 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFisher-Preserving Guidance: Training-Free Manifold Constraints for Safe Diffusion Control
May 28, 2026Diffusion models are effective for waypoint prediction in visual navigation, but standard sampling and test time guidance can produce unreliable or inefficient trajectories when updates drift off the training manifold. We propose Fisher Preserving Guidance with Outer Product Span Projection, a training-free inference method that avoids large Fisher drift associated with off-distribution actions while optimizing a task objective. Our method computes the Fisher-preserving update via a low-rank Jacobian factorization, requiring only a single backward pass per step and enabling real-time use. We further introduce Truncated Fisher Denoising Sensitivity as an uncertainty signal and use it for robust multi-sample action blending. Experiments on toy and realistic navigation benchmarks, including Maze2D with TSDF-based guidance, PushT with official Diffusion Policy weights, and visual navigation in simulation and on real robots, demonstrate consistent improvements in performance over strong diffusion-policy baselines without additional training.
Learning Reference-Guided Exposure Correction with Hybrid Illumination Characteristics
May 26, 2026We present HICNet, a reference-guided exposure correction framework. A lightweight, content-agnostic encoder distills each image into a compact illumination embedding capturing regional brightness, edge contrast, and higher-order luminance moments. The embedding difference between a source and its reference drives a multi-scale modulation network that combines FiLM-based global adjustment with Photometric Channel Rebalancing for fine-grained, illumination-aware spectral gating, producing exposure-matched outputs while faithfully preserving scene details. A cross-batch contrastive loss orders the illumination manifold, bolstering robustness to diverse lighting conditions. Trained without ground truth or intrinsic decomposition, HICNet attains better accuracy on public benchmarks and generalizes well to entirely unseen scenes.
STaT: Resolving Shape Distortion in Non-Stationary Time Series via Tri-Modal Synergy
May 25, 2026Recent research in time series forecasting frequently investigates the integration of textual and visual modalities with numerical models to better navigate non-stationary environments. Despite delivering solid numerical results, existing multi-modal approaches usually encounter a dilemma: prioritizing the minimization of average errors can result in excessively smooth forecasts that overlook essential fluctuations. To resolve this limitation, we introduce STaT, an innovative multimodal architecture for Symbolic-Temporal-Textual Alignment, which seamlessly unites three synergistic modalities. Specifically, the symbolic modality converts continuous time series into discrete tokens, facilitating the accurate identification of structural patterns and turning points; the temporal modality extracts inherent sequential dependencies; and the textual modality leverages domain semantics to steer the macroscopic forecasting trends. Comprehensive evaluations on eight real-world benchmarks indicate that STaT delivers exceptional performance, enhancing conventional magnitude indicators by up to 8.9% while simultaneously decreasing shape distortion by up to 8.5%.
STRNet: Visual Navigation with Spatio-Temporal Representation through Dynamic Graph Aggregation
Apr 03, 2026Visual navigation requires the robot to reach a specified goal such as an image, based on a sequence of first-person visual observations. While recent learning-based approaches have made significant progress, they often focus on improving policy heads or decision strategies while relying on simplistic feature encoders and temporal pooling to represent visual input. This leads to the loss of fine-grained spatial and temporal structure, ultimately limiting accurate action prediction and progress estimation. In this paper, we propose a unified spatio-temporal representation framework that enhances visual encoding for robotic navigation. Our approach extracts features from both image sequences and goal observations, and fuses them using the designed spatio-temporal fusion module. This module performs spatial graph reasoning within each frame and models temporal dynamics using a hybrid temporal shift module combined with multi-resolution difference-aware convolution. Experimental results demonstrate that our approach consistently improves navigation performance and offers a generalizable visual backbone for goal-conditioned control. Code is available at \href{https://github.com/hren20/STRNet}{https://github.com/hren20/STRNet}.
Unidirectional-Road-Network-Based Global Path Planning for Cleaning Robots in Semi-Structured Environments
Nov 17, 2025Practical global path planning is critical for commercializing cleaning robots working in semi-structured environments. In the literature, global path planning methods for free space usually focus on path length and neglect the traffic rule constraints of the environments, which leads to high-frequency re-planning and increases collision risks. In contrast, those for structured environments are developed mainly by strictly complying with the road network representing the traffic rule constraints, which may result in an overlong path that hinders the overall navigation efficiency. This article proposes a general and systematic approach to improve global path planning performance in semi-structured environments. A unidirectional road network is built to represent the traffic constraints in semi-structured environments and a hybrid strategy is proposed to achieve a guaranteed planning result.Cutting across the road at the starting and the goal points are allowed to achieve a shorter path. Especially, a two-layer potential map is proposed to achieve a guaranteed performance when the starting and the goal points are in complex intersections. Comparative experiments are carried out to validate the effectiveness of the proposed method. Quantitative experimental results show that, compared with the state-of-art, the proposed method guarantees a much better balance between path length and the consistency with the road network.
TOPP-DWR: Time-Optimal Path Parameterization of Differential-Driven Wheeled Robots Considering Piecewise-Constant Angular Velocity Constraints
Nov 17, 2025



Differential-driven wheeled robots (DWR) represent the quintessential type of mobile robots and find extensive appli- cations across the robotic field. Most high-performance control approaches for DWR explicitly utilize the linear and angular velocities of the trajectory as control references. However, existing research on time-optimal path parameterization (TOPP) for mobile robots usually neglects the angular velocity and joint vel- ocity constraints, which can result in degraded control perfor- mance in practical applications. In this article, a systematic and practical TOPP algorithm named TOPP-DWR is proposed for DWR and other mobile robots. First, the non-uniform B-spline is adopted to represent the initial trajectory in the task space. Second, the piecewise-constant angular velocity, as well as joint velocity, linear velocity, and linear acceleration constraints, are incorporated into the TOPP problem. During the construction of the optimization problem, the aforementioned constraints are uniformly represented as linear velocity constraints. To boost the numerical computational efficiency, we introduce a slack variable to reformulate the problem into second-order-cone programming (SOCP). Subsequently, comparative experiments are conducted to validate the superiority of the proposed method. Quantitative performance indexes show that TOPP-DWR achieves TOPP while adhering to all constraints. Finally, field autonomous navigation experiments are carried out to validate the practicability of TOPP-DWR in real-world applications.
APP: A* Post-Processing Algorithm for Robots with Bidirectional Shortcut and Path Perturbation
Nov 17, 2025Paths generated by A* and other graph-search-based planners are widely used in the robotic field. Due to the restricted node-expansion directions, the resulting paths are usually not the shortest. Besides, unnecessary heading changes, or zig-zag patterns, exist even when no obstacle is nearby, which is inconsistent with the human intuition that the path segments should be straight in wide-open space due to the absence of obstacles. This article puts forward a general and systematic post-processing algorithm for A* and other graph-search-based planners. The A* post-processing algorithm, called APP, is developed based on the costmap, which is widely used in commercial service robots. First, a bidirectional vertices reduction algorithm is proposed to tackle the asymm- etry of the path and the environments. During the forward and backward vertices reduction, a thorough shortcut strategy is put forward to improve the path-shortening performance and avoid unnecessary heading changes. Second, an iterative path perturbation algorithm is adopted to locally reduce the number of unnecessary heading changes and improve the path smooth- ness. Comparative experiments are then carried out to validate the superiority of the proposed method. Quantitative performance indexes show that APP outperforms the existing methods in planning time, path length as well as the number of unnecessary heading changes. Finally, field navigation experiments are carried out to verify the practicability of APP.
RAPID Hand: A Robust, Affordable, Perception-Integrated, Dexterous Manipulation Platform for Generalist Robot Autonomy
Jun 09, 2025
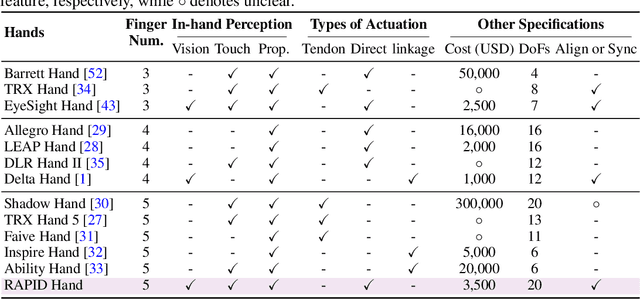


This paper addresses the scarcity of low-cost but high-dexterity platforms for collecting real-world multi-fingered robot manipulation data towards generalist robot autonomy. To achieve it, we propose the RAPID Hand, a co-optimized hardware and software platform where the compact 20-DoF hand, robust whole-hand perception, and high-DoF teleoperation interface are jointly designed. Specifically, RAPID Hand adopts a compact and practical hand ontology and a hardware-level perception framework that stably integrates wrist-mounted vision, fingertip tactile sensing, and proprioception with sub-7 ms latency and spatial alignment. Collecting high-quality demonstrations on high-DoF hands is challenging, as existing teleoperation methods struggle with precision and stability on complex multi-fingered systems. We address this by co-optimizing hand design, perception integration, and teleoperation interface through a universal actuation scheme, custom perception electronics, and two retargeting constraints. We evaluate the platform's hardware, perception, and teleoperation interface. Training a diffusion policy on collected data shows superior performance over prior works, validating the system's capability for reliable, high-quality data collection. The platform is constructed from low-cost and off-the-shelf components and will be made public to ensure reproducibility and ease of adoption.
GET: Goal-directed Exploration and Targeting for Large-Scale Unknown Environments
May 28, 2025Object search in large-scale, unstructured environments remains a fundamental challenge in robotics, particularly in dynamic or expansive settings such as outdoor autonomous exploration. This task requires robust spatial reasoning and the ability to leverage prior experiences. While Large Language Models (LLMs) offer strong semantic capabilities, their application in embodied contexts is limited by a grounding gap in spatial reasoning and insufficient mechanisms for memory integration and decision consistency.To address these challenges, we propose GET (Goal-directed Exploration and Targeting), a framework that enhances object search by combining LLM-based reasoning with experience-guided exploration. At its core is DoUT (Diagram of Unified Thought), a reasoning module that facilitates real-time decision-making through a role-based feedback loop, integrating task-specific criteria and external memory. For repeated tasks, GET maintains a probabilistic task map based on a Gaussian Mixture Model, allowing for continual updates to object-location priors as environments evolve.Experiments conducted in real-world, large-scale environments demonstrate that GET improves search efficiency and robustness across multiple LLMs and task settings, significantly outperforming heuristic and LLM-only baselines. These results suggest that structured LLM integration provides a scalable and generalizable approach to embodied decision-making in complex environments.
Bootstrapping Imitation Learning for Long-horizon Manipulation via Hierarchical Data Collection Space
May 23, 2025Imitation learning (IL) with human demonstrations is a promising method for robotic manipulation tasks. While minimal demonstrations enable robotic action execution, achieving high success rates and generalization requires high cost, e.g., continuously adding data or incrementally conducting human-in-loop processes with complex hardware/software systems. In this paper, we rethink the state/action space of the data collection pipeline as well as the underlying factors responsible for the prediction of non-robust actions. To this end, we introduce a Hierarchical Data Collection Space (HD-Space) for robotic imitation learning, a simple data collection scheme, endowing the model to train with proactive and high-quality data. Specifically, We segment the fine manipulation task into multiple key atomic tasks from a high-level perspective and design atomic state/action spaces for human demonstrations, aiming to generate robust IL data. We conduct empirical evaluations across two simulated and five real-world long-horizon manipulation tasks and demonstrate that IL policy training with HD-Space-based data can achieve significantly enhanced policy performance. HD-Space allows the use of a small amount of demonstration data to train a more powerful policy, particularly for long-horizon manipulation tasks. We aim for HD-Space to offer insights into optimizing data quality and guiding data scaling. project page: https://hd-space-robotics.github.io.