 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Conformer: Optimizing size, speed and flops of Conformer for on-Device and cloud ASR
Mar 31, 2023



Conformer models maintain a large number of internal states, the vast majority of which are associated with self-attention layers. With limited memory bandwidth, reading these from memory at each inference step can slow down inference. In this paper, we design an optimized conformer that is small enough to meet on-device restrictions and has fast inference on TPUs. We explore various ideas to improve the execution speed, including replacing lower conformer blocks with convolution-only blocks, strategically downsizing the architecture, and utilizing an RNNAttention-Performer. Our optimized conformer can be readily incorporated into a cascaded-encoder setting, allowing a second-pass decoder to operate on its output and improve the accuracy whenever more resources are available. Altogether, we find that these optimizations can reduce latency by a factor of 6.8x, and come at a reasonable trade-off in quality. With the cascaded second-pass, we show that the recognition accuracy is completely recoverable. Thus, our proposed encoder can double as a strong standalone encoder in on device, and as the first part of a high-performance ASR pipeline.
Efficient Graph Field Integrators Meet Point Clouds
Feb 05, 2023



We present two new classes of algorithms for efficient field integration on graphs encoding point clouds. The first class, SeparatorFactorization(SF), leverages the bounded genus of point cloud mesh graphs, while the second class, RFDiffusion(RFD), uses popular epsilon-nearest-neighbor graph representations for point clouds. Both can be viewed as providing the functionality of Fast Multipole Methods (FMMs), which have had a tremendous impact on efficient integration, but for non-Euclidean spaces. We focus on geometries induced by distributions of walk lengths between points (e.g., shortest-path distance). We provide an extensive theoretical analysis of our algorithms, obtaining new results in structural graph theory as a byproduct. We also perform exhaustive empirical evaluation, including on-surface interpolation for rigid and deformable objects (particularly for mesh-dynamics modeling), Wasserstein distance computations for point clouds, and the Gromov-Wasserstein variant.
FAVOR#: Sharp Attention Kernel Approximations via New Classes of Positive Random Features
Feb 01, 2023



The problem of efficient approximation of a linear operator induced by the Gaussian or softmax kernel is often addressed using random features (RFs) which yield an unbiased approximation of the operator's result. Such operators emerge in important applications ranging from kernel methods to efficient Transformers. We propose parameterized, positive, non-trigonometric RFs which approximate Gaussian and softmax-kernels. In contrast to traditional RF approximations, parameters of these new methods can be optimized to reduce the variance of the approximation, and the optimum can be expressed in closed form. We show that our methods lead to variance reduction in practice ($e^{10}$-times smaller variance and beyond) and outperform previous methods in a kernel regression task. Using our proposed mechanism, we also present FAVOR#, a method for self-attention approximation in Transformers. We show that FAVOR# outperforms other random feature methods in speech modelling and natural language processing.
Simplex Random Features
Jan 31, 2023



We present Simplex Random Features (SimRFs), a new random feature (RF) mechanism for unbiased approximation of the softmax and Gaussian kernels by geometrical correlation of random projection vectors. We prove that SimRFs provide the smallest possible mean square error (MSE) on unbiased estimates of these kernels among the class of weight-independent geometrically-coupled positive random feature (PRF) mechanisms, substantially outperforming the previously most accurate Orthogonal Random Features at no observable extra cost. We present a more computationally expensive SimRFs+ variant, which we prove is asymptotically optimal in the broader family of weight-dependent geometrical coupling schemes (which permit correlations between random vector directions and norms). In extensive empirical studies, we show consistent gains provided by SimRFs in settings including pointwise kernel estimation, nonparametric classification and scalable Transformers.
Automated Deep Aberration Detection from Chromosome Karyotype Images
Nov 30, 2022Chromosome analysis is essential for diagnosing genetic disorders. For hematologic malignancies, identification of somatic clonal aberrations by karyotype analysis remains the standard of care. However, karyotyping is costly and time-consuming because of the largely manual process and the expertise required in identifying and annotating aberrations. Efforts to automate karyotype analysis to date fell short in aberration detection. Using a training set of ~10k patient specimens and ~50k karyograms from over 5 years from the Fred Hutchinson Cancer Center, we created a labeled set of images representing individual chromosomes. These individual chromosomes were used to train and assess deep learning models for classifying the 24 human chromosomes and identifying chromosomal aberrations. The top-accuracy models utilized the recently introduced Topological Vision Transformers (TopViTs) with 2-level-block-Toeplitz masking, to incorporate structural inductive bias. TopViT outperformed CNN (Inception) models with >99.3% accuracy for chromosome identification, and exhibited accuracies >99% for aberration detection in most aberrations. Notably, we were able to show high-quality performance even in "few shot" learning scenarios. Incorporating the definition of clonality substantially improved both precision and recall (sensitivity). When applied to "zero shot" scenarios, the model captured aberrations without training, with perfect precision at >50% recall. Together these results show that modern deep learning models can approach expert-level performance for chromosome aberration detection. To our knowledge, this is the first study demonstrating the downstream effectiveness of TopViTs. These results open up exciting opportunities for not only expediting patient results but providing a scalable technology for early screening of low-abundance chromosomal lesions.
Learning Model Predictive Controllers with Real-Time Attention for Real-World Navigation
Sep 24, 2022
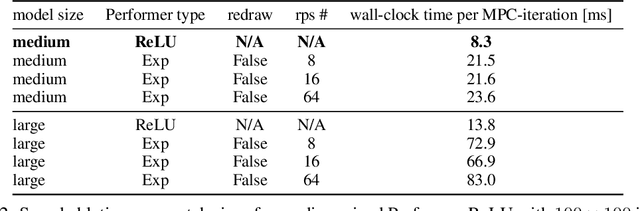


Despite decades of research, existing navigation systems still face real-world challenges when deployed in the wild, e.g., in cluttered home environments or in human-occupied public spaces. To address this, we present a new class of implicit control policies combining the benefits of imitation learning with the robust handling of system constraints from Model Predictive Control (MPC). Our approach, called Performer-MPC, uses a learned cost function parameterized by vision context embeddings provided by Performers -- a low-rank implicit-attention Transformer. We jointly train the cost function and construct the controller relying on it, effectively solving end-to-end the corresponding bi-level optimization problem. We show that the resulting policy improves standard MPC performance by leveraging a few expert demonstrations of the desired navigation behavior in different challenging real-world scenarios. Compared with a standard MPC policy, Performer-MPC achieves >40% better goal reached in cluttered environments and >65% better on social metrics when navigating around humans.
Multiple View Performers for Shape Completion
Sep 13, 2022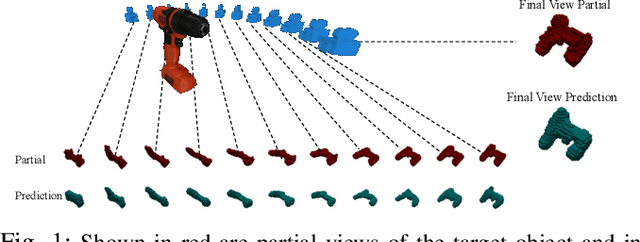
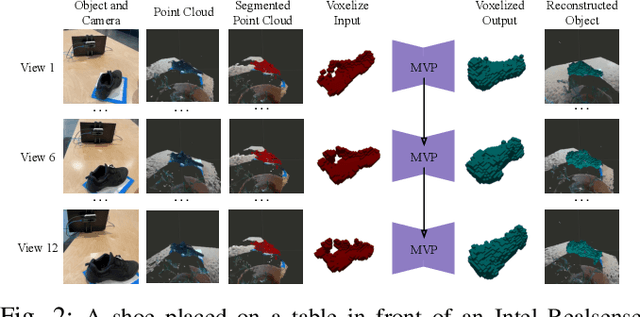
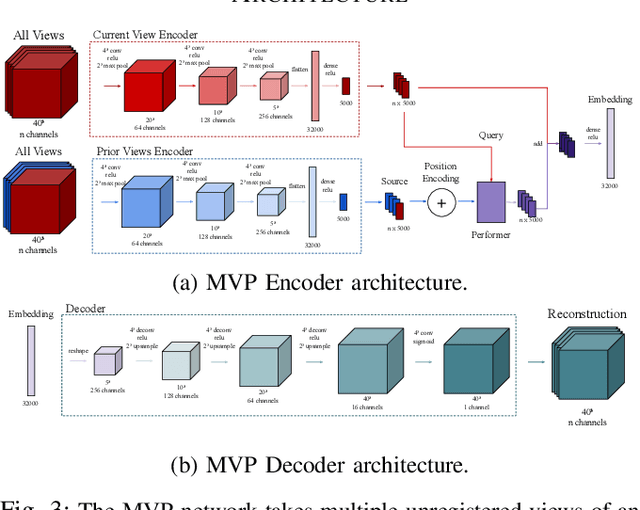
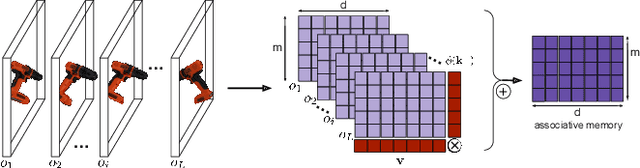
We propose the Multiple View Performer (MVP) - a new architecture for 3D shape completion from a series of temporally sequential views. MVP accomplishes this task by using linear-attention Transformers called Performers. Our model allows the current observation of the scene to attend to the previous ones for more accurate infilling. The history of past observations is compressed via the compact associative memory approximating modern continuous Hopfield memory, but crucially of size independent from the history length. We compare our model with several baselines for shape completion over time, demonstrating the generalization gains that MVP provides. To the best of our knowledge, MVP is the first multiple view voxel reconstruction method that does not require registration of multiple depth views and the first causal Transformer based model for 3D shape completion.
Implicit Two-Tower Policies
Aug 02, 2022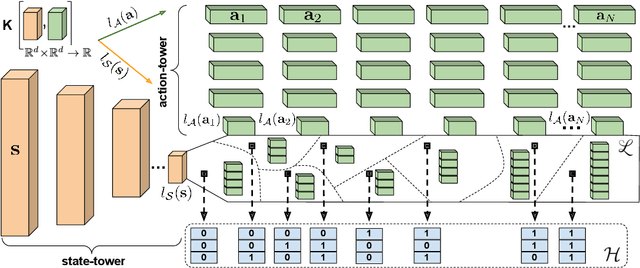
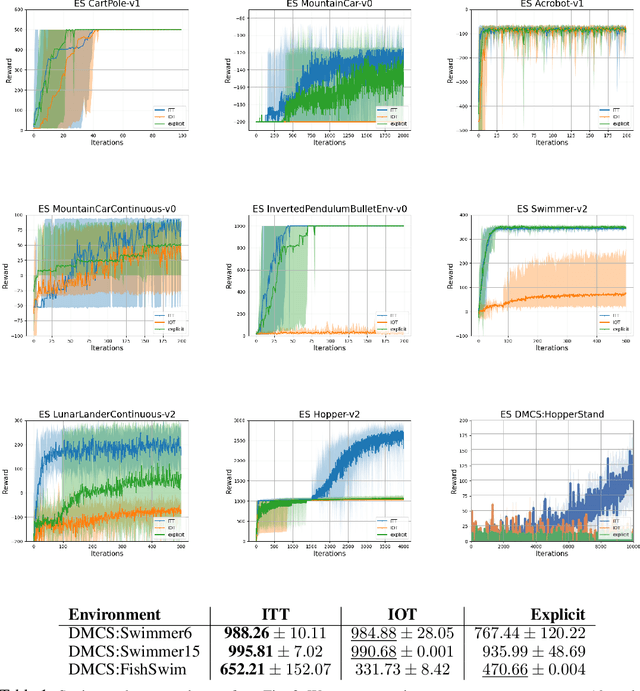
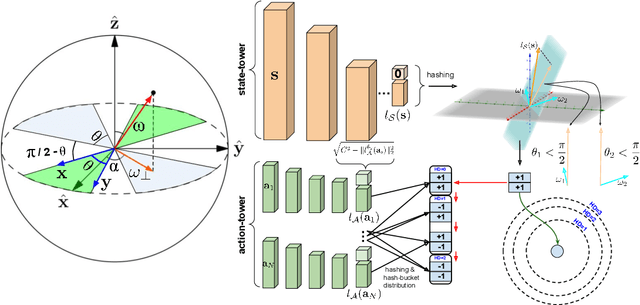
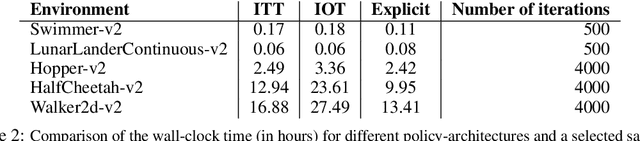
We present a new class of structured reinforcement learning policy-architectures, Implicit Two-Tower (ITT) policies, where the actions are chosen based on the attention scores of their learnable latent representations with those of the input states. By explicitly disentangling action from state processing in the policy stack, we achieve two main goals: substantial computational gains and better performance. Our architectures are compatible with both: discrete and continuous action spaces. By conducting tests on 15 environments from OpenAI Gym and DeepMind Control Suite, we show that ITT-architectures are particularly suited for blackbox/evolutionary optimization and the corresponding policy training algorithms outperform their vanilla unstructured implicit counterparts as well as commonly used explicit policies. We complement our analysis by showing how techniques such as hashing and lazy tower updates, critically relying on the two-tower structure of ITTs, can be applied to obtain additional computational improvements.
Chefs' Random Tables: Non-Trigonometric Random Features
May 30, 2022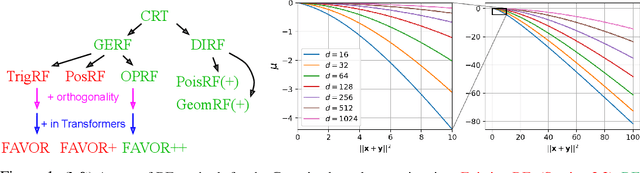
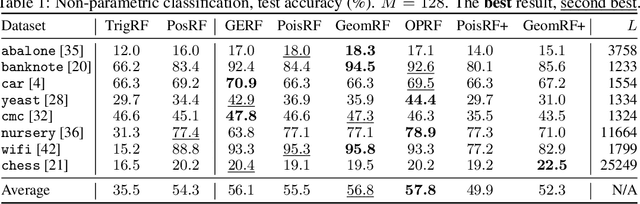
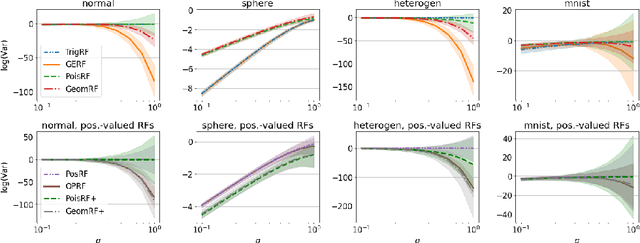
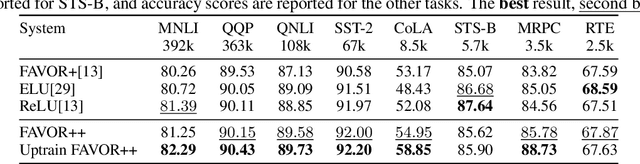
We introduce chefs' random tables (CRTs), a new class of non-trigonometric random features (RFs) to approximate Gaussian and softmax kernels. CRTs are an alternative to standard random kitchen sink (RKS) methods, which inherently rely on the trigonometric maps. We present variants of CRTs where RFs are positive, a key requirement for applications in recent low-rank Transformers. Further variance reduction is possible by leveraging statistics which are simple to compute. One instantiation of CRTs, the optimal positive random features (OPRFs), is to our knowledge the first RF method for unbiased softmax kernel estimation with positive and bounded RFs, resulting in exponentially small tails and much lower variance than its counterparts. As we show, orthogonal random features applied in OPRFs provide additional variance reduction for any dimensionality $d$ (not only asymptotically for sufficiently large $d$, as for RKS). We test CRTs on many tasks ranging from non-parametric classification to training Transformers for text, speech and image data, obtaining new state-of-the-art results for low-rank text Transformers, while providing linear space and time complexity.
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
Apr 01, 2022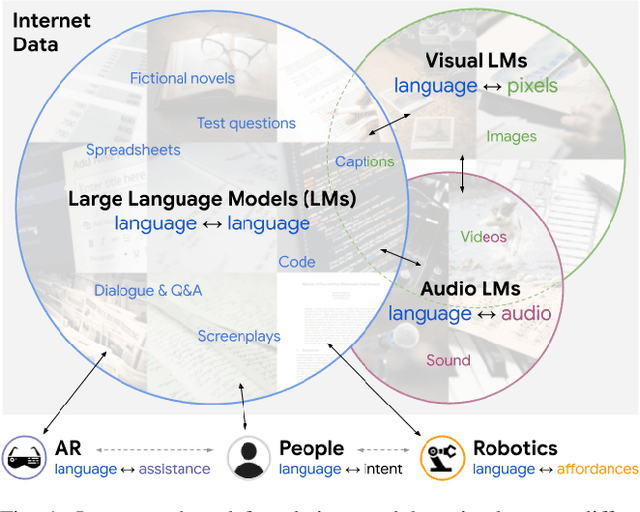
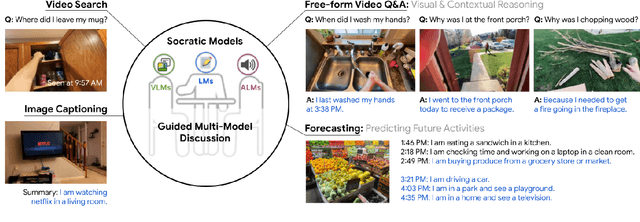
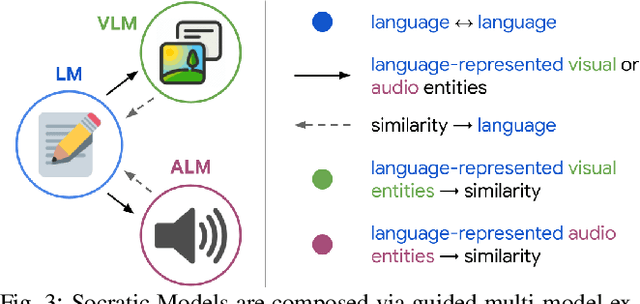
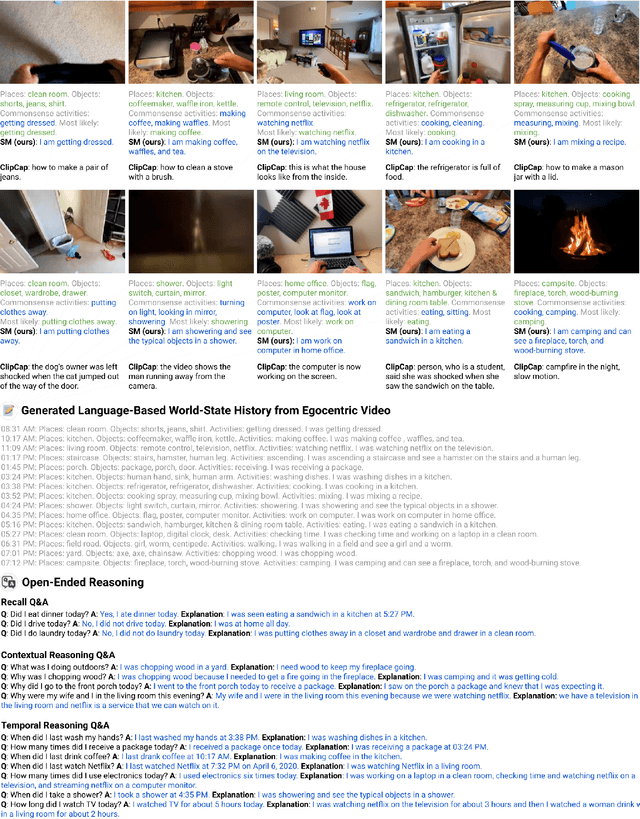
Large foundation models can exhibit unique capabilities depending on the domain of data they are trained on. While these domains are generic, they may only barely overlap. For example, visual-language models (VLMs) are trained on Internet-scale image captions, but large language models (LMs) are further trained on Internet-scale text with no images (e.g. from spreadsheets, to SAT questions). As a result, these models store different forms of commonsense knowledge across different domains. In this work, we show that this model diversity is symbiotic, and can be leveraged to build AI systems with structured Socratic dialogue -- in which new multimodal tasks are formulated as a guided language-based exchange between different pre-existing foundation models, without additional finetuning. In the context of egocentric perception, we present a case study of Socratic Models (SMs) that can provide meaningful results for complex tasks such as generating free-form answers to contextual questions about egocentric video, by formulating video Q&A as short story Q&A, i.e. summarizing the video into a short story, then answering questions about it. Additionally, SMs can generate captions for Internet images, and are competitive with state-of-the-art on zero-shot video-to-text retrieval with 42.8 R@1 on MSR-VTT 1k-A. SMs demonstrate how to compose foundation models zero-shot to capture new multimodal functionalities, without domain-specific data collection. Prototypes are available at socraticmodels.github.io.