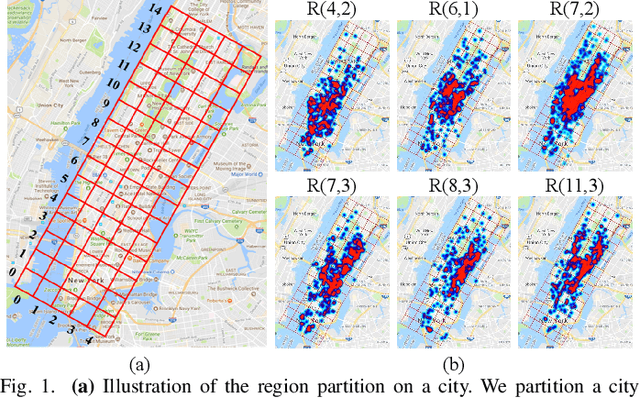
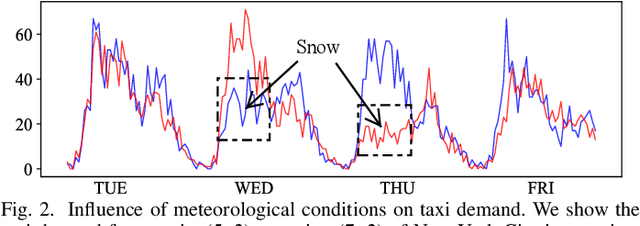
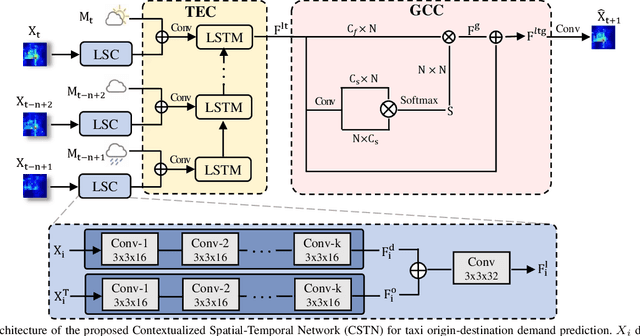
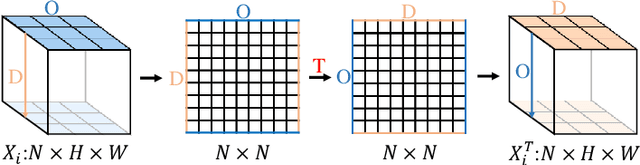
Taxi demand prediction has recently attracted increasing research interest due to its huge potential application in large-scale intelligent transportation systems. However, most of the previous methods only considered the taxi demand prediction in origin regions, but neglected the modeling of the specific situation of the destination passengers. We believe it is suboptimal to preallocate the taxi into each region based solely on the taxi origin demand. In this paper, we present a challenging and worth-exploring task, called taxi origin-destination demand prediction, which aims at predicting the taxi demand between all region pairs in a future time interval. Its main challenges come from how to effectively capture the diverse contextual information to learn the demand patterns. We address this problem with a novel Contextualized Spatial-Temporal Network (CSTN), which consists of three components for the modeling of local spatial context (LSC), temporal evolution context (TEC) and global correlation context (GCC) respectively. Firstly, an LSC module utilizes two convolution neural networks to learn the local spatial dependencies of taxi demand respectively from the origin view and the destination view. Secondly, a TEC module incorporates both the local spatial features of taxi demand and the meteorological information to a Convolutional Long Short-term Memory Network (ConvLSTM) for the analysis of taxi demand evolution. Finally, a GCC module is applied to model the correlation between all regions by computing a global correlation feature as a weighted sum of all regional features, with the weights being calculated as the similarity between the corresponding region pairs. Extensive experiments and evaluations on a large-scale dataset well demonstrate the superiority of our CSTN over other compared methods for taxi origin-destination demand prediction.
Face Hallucination by Attentive Sequence Optimization with Reinforcement Learning
May 04, 2019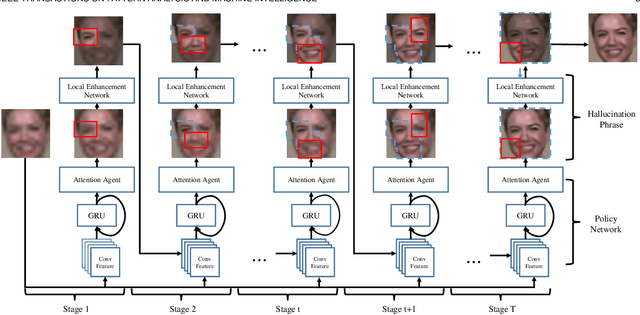
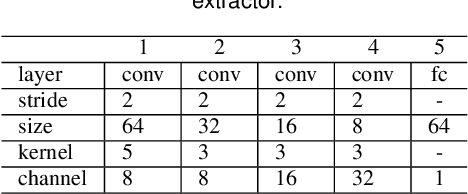
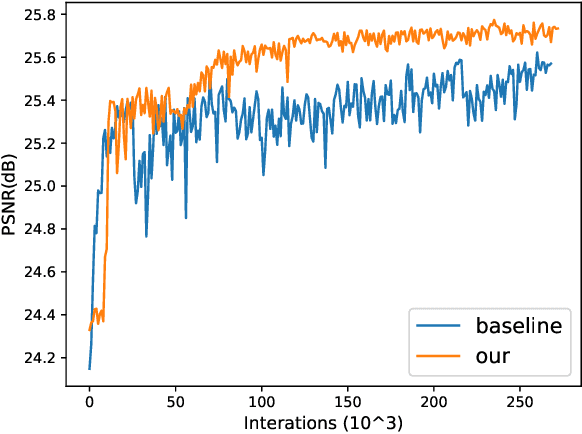
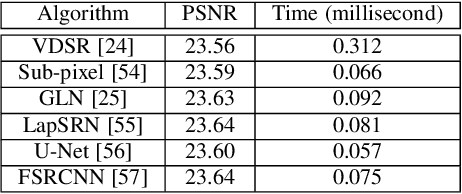
Face hallucination is a domain-specific super-resolution problem that aims to generate a high-resolution (HR) face image from a low-resolution~(LR) input. In contrast to the existing patch-wise super-resolution models that divide a face image into regular patches and independently apply LR to HR mapping to each patch, we implement deep reinforcement learning and develop a novel attention-aware face hallucination (Attention-FH) framework, which recurrently learns to attend a sequence of patches and performs facial part enhancement by fully exploiting the global interdependency of the image. Specifically, our proposed framework incorporates two components: a recurrent policy network for dynamically specifying a new attended region at each time step based on the status of the super-resolved image and the past attended region sequence, and a local enhancement network for selected patch hallucination and global state updating. The Attention-FH model jointly learns the recurrent policy network and local enhancement network through maximizing a long-term reward that reflects the hallucination result with respect to the whole HR image. Extensive experiments demonstrate that our Attention-FH significantly outperforms the state-of-the-art methods on in-the-wild face images with large pose and illumination variations.
Semantic Relationships Guided Representation Learning for Facial Action Unit Recognition
Apr 22, 2019
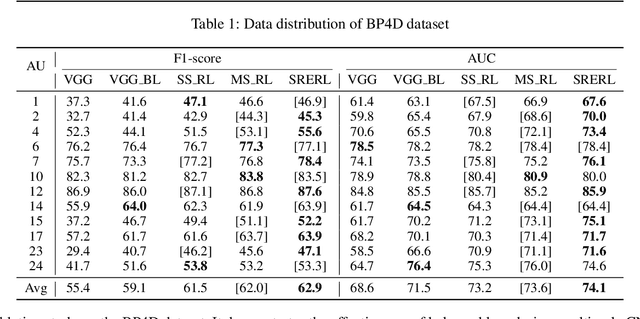
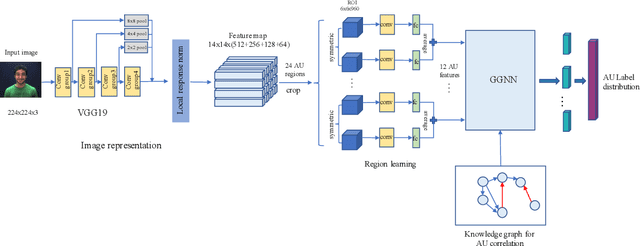
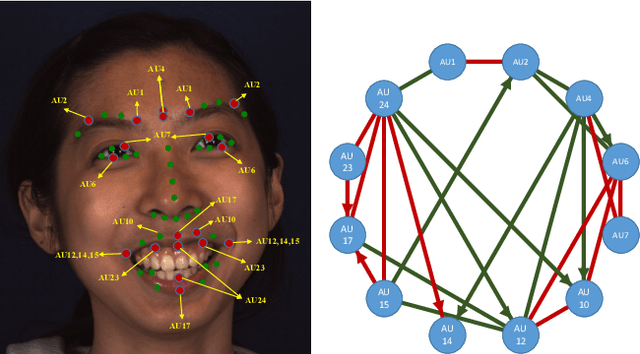
Facial action unit (AU) recognition is a crucial task for facial expressions analysis and has attracted extensive attention in the field of artificial intelligence and computer vision. Existing works have either focused on designing or learning complex regional feature representations, or delved into various types of AU relationship modeling. Albeit with varying degrees of progress, it is still arduous for existing methods to handle complex situations. In this paper, we investigate how to integrate the semantic relationship propagation between AUs in a deep neural network framework to enhance the feature representation of facial regions, and propose an AU semantic relationship embedded representation learning (SRERL) framework. Specifically, by analyzing the symbiosis and mutual exclusion of AUs in various facial expressions, we organize the facial AUs in the form of structured knowledge-graph and integrate a Gated Graph Neural Network (GGNN) in a multi-scale CNN framework to propagate node information through the graph for generating enhanced AU representation. As the learned feature involves both the appearance characteristics and the AU relationship reasoning, the proposed model is more robust and can cope with more challenging cases, e.g., illumination change and partial occlusion. Extensive experiments on the two public benchmarks demonstrate that our method outperforms the previous work and achieves state of the art performance.
Graphonomy: Universal Human Parsing via Graph Transfer Learning
Apr 09, 2019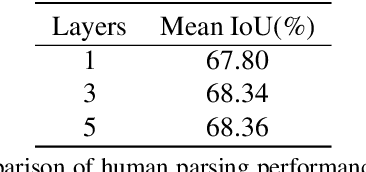



Prior highly-tuned human parsing models tend to fit towards each dataset in a specific domain or with discrepant label granularity, and can hardly be adapted to other human parsing tasks without extensive re-training. In this paper, we aim to learn a single universal human parsing model that can tackle all kinds of human parsing needs by unifying label annotations from different domains or at various levels of granularity. This poses many fundamental learning challenges, e.g. discovering underlying semantic structures among different label granularity, performing proper transfer learning across different image domains, and identifying and utilizing label redundancies across related tasks. To address these challenges, we propose a new universal human parsing agent, named "Graphonomy", which incorporates hierarchical graph transfer learning upon the conventional parsing network to encode the underlying label semantic structures and propagate relevant semantic information. In particular, Graphonomy first learns and propagates compact high-level graph representation among the labels within one dataset via Intra-Graph Reasoning, and then transfers semantic information across multiple datasets via Inter-Graph Transfer. Various graph transfer dependencies (\eg, similarity, linguistic knowledge) between different datasets are analyzed and encoded to enhance graph transfer capability. By distilling universal semantic graph representation to each specific task, Graphonomy is able to predict all levels of parsing labels in one system without piling up the complexity. Experimental results show Graphonomy effectively achieves the state-of-the-art results on three human parsing benchmarks as well as advantageous universal human parsing performance.
Weakly Supervised Person Re-identification: Cost-effective Learning with A New Benchmark
Apr 08, 2019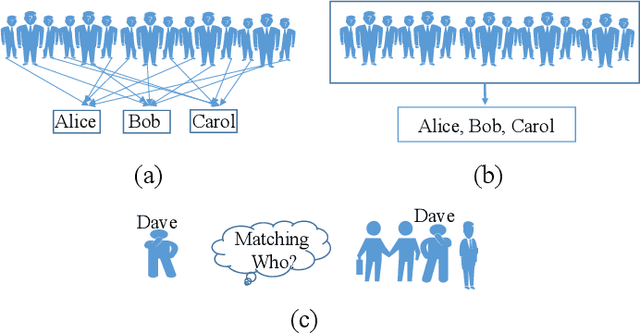
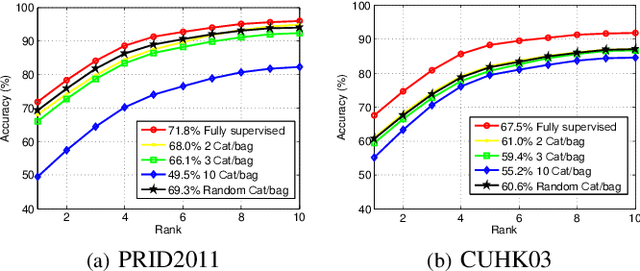
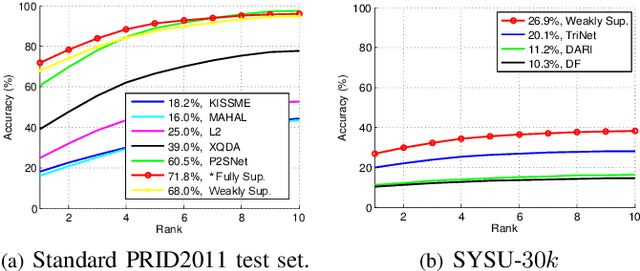
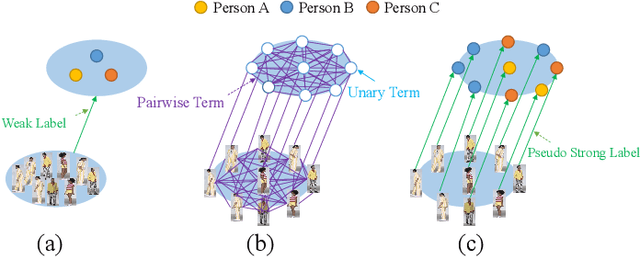
Person re-identification (ReID) benefits greatly from the accurate annotations of existing datasets (e.g., CUHK03 \cite{li2014deepreid} and Market-1501 \cite{zheng2015scalable}), which are quite expensive because each image in these datasets has to be assigned with a proper label. In this work, we explore to ease the annotation of ReID by replacing the accurate annotation with inaccurate annotation, i.e., we group the images into bags in terms of time and assign a bag-level label for each bag. This greatly reduces the annotation effort and leads to the creation of a large-scale ReID benchmark called SYSU-30$k$. The new benchmark contains $30k$ categories of persons, which is about $20$ times larger than CUHK03 ($1.3k$ categories) and Market-1501 ($1.5k$ categories), and $30$ times larger the ImageNet ($1k$ categories). It totally sums up to 29,606,918 images. Learning a ReID model with bag-level annotation is called the weakly supervised ReID problem. To solve this problem, we introduce conditional random fields (CRFs) to capture the dependencies from all images in a bag and generate a reliable pseudo label for each person image. The pseudo label is further used to supervise the learning of the ReID model. When compared with the fully supervised ReID models, our method achieves the state-of-the-art performance on SYSU-30$k$ and other datasets. The code, dataset, and pretrained model will be available online.
Adaptively Connected Neural Networks
Apr 07, 2019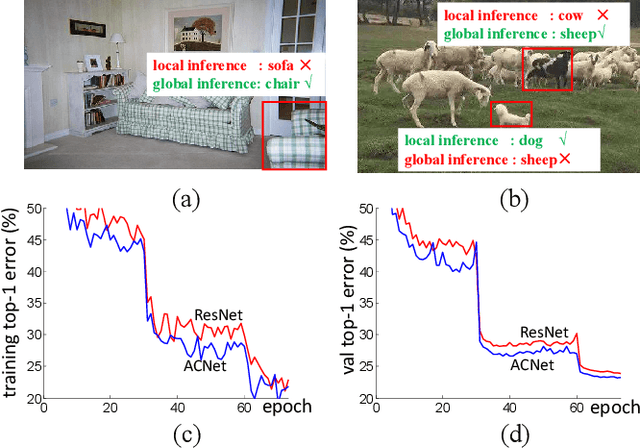

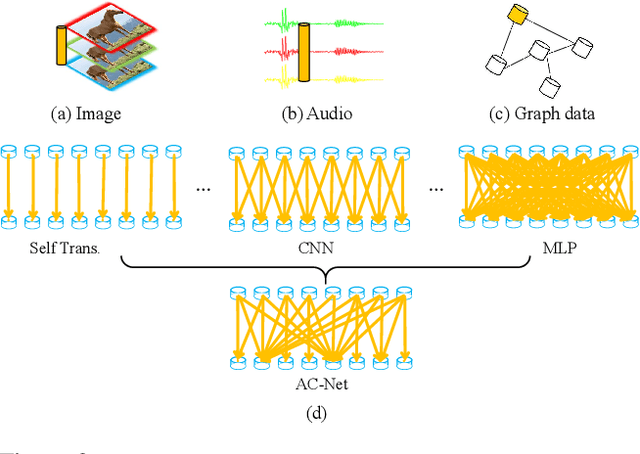

This paper presents a novel adaptively connected neural network (ACNet) to improve the traditional convolutional neural networks (CNNs) {in} two aspects. First, ACNet employs a flexible way to switch global and local inference in processing the internal feature representations by adaptively determining the connection status among the feature nodes (e.g., pixels of the feature maps) \footnote{In a computer vision domain, a node refers to a pixel of a feature map{, while} in {the} graph domain, a node denotes a graph node.}. We can show that existing CNNs, the classical multilayer perceptron (MLP), and the recently proposed non-local network (NLN) \cite{nonlocalnn17} are all special cases of ACNet. Second, ACNet is also capable of handling non-Euclidean data. Extensive experimental analyses on {a variety of benchmarks (i.e.,} ImageNet-1k classification, COCO 2017 detection and segmentation, CUHK03 person re-identification, CIFAR analysis, and Cora document categorization) demonstrate that {ACNet} cannot only achieve state-of-the-art performance but also overcome the limitation of the conventional MLP and CNN \footnote{Corresponding author: Liang Lin (linliang@ieee.org)}. The code is available at \url{https://github.com/wanggrun/Adaptively-Connected-Neural-Networks}.
Weakly-Supervised Discovery of Geometry-Aware Representation for 3D Human Pose Estimation
Mar 27, 2019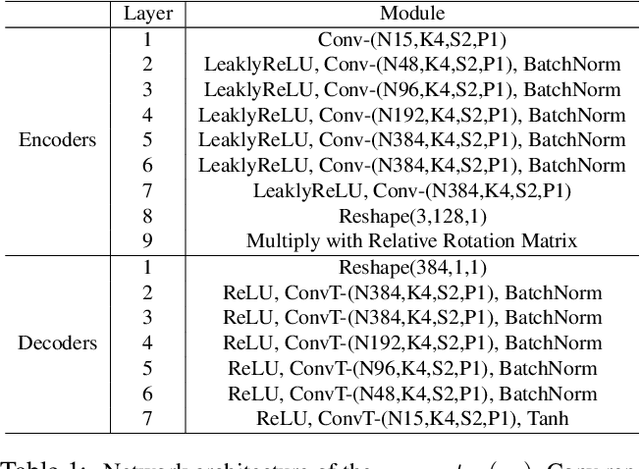
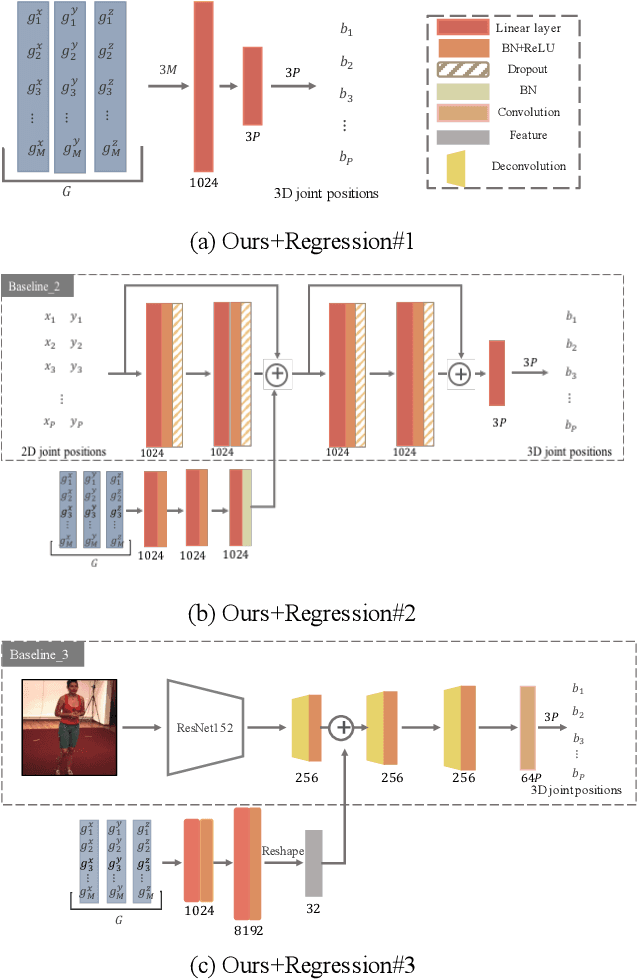
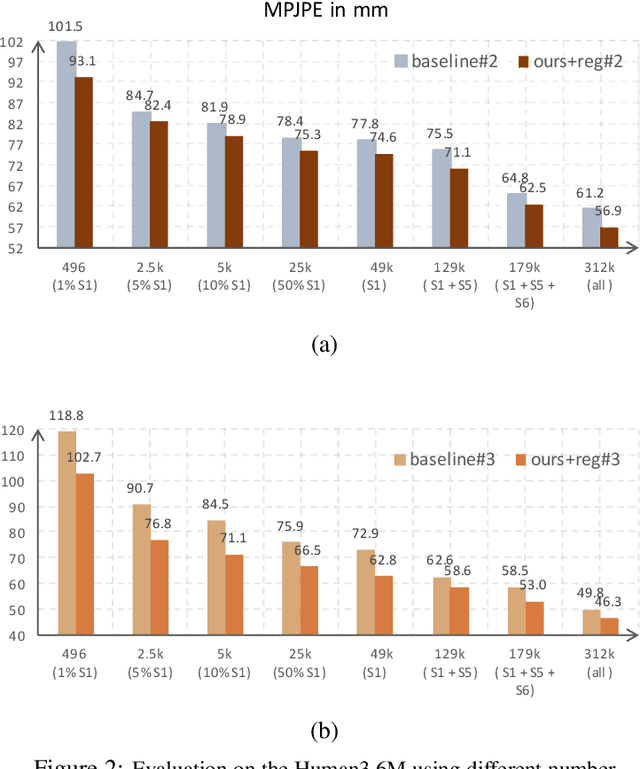
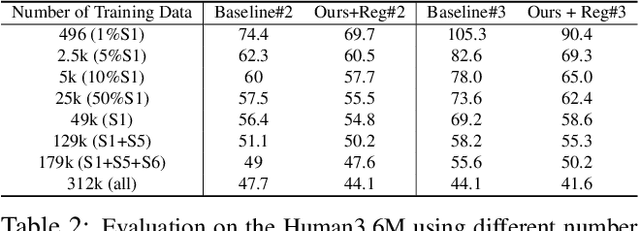
Recent studies have shown remarkable advances in 3D human pose estimation from monocular images, with the help of large-scale in-door 3D datasets and sophisticated network architectures. However, the generalizability to different environments remains an elusive goal. In this work, we propose a geometry-aware 3D representation for the human pose to address this limitation by using multiple views in a simple auto-encoder model at the training stage and only 2D keypoint information as supervision. A view synthesis framework is proposed to learn the shared 3D representation between viewpoints with synthesizing the human pose from one viewpoint to the other one. Instead of performing a direct transfer in the raw image-level, we propose a skeleton-based encoder-decoder mechanism to distil only pose-related representation in the latent space. A learning-based representation consistency constraint is further introduced to facilitate the robustness of latent 3D representation. Since the learnt representation encodes 3D geometry information, mapping it to 3D pose will be much easier than conventional frameworks that use an image or 2D coordinates as the input of 3D pose estimator. We demonstrate our approach on the task of 3D human pose estimation. Comprehensive experiments on three popular benchmarks show that our model can significantly improve the performance of state-of-the-art methods with simply injecting the representation as a robust 3D prior.
End-to-End Knowledge-Routed Relational Dialogue System for Automatic Diagnosis
Mar 18, 2019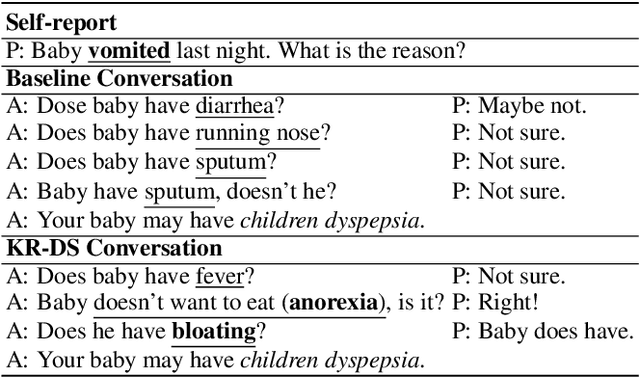
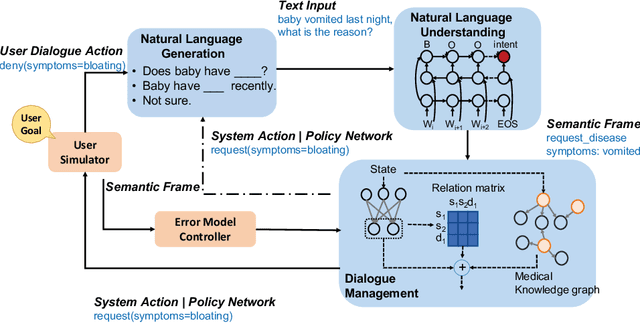
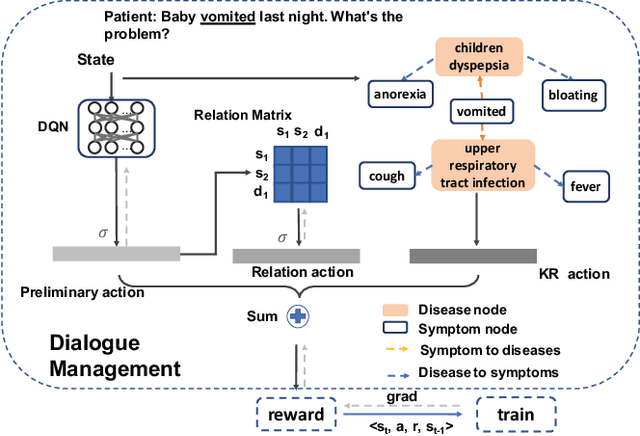

Beyond current conversational chatbots or task-oriented dialogue systems that have attracted increasing attention, we move forward to develop a dialogue system for automatic medical diagnosis that converses with patients to collect additional symptoms beyond their self-reports and automatically makes a diagnosis. Besides the challenges for conversational dialogue systems (e.g. topic transition coherency and question understanding), automatic medical diagnosis further poses more critical requirements for the dialogue rationality in the context of medical knowledge and symptom-disease relations. Existing dialogue systems (Madotto, Wu, and Fung 2018; Wei et al. 2018; Li et al. 2017) mostly rely on data-driven learning and cannot be able to encode extra expert knowledge graph. In this work, we propose an End-to-End Knowledge-routed Relational Dialogue System (KR-DS) that seamlessly incorporates rich medical knowledge graph into the topic transition in dialogue management, and makes it cooperative with natural language understanding and natural language generation. A novel Knowledge-routed Deep Q-network (KR-DQN) is introduced to manage topic transitions, which integrates a relational refinement branch for encoding relations among different symptoms and symptom-disease pairs, and a knowledge-routed graph branch for topic decision-making. Extensive experiments on a public medical dialogue dataset show our KR-DS significantly beats state-of-the-art methods (by more than 8% in diagnosis accuracy). We further show the superiority of our KR-DS on a newly collected medical dialogue system dataset, which is more challenging retaining original self-reports and conversational data between patients and doctors.
Knowledge-Embedded Routing Network for Scene Graph Generation
Mar 08, 2019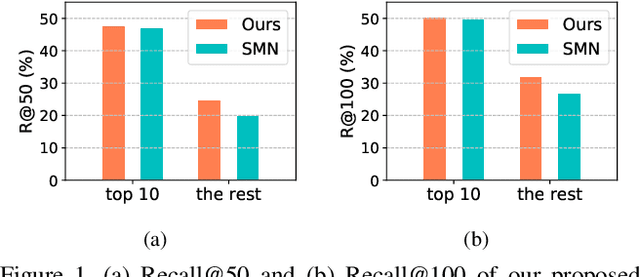
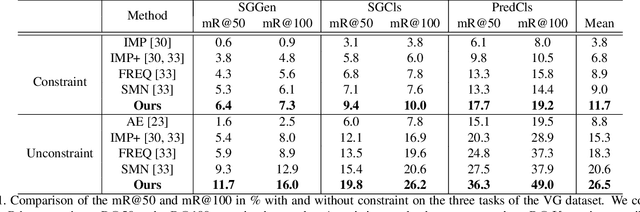
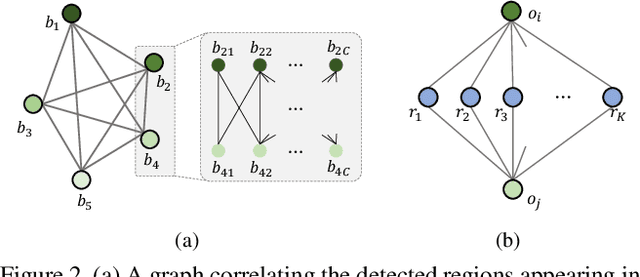
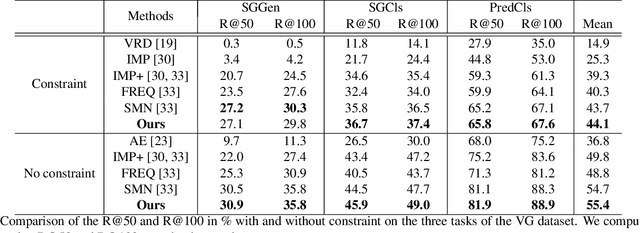
To understand a scene in depth not only involves locating/recognizing individual objects, but also requires to infer the relationships and interactions among them. However, since the distribution of real-world relationships is seriously unbalanced, existing methods perform quite poorly for the less frequent relationships. In this work, we find that the statistical correlations between object pairs and their relationships can effectively regularize semantic space and make prediction less ambiguous, and thus well address the unbalanced distribution issue. To achieve this, we incorporate these statistical correlations into deep neural networks to facilitate scene graph generation by developing a Knowledge-Embedded Routing Network. More specifically, we show that the statistical correlations between objects appearing in images and their relationships, can be explicitly represented by a structured knowledge graph, and a routing mechanism is learned to propagate messages through the graph to explore their interactions. Extensive experiments on the large-scale Visual Genome dataset demonstrate the superiority of the proposed method over current state-of-the-art competitors.