 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning CLIP Guided Visual-Text Fusion Transformer for Video-based Pedestrian Attribute Recognition
Apr 20, 2023Existing pedestrian attribute recognition (PAR) algorithms are mainly developed based on a static image. However, the performance is not reliable for images with challenging factors, such as heavy occlusion, motion blur, etc. In this work, we propose to understand human attributes using video frames that can make full use of temporal information. Specifically, we formulate the video-based PAR as a vision-language fusion problem and adopt pre-trained big models CLIP to extract the feature embeddings of given video frames. To better utilize the semantic information, we take the attribute list as another input and transform the attribute words/phrase into the corresponding sentence via split, expand, and prompt. Then, the text encoder of CLIP is utilized for language embedding. The averaged visual tokens and text tokens are concatenated and fed into a fusion Transformer for multi-modal interactive learning. The enhanced tokens will be fed into a classification head for pedestrian attribute prediction. Extensive experiments on a large-scale video-based PAR dataset fully validated the effectiveness of our proposed framework.
Learning Sample Difficulty from Pre-trained Models for Reliable Prediction
Apr 20, 2023Large-scale pre-trained models have achieved remarkable success in a variety of scenarios and applications, but how to leverage them to improve the prediction reliability of downstream models is undesirably under-explored. Moreover, modern neural networks have been found to be poorly calibrated and make overconfident predictions regardless of inherent sample difficulty and data uncertainty. To address this issue, we propose to utilize large-scale pre-trained models to guide downstream model training with sample difficulty-aware entropy regularization. Pre-trained models that have been exposed to large-scale datasets and do not overfit the downstream training classes enable us to measure each training sample difficulty via feature-space Gaussian modeling and relative Mahalanobis distance computation. Importantly, by adaptively penalizing overconfident prediction based on the sample's difficulty, we simultaneously improve accuracy and uncertainty calibration on various challenging benchmarks, consistently surpassing competitive baselines for reliable prediction.
PREIM3D: 3D Consistent Precise Image Attribute Editing from a Single Image
Apr 20, 2023



We study the 3D-aware image attribute editing problem in this paper, which has wide applications in practice. Recent methods solved the problem by training a shared encoder to map images into a 3D generator's latent space or by per-image latent code optimization and then edited images in the latent space. Despite their promising results near the input view, they still suffer from the 3D inconsistency of produced images at large camera poses and imprecise image attribute editing, like affecting unspecified attributes during editing. For more efficient image inversion, we train a shared encoder for all images. To alleviate 3D inconsistency at large camera poses, we propose two novel methods, an alternating training scheme and a multi-view identity loss, to maintain 3D consistency and subject identity. As for imprecise image editing, we attribute the problem to the gap between the latent space of real images and that of generated images. We compare the latent space and inversion manifold of GAN models and demonstrate that editing in the inversion manifold can achieve better results in both quantitative and qualitative evaluations. Extensive experiments show that our method produces more 3D consistent images and achieves more precise image editing than previous work. Source code and pretrained models can be found on our project page: https://mybabyyh.github.io/Preim3D/
A Closer Look at Parameter-Efficient Tuning in Diffusion Models
Apr 12, 2023



Large-scale diffusion models like Stable Diffusion are powerful and find various real-world applications while customizing such models by fine-tuning is both memory and time inefficient. Motivated by the recent progress in natural language processing, we investigate parameter-efficient tuning in large diffusion models by inserting small learnable modules (termed adapters). In particular, we decompose the design space of adapters into orthogonal factors -- the input position, the output position as well as the function form, and perform Analysis of Variance (ANOVA), a classical statistical approach for analyzing the correlation between discrete (design options) and continuous variables (evaluation metrics). Our analysis suggests that the input position of adapters is the critical factor influencing the performance of downstream tasks. Then, we carefully study the choice of the input position, and we find that putting the input position after the cross-attention block can lead to the best performance, validated by additional visualization analyses. Finally, we provide a recipe for parameter-efficient tuning in diffusion models, which is comparable if not superior to the fully fine-tuned baseline (e.g., DreamBooth) with only 0.75 \% extra parameters, across various customized tasks.
Detection Transformer with Stable Matching
Apr 10, 2023



This paper is concerned with the matching stability problem across different decoder layers in DEtection TRansformers (DETR). We point out that the unstable matching in DETR is caused by a multi-optimization path problem, which is highlighted by the one-to-one matching design in DETR. To address this problem, we show that the most important design is to use and only use positional metrics (like IOU) to supervise classification scores of positive examples. Under the principle, we propose two simple yet effective modifications by integrating positional metrics to DETR's classification loss and matching cost, named position-supervised loss and position-modulated cost. We verify our methods on several DETR variants. Our methods show consistent improvements over baselines. By integrating our methods with DINO, we achieve 50.4 and 51.5 AP on the COCO detection benchmark using ResNet-50 backbones under 12 epochs and 24 epochs training settings, achieving a new record under the same setting. We achieve 63.8 AP on COCO detection test-dev with a Swin-Large backbone. Our code will be made available at https://github.com/IDEA-Research/Stable-DINO.
Towards Effective Adversarial Textured 3D Meshes on Physical Face Recognition
Mar 28, 2023



Face recognition is a prevailing authentication solution in numerous biometric applications. Physical adversarial attacks, as an important surrogate, can identify the weaknesses of face recognition systems and evaluate their robustness before deployed. However, most existing physical attacks are either detectable readily or ineffective against commercial recognition systems. The goal of this work is to develop a more reliable technique that can carry out an end-to-end evaluation of adversarial robustness for commercial systems. It requires that this technique can simultaneously deceive black-box recognition models and evade defensive mechanisms. To fulfill this, we design adversarial textured 3D meshes (AT3D) with an elaborate topology on a human face, which can be 3D-printed and pasted on the attacker's face to evade the defenses. However, the mesh-based optimization regime calculates gradients in high-dimensional mesh space, and can be trapped into local optima with unsatisfactory transferability. To deviate from the mesh-based space, we propose to perturb the low-dimensional coefficient space based on 3D Morphable Model, which significantly improves black-box transferability meanwhile enjoying faster search efficiency and better visual quality. Extensive experiments in digital and physical scenarios show that our method effectively explores the security vulnerabilities of multiple popular commercial services, including three recognition APIs, four anti-spoofing APIs, two prevailing mobile phones and two automated access control systems.
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Mar 20, 2023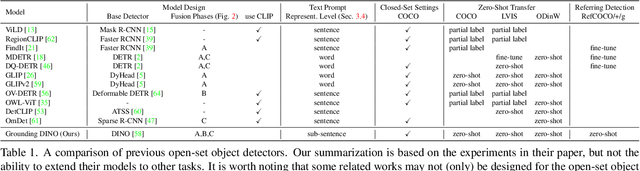
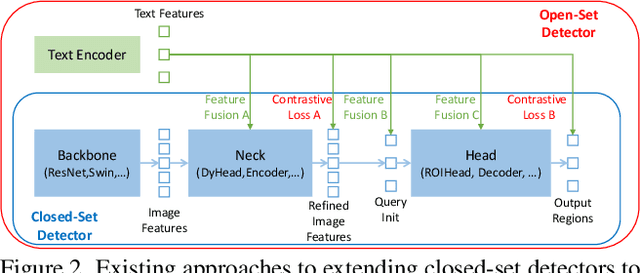
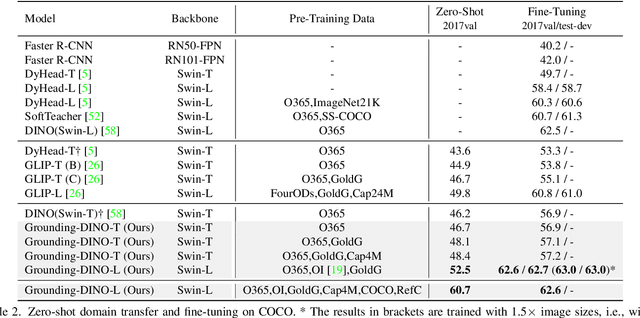
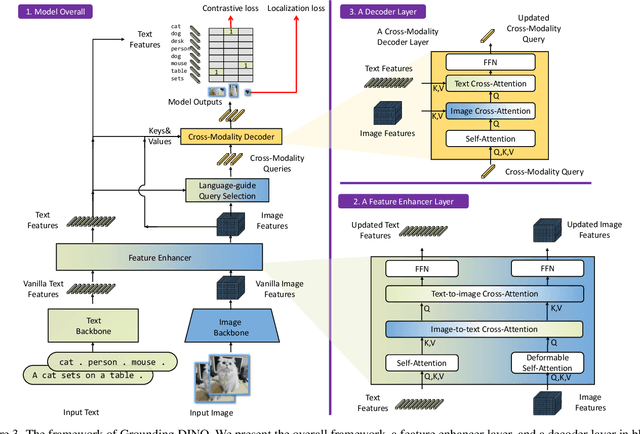
In this paper, we present an open-set object detector, called Grounding DINO, by marrying Transformer-based detector DINO with grounded pre-training, which can detect arbitrary objects with human inputs such as category names or referring expressions. The key solution of open-set object detection is introducing language to a closed-set detector for open-set concept generalization. To effectively fuse language and vision modalities, we conceptually divide a closed-set detector into three phases and propose a tight fusion solution, which includes a feature enhancer, a language-guided query selection, and a cross-modality decoder for cross-modality fusion. While previous works mainly evaluate open-set object detection on novel categories, we propose to also perform evaluations on referring expression comprehension for objects specified with attributes. Grounding DINO performs remarkably well on all three settings, including benchmarks on COCO, LVIS, ODinW, and RefCOCO/+/g. Grounding DINO achieves a $52.5$ AP on the COCO detection zero-shot transfer benchmark, i.e., without any training data from COCO. It sets a new record on the ODinW zero-shot benchmark with a mean $26.1$ AP. Code will be available at \url{https://github.com/IDEA-Research/GroundingDINO}.
Benchmarking Robustness of 3D Object Detection to Common Corruptions in Autonomous Driving
Mar 20, 20233D object detection is an important task in autonomous driving to perceive the surroundings. Despite the excellent performance, the existing 3D detectors lack the robustness to real-world corruptions caused by adverse weathers, sensor noises, etc., provoking concerns about the safety and reliability of autonomous driving systems. To comprehensively and rigorously benchmark the corruption robustness of 3D detectors, in this paper we design 27 types of common corruptions for both LiDAR and camera inputs considering real-world driving scenarios. By synthesizing these corruptions on public datasets, we establish three corruption robustness benchmarks -- KITTI-C, nuScenes-C, and Waymo-C. Then, we conduct large-scale experiments on 24 diverse 3D object detection models to evaluate their corruption robustness. Based on the evaluation results, we draw several important findings, including: 1) motion-level corruptions are the most threatening ones that lead to significant performance drop of all models; 2) LiDAR-camera fusion models demonstrate better robustness; 3) camera-only models are extremely vulnerable to image corruptions, showing the indispensability of LiDAR point clouds. We release the benchmarks and codes at https://github.com/kkkcx/3D_Corruptions_AD. We hope that our benchmarks and findings can provide insights for future research on developing robust 3D object detection models.
Rethinking Model Ensemble in Transfer-based Adversarial Attacks
Mar 16, 2023Deep learning models are vulnerable to adversarial examples. Transfer-based adversarial attacks attract tremendous attention as they can identify the weaknesses of deep learning models in a black-box manner. An effective strategy to improve the transferability of adversarial examples is attacking an ensemble of models. However, previous works simply average the outputs of different models, lacking an in-depth analysis on how and why model ensemble can strongly improve the transferability. In this work, we rethink the ensemble in adversarial attacks and define the common weakness of model ensemble with the properties of the flatness of loss landscape and the closeness to the local optimum of each model. We empirically and theoretically show that these two properties are strongly correlated with the transferability and propose a Common Weakness Attack (CWA) to generate more transferable adversarial examples by promoting these two properties. Experimental results on both image classification and object detection tasks validate the effectiveness of our approach to improve the adversarial transferability, especially when attacking adversarially trained models.
One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale
Mar 12, 2023



This paper proposes a unified diffusion framework (dubbed UniDiffuser) to fit all distributions relevant to a set of multi-modal data in one model. Our key insight is -- learning diffusion models for marginal, conditional, and joint distributions can be unified as predicting the noise in the perturbed data, where the perturbation levels (i.e. timesteps) can be different for different modalities. Inspired by the unified view, UniDiffuser learns all distributions simultaneously with a minimal modification to the original diffusion model -- perturbs data in all modalities instead of a single modality, inputs individual timesteps in different modalities, and predicts the noise of all modalities instead of a single modality. UniDiffuser is parameterized by a transformer for diffusion models to handle input types of different modalities. Implemented on large-scale paired image-text data, UniDiffuser is able to perform image, text, text-to-image, image-to-text, and image-text pair generation by setting proper timesteps without additional overhead. In particular, UniDiffuser is able to produce perceptually realistic samples in all tasks and its quantitative results (e.g., the FID and CLIP score) are not only superior to existing general-purpose models but also comparable to the bespoken models (e.g., Stable Diffusion and DALL-E 2) in representative tasks (e.g., text-to-image generation).