 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroupToM-Bench: Benchmarking Group Theory of Mind and Nonlinear Social Emergence in MLLMs
Jun 02, 2026True general intelligence requires not only a model of the physical world but also a social world model: the capacity to infer how individual mental states interact and crystallize into group-level outcomes. Despite notable progress in individual-level Theory of Mind (ToM) reasoning, existing multimodal large language models fail at this broader task. Collective behavior emerges non-linearly from social tensions, conformity dynamics, and structural constraints, meaning it cannot be recovered by merely summing individual intentions. We present GroupToM-Bench, the first multimodal benchmark for group-level ToM, built around a causal chain spanning micro-level BDI states (belief, desire, intention), meso-level group tension and structural constraints, and macro-level outcome prediction and mechanistic attribution. To probe this full arc, we develop a seven-level cognitive audit framework. Experiments reveal a gap between current models and human baselines, highlighting a failure to process social structures and non-linear collective dynamics.
Kwai Summary Attention Technical Report
Apr 27, 2026Long-context ability, has become one of the most important iteration direction of next-generation Large Language Models, particularly in semantic understanding/reasoning, code agentic intelligence and recommendation system. However, the standard softmax attention exhibits quadratic time complexity with respect to sequence length. As the sequence length increases, this incurs substantial overhead in long-context settings, leading the training and inference costs of extremely long sequences deteriorate rapidly. Existing solutions mitigate this issue through two technique routings: i) Reducing the KV cache per layer, such as from the head-level compression GQA, and the embedding dimension-level compression MLA, but the KV cache remains linearly dependent on the sequence length at a 1:1 ratio. ii) Interleaving with KV Cache friendly architecture, such as local attention SWA, linear kernel GDN, but often involve trade-offs among KV Cache and long-context modeling effectiveness. Besides the two technique routings, we argue that there exists an intermediate path not well explored: {Maintaining a linear relationship between the KV cache and sequence length, but performing semantic-level compression through a specific ratio $k$}. This $O(n/k)$ path does not pursue a ``minimum KV cache'', but rather trades acceptable memory costs for complete, referential, and interpretable retention of long distant dependency. Motivated by this, we propose Kwai Summary Attention (KSA), a novel attention mechanism that reduces sequence modeling cost by compressing historical contexts into learnable summary tokens.
AgentGate: A Lightweight Structured Routing Engine for the Internet of Agents
Apr 08, 2026The rapid development of AI agent systems is leading to an emerging Internet of Agents, where specialized agents operate across local devices, edge nodes, private services, and cloud platforms. Although recent efforts have improved agent naming, discovery, and interaction, efficient request dispatch remains an open systems problem under latency, privacy, and cost constraints. In this paper, we present AgentGate, a lightweight structured routing engine for candidate-aware agent dispatch. Instead of treating routing as unrestricted text generation, AgentGate formulates it as a constrained decision problem and decomposes it into two stages: action decision and structural grounding. The first stage determines whether a query should trigger single-agent invocation, multi-agent planning, direct response, or safe escalation, while the second stage instantiates the selected action into executable outputs such as target agents, structured arguments, or multi-step plans. To adapt compact models to this setting, we further develop a routing-oriented fine-tuning scheme with candidate-aware supervision and hard negative examples. Experiments on a curated routing benchmark with several 3B--7B open-weight models show that compact models can provide competitive routing performance in constrained settings, and that model differences are mainly reflected in action prediction, candidate selection, and structured grounding quality. These results indicate that structured routing is a feasible design point for efficient and privacy-aware agent systems, especially when routing decisions must be made under resource-constrained deployment conditions.
AgentDNS: A Root Domain Naming System for LLM Agents
May 28, 2025The rapid evolution of Large Language Model (LLM) agents has highlighted critical challenges in cross-vendor service discovery, interoperability, and communication. Existing protocols like model context protocol and agent-to-agent protocol have made significant strides in standardizing interoperability between agents and tools, as well as communication among multi-agents. However, there remains a lack of standardized protocols and solutions for service discovery across different agent and tool vendors. In this paper, we propose AgentDNS, a root domain naming and service discovery system designed to enable LLM agents to autonomously discover, resolve, and securely invoke third-party agent and tool services across organizational and technological boundaries. Inspired by the principles of the traditional DNS, AgentDNS introduces a structured mechanism for service registration, semantic service discovery, secure invocation, and unified billing. We detail the architecture, core functionalities, and use cases of AgentDNS, demonstrating its potential to streamline multi-agent collaboration in real-world scenarios. The source code will be published on https://github.com/agentdns.
REPA Works Until It Doesn't: Early-Stopped, Holistic Alignment Supercharges Diffusion Training
May 22, 2025



Diffusion Transformers (DiTs) deliver state-of-the-art image quality, yet their training remains notoriously slow. A recent remedy -- representation alignment (REPA) that matches DiT hidden features to those of a non-generative teacher (e.g. DINO) -- dramatically accelerates the early epochs but plateaus or even degrades performance later. We trace this failure to a capacity mismatch: once the generative student begins modelling the joint data distribution, the teacher's lower-dimensional embeddings and attention patterns become a straitjacket rather than a guide. We then introduce HASTE (Holistic Alignment with Stage-wise Termination for Efficient training), a two-phase schedule that keeps the help and drops the hindrance. Phase I applies a holistic alignment loss that simultaneously distills attention maps (relational priors) and feature projections (semantic anchors) from the teacher into mid-level layers of the DiT, yielding rapid convergence. Phase II then performs one-shot termination that deactivates the alignment loss, once a simple trigger such as a fixed iteration is hit, freeing the DiT to focus on denoising and exploit its generative capacity. HASTE speeds up training of diverse DiTs without architecture changes. On ImageNet 256X256, it reaches the vanilla SiT-XL/2 baseline FID in 50 epochs and matches REPA's best FID in 500 epochs, amounting to a 28X reduction in optimization steps. HASTE also improves text-to-image DiTs on MS-COCO, demonstrating to be a simple yet principled recipe for efficient diffusion training across various tasks. Our code is available at https://github.com/NUS-HPC-AI-Lab/HASTE .
DD-Ranking: Rethinking the Evaluation of Dataset Distillation
May 19, 2025



In recent years, dataset distillation has provided a reliable solution for data compression, where models trained on the resulting smaller synthetic datasets achieve performance comparable to those trained on the original datasets. To further improve the performance of synthetic datasets, various training pipelines and optimization objectives have been proposed, greatly advancing the field of dataset distillation. Recent decoupled dataset distillation methods introduce soft labels and stronger data augmentation during the post-evaluation phase and scale dataset distillation up to larger datasets (e.g., ImageNet-1K). However, this raises a question: Is accuracy still a reliable metric to fairly evaluate dataset distillation methods? Our empirical findings suggest that the performance improvements of these methods often stem from additional techniques rather than the inherent quality of the images themselves, with even randomly sampled images achieving superior results. Such misaligned evaluation settings severely hinder the development of DD. Therefore, we propose DD-Ranking, a unified evaluation framework, along with new general evaluation metrics to uncover the true performance improvements achieved by different methods. By refocusing on the actual information enhancement of distilled datasets, DD-Ranking provides a more comprehensive and fair evaluation standard for future research advancements.
Dynamic Vision Mamba
Apr 07, 2025



Mamba-based vision models have gained extensive attention as a result of being computationally more efficient than attention-based models. However, spatial redundancy still exists in these models, represented by token and block redundancy. For token redundancy, we analytically find that early token pruning methods will result in inconsistency between training and inference or introduce extra computation for inference. Therefore, we customize token pruning to fit the Mamba structure by rearranging the pruned sequence before feeding it into the next Mamba block. For block redundancy, we allow each image to select SSM blocks dynamically based on an empirical observation that the inference speed of Mamba-based vision models is largely affected by the number of SSM blocks. Our proposed method, Dynamic Vision Mamba (DyVM), effectively reduces FLOPs with minor performance drops. We achieve a reduction of 35.2\% FLOPs with only a loss of accuracy of 1.7\% on Vim-S. It also generalizes well across different Mamba vision model architectures and different vision tasks. Our code will be made public.
Faster Vision Mamba is Rebuilt in Minutes via Merged Token Re-training
Dec 17, 2024



Vision Mamba (e.g., Vim) has successfully been integrated into computer vision, and token reduction has yielded promising outcomes in Vision Transformers (ViTs). However, token reduction performs less effectively on Vision Mamba compared to ViTs. Pruning informative tokens in Mamba leads to a high loss of key knowledge and bad performance. This makes it not a good solution for enhancing efficiency in Mamba. Token merging, which preserves more token information than pruning, has demonstrated commendable performance in ViTs. Nevertheless, vanilla merging performance decreases as the reduction ratio increases either, failing to maintain the key knowledge in Mamba. Re-training the token-reduced model enhances the performance of Mamba, by effectively rebuilding the key knowledge. Empirically, pruned Vims only drop up to 0.9% accuracy on ImageNet-1K, recovered by our proposed framework R-MeeTo in our main evaluation. We show how simple and effective the fast recovery can be achieved at minute-level, in particular, a 35.9% accuracy spike over 3 epochs of training on Vim-Ti. Moreover, Vim-Ti/S/B are re-trained within 5/7/17 minutes, and Vim-S only drop 1.3% with 1.2x (up to 1.5x) speed up in inference.
CREAM: Consistency Regularized Self-Rewarding Language Models
Oct 17, 2024



Recent self-rewarding large language models (LLM) have successfully applied LLM-as-a-Judge to iteratively improve the alignment performance without the need of human annotations for preference data. These methods commonly utilize the same LLM to act as both the policy model (which generates responses) and the reward model (which scores and ranks those responses). The ranked responses are then used as preference pairs to train the LLM via direct alignment technologies (e.g. DPO). However, it is noteworthy that throughout this process, there is no guarantee of accuracy in the rewarding and ranking, which is critical for ensuring accurate rewards and high-quality preference data. Empirical results from relatively small LLMs (e.g., 7B parameters) also indicate that improvements from self-rewarding may diminish after several iterations in certain situations, which we hypothesize is due to accumulated bias in the reward system. This bias can lead to unreliable preference data for training the LLM. To address this issue, we first formulate and analyze the generalized iterative preference fine-tuning framework for self-rewarding language model. We then introduce the regularization to this generalized framework to mitigate the overconfident preference labeling in the self-rewarding process. Based on this theoretical insight, we propose a Consistency Regularized sElf-rewarding lAnguage Model (CREAM) that leverages the rewarding consistency across different iterations to regularize the self-rewarding training, helping the model to learn from more reliable preference data. With this explicit regularization, our empirical results demonstrate the superiority of CREAM in improving both reward consistency and alignment performance. The code is publicly available at https://github.com/Raibows/CREAM.
Tree Energy Loss: Towards Sparsely Annotated Semantic Segmentation
Mar 22, 2022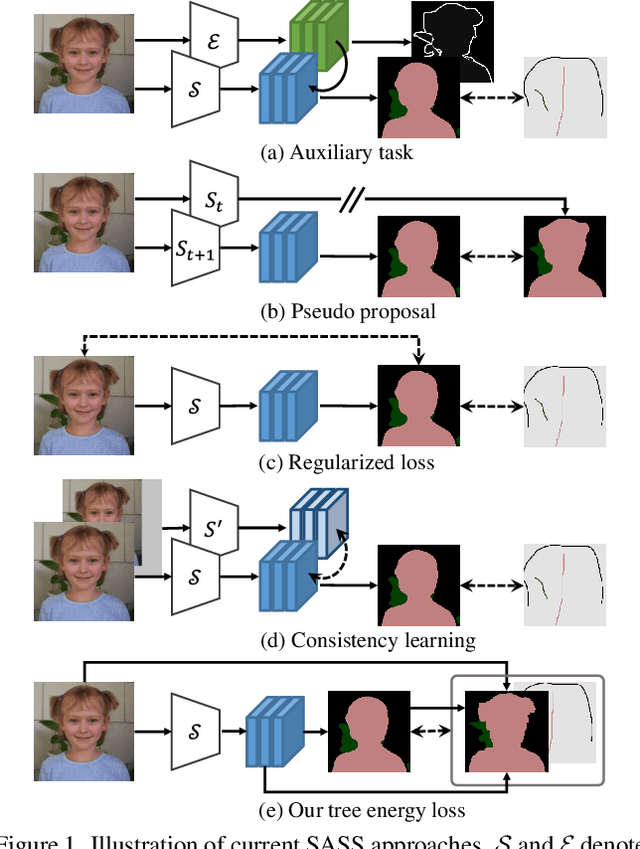
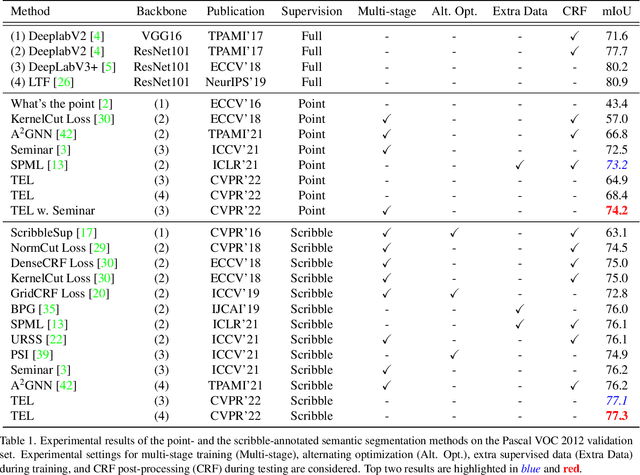

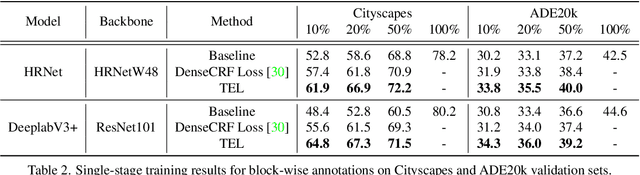
Sparsely annotated semantic segmentation (SASS) aims to train a segmentation network with coarse-grained (i.e., point-, scribble-, and block-wise) supervisions, where only a small proportion of pixels are labeled in each image. In this paper, we propose a novel tree energy loss for SASS by providing semantic guidance for unlabeled pixels. The tree energy loss represents images as minimum spanning trees to model both low-level and high-level pair-wise affinities. By sequentially applying these affinities to the network prediction, soft pseudo labels for unlabeled pixels are generated in a coarse-to-fine manner, achieving dynamic online self-training. The tree energy loss is effective and easy to be incorporated into existing frameworks by combining it with a traditional segmentation loss. Compared with previous SASS methods, our method requires no multistage training strategies, alternating optimization procedures, additional supervised data, or time-consuming post-processing while outperforming them in all SASS settings. Code is available at https://github.com/megvii-research/TreeEnergyLoss.