 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAR3D: Creating High-Quality 3D Assets via Next-Part Prediction
Dec 22, 2024



We present TAR3D, a novel framework that consists of a 3D-aware Vector Quantized-Variational AutoEncoder (VQ-VAE) and a Generative Pre-trained Transformer (GPT) to generate high-quality 3D assets. The core insight of this work is to migrate the multimodal unification and promising learning capabilities of the next-token prediction paradigm to conditional 3D object generation. To achieve this, the 3D VQ-VAE first encodes a wide range of 3D shapes into a compact triplane latent space and utilizes a set of discrete representations from a trainable codebook to reconstruct fine-grained geometries under the supervision of query point occupancy. Then, the 3D GPT, equipped with a custom triplane position embedding called TriPE, predicts the codebook index sequence with prefilling prompt tokens in an autoregressive manner so that the composition of 3D geometries can be modeled part by part. Extensive experiments on ShapeNet and Objaverse demonstrate that TAR3D can achieve superior generation quality over existing methods in text-to-3D and image-to-3D tasks
Covariances for Free: Exploiting Mean Distributions for Federated Learning with Pre-Trained Models
Dec 18, 2024



Using pre-trained models has been found to reduce the effect of data heterogeneity and speed up federated learning algorithms. Recent works have investigated the use of first-order statistics and second-order statistics to aggregate local client data distributions at the server and achieve very high performance without any training. In this work we propose a training-free method based on an unbiased estimator of class covariance matrices. Our method, which only uses first-order statistics in the form of class means communicated by clients to the server, incurs only a fraction of the communication costs required by methods based on communicating second-order statistics. We show how these estimated class covariances can be used to initialize a linear classifier, thus exploiting the covariances without actually sharing them. When compared to state-of-the-art methods which also share only class means, our approach improves performance in the range of 4-26\% with exactly the same communication cost. Moreover, our method achieves performance competitive or superior to sharing second-order statistics with dramatically less communication overhead. Finally, using our method to initialize classifiers and then performing federated fine-tuning yields better and faster convergence. Code is available at https://github.com/dipamgoswami/FedCOF.
Faster Vision Mamba is Rebuilt in Minutes via Merged Token Re-training
Dec 17, 2024



Vision Mamba (e.g., Vim) has successfully been integrated into computer vision, and token reduction has yielded promising outcomes in Vision Transformers (ViTs). However, token reduction performs less effectively on Vision Mamba compared to ViTs. Pruning informative tokens in Mamba leads to a high loss of key knowledge and bad performance. This makes it not a good solution for enhancing efficiency in Mamba. Token merging, which preserves more token information than pruning, has demonstrated commendable performance in ViTs. Nevertheless, vanilla merging performance decreases as the reduction ratio increases either, failing to maintain the key knowledge in Mamba. Re-training the token-reduced model enhances the performance of Mamba, by effectively rebuilding the key knowledge. Empirically, pruned Vims only drop up to 0.9% accuracy on ImageNet-1K, recovered by our proposed framework R-MeeTo in our main evaluation. We show how simple and effective the fast recovery can be achieved at minute-level, in particular, a 35.9% accuracy spike over 3 epochs of training on Vim-Ti. Moreover, Vim-Ti/S/B are re-trained within 5/7/17 minutes, and Vim-S only drop 1.3% with 1.2x (up to 1.5x) speed up in inference.
The Art of Deception: Color Visual Illusions and Diffusion Models
Dec 13, 2024



Visual illusions in humans arise when interpreting out-of-distribution stimuli: if the observer is adapted to certain statistics, perception of outliers deviates from reality. Recent studies have shown that artificial neural networks (ANNs) can also be deceived by visual illusions. This revelation raises profound questions about the nature of visual information. Why are two independent systems, both human brains and ANNs, susceptible to the same illusions? Should any ANN be capable of perceiving visual illusions? Are these perceptions a feature or a flaw? In this work, we study how visual illusions are encoded in diffusion models. Remarkably, we show that they present human-like brightness/color shifts in their latent space. We use this fact to demonstrate that diffusion models can predict visual illusions. Furthermore, we also show how to generate new unseen visual illusions in realistic images using text-to-image diffusion models. We validate this ability through psychophysical experiments that show how our model-generated illusions also fool humans.
Single-View Graph Contrastive Learning with Soft Neighborhood Awareness
Dec 12, 2024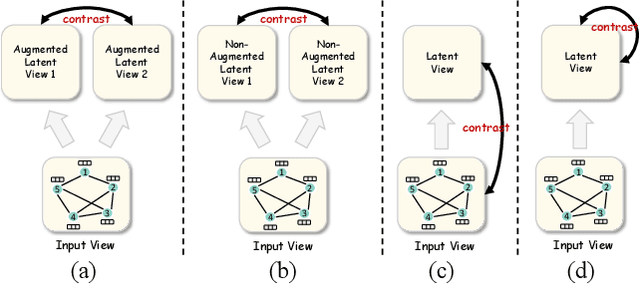



Most graph contrastive learning (GCL) methods heavily rely on cross-view contrast, thus facing several concomitant challenges, such as the complexity of designing effective augmentations, the potential for information loss between views, and increased computational costs. To mitigate reliance on cross-view contrasts, we propose \ttt{SIGNA}, a novel single-view graph contrastive learning framework. Regarding the inconsistency between structural connection and semantic similarity of neighborhoods, we resort to soft neighborhood awareness for GCL. Specifically, we leverage dropout to obtain structurally-related yet randomly-noised embedding pairs for neighbors, which serve as potential positive samples. At each epoch, the role of partial neighbors is switched from positive to negative, leading to probabilistic neighborhood contrastive learning effect. Furthermore, we propose a normalized Jensen-Shannon divergence estimator for a better effect of contrastive learning. Surprisingly, experiments on diverse node-level tasks demonstrate that our simple single-view GCL framework consistently outperforms existing methods by margins of up to 21.74% (PPI). In particular, with soft neighborhood awareness, SIGNA can adopt MLPs instead of complicated GCNs as the encoder to generate representations in transductive learning tasks, thus speeding up its inference process by 109 times to 331 times. The source code is available at https://github.com/sunisfighting/SIGNA.
Multi-Modal Environmental Sensing Based Path Loss Prediction for V2I Communications
Dec 10, 2024The stability and reliability of wireless data transmission in vehicular networks face significant challenges due to the high dynamics of path loss caused by the complexity of rapidly changing environments. This paper proposes a multi-modal environmental sensing-based path loss prediction architecture (MES-PLA) for V2I communications. First, we establish a multi-modal environment data and channel joint acquisition platform to generate a spatio-temporally synchronized and aligned dataset of environmental and channel data. Then we designed a multi-modal feature extraction and fusion network (MFEF-Net) for multi-modal environmental sensing data. MFEF-Net extracts features from RGB images, point cloud data, and GPS information, and integrates them with an attention mechanism to effectively leverage the strengths of each modality. The simulation results demonstrate that the Root Mean Square Error (RMSE) of MES-PLA is 2.20 dB, indicating a notable improvement in prediction accuracy compared to single-modal sensing data input. Moreover, MES-PLA exhibits enhanced stability under varying illumination conditions compared to single-modal methods.
A multimodal ensemble approach for clear cell renal cell carcinoma treatment outcome prediction
Dec 10, 2024



Purpose: A reliable cancer prognosis model for clear cell renal cell carcinoma (ccRCC) can enhance personalized treatment. We developed a multi-modal ensemble model (MMEM) that integrates pretreatment clinical data, multi-omics data, and histopathology whole slide image (WSI) data to predict overall survival (OS) and disease-free survival (DFS) for ccRCC patients. Methods: We analyzed 226 patients from The Cancer Genome Atlas Kidney Renal Clear Cell Carcinoma (TCGA-KIRC) dataset, which includes OS, DFS follow-up data, and five data modalities: clinical data, WSIs, and three multi-omics datasets (mRNA, miRNA, and DNA methylation). Separate survival models were built for OS and DFS. Cox-proportional hazards (CPH) model with forward feature selection is used for clinical and multi-omics data. Features from WSIs were extracted using ResNet and three general-purpose foundation models. A deep learning-based CPH model predicted survival using encoded WSI features. Risk scores from all models were combined based on training performance. Results: Performance was assessed using concordance index (C-index) and AUROC. The clinical feature-based CPH model received the highest weight for both OS and DFS tasks. Among WSI-based models, the general-purpose foundation model (UNI) achieved the best performance. The final MMEM model surpassed single-modality models, achieving C-indices of 0.820 (OS) and 0.833 (DFS), and AUROC values of 0.831 (3-year patient death) and 0.862 (cancer recurrence). Using predicted risk medians to stratify high- and low-risk groups, log-rank tests showed improved performance in both OS and DFS compared to single-modality models. Conclusion: MMEM is the first multi-modal model for ccRCC patients, integrating five data modalities. It outperformed single-modality models in prognostic ability and has the potential to assist in ccRCC patient management if independently validated.
A Stitch in Time Saves Nine: Small VLM is a Precise Guidance for Accelerating Large VLMs
Dec 05, 2024



Vision-language models (VLMs) have shown remarkable success across various multi-modal tasks, yet large VLMs encounter significant efficiency challenges due to processing numerous visual tokens. A promising approach to accelerating large VLM inference is using partial information, such as attention maps from specific layers, to assess token importance and prune less essential tokens. However, our study reveals three key insights: (i) Partial attention information is insufficient for accurately identifying critical visual tokens, resulting in suboptimal performance, especially at low token retention ratios; (ii) Global attention information, such as the attention map aggregated across all layers, more effectively preserves essential tokens and maintains comparable performance under aggressive pruning. However, the attention maps from all layers requires a full inference pass, which increases computational load and is therefore impractical in existing methods; and (iii) The global attention map aggregated from a small VLM closely resembles that of a large VLM, suggesting an efficient alternative. Based on these findings, we introduce a \textbf{training-free} method, \underline{\textbf{S}}mall VLM \underline{\textbf{G}}uidance for accelerating \underline{\textbf{L}}arge VLMs (\textbf{SGL}). Specifically, we employ the attention map aggregated from a small VLM to guide visual token pruning in a large VLM. Additionally, an early exiting mechanism is developed to fully use the small VLM's predictions, dynamically invoking the larger VLM only when necessary, yielding a superior trade-off between accuracy and computation. Extensive evaluations across 11 benchmarks demonstrate the effectiveness and generalizability of SGL, achieving up to 91\% pruning ratio for visual tokens while retaining competitive performance.
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Dec 03, 2024



Recent advancements in video generation have significantly impacted daily life for both individuals and industries. However, the leading video generation models remain closed-source, resulting in a notable performance gap between industry capabilities and those available to the public. In this report, we introduce HunyuanVideo, an innovative open-source video foundation model that demonstrates performance in video generation comparable to, or even surpassing, that of leading closed-source models. HunyuanVideo encompasses a comprehensive framework that integrates several key elements, including data curation, advanced architectural design, progressive model scaling and training, and an efficient infrastructure tailored for large-scale model training and inference. As a result, we successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models. We conducted extensive experiments and implemented a series of targeted designs to ensure high visual quality, motion dynamics, text-video alignment, and advanced filming techniques. According to evaluations by professionals, HunyuanVideo outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models. By releasing the code for the foundation model and its applications, we aim to bridge the gap between closed-source and open-source communities. This initiative will empower individuals within the community to experiment with their ideas, fostering a more dynamic and vibrant video generation ecosystem. The code is publicly available at https://github.com/Tencent/HunyuanVideo.
Deep Sparse Latent Feature Models for Knowledge Graph Completion
Nov 24, 2024



Recent progress in knowledge graph completion (KGC) has focused on text-based approaches to address the challenges of large-scale knowledge graphs (KGs). Despite their achievements, these methods often overlook the intricate interconnections between entities, a key aspect of the underlying topological structure of a KG. Stochastic blockmodels (SBMs), particularly the latent feature relational model (LFRM), offer robust probabilistic frameworks that can dynamically capture latent community structures and enhance link prediction. In this paper, we introduce a novel framework of sparse latent feature models for KGC, optimized through a deep variational autoencoder (VAE). Our approach not only effectively completes missing triples but also provides clear interpretability of the latent structures, leveraging textual information. Comprehensive experiments on the WN18RR, FB15k-237, and Wikidata5M datasets show that our method significantly improves performance by revealing latent communities and producing interpretable representations.