 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptCLIP: Adapting CLIP for Universal Visual Anomaly Detection
May 15, 2025Universal visual anomaly detection aims to identify anomalies from novel or unseen vision domains without additional fine-tuning, which is critical in open scenarios. Recent studies have demonstrated that pre-trained vision-language models like CLIP exhibit strong generalization with just zero or a few normal images. However, existing methods struggle with designing prompt templates, complex token interactions, or requiring additional fine-tuning, resulting in limited flexibility. In this work, we present a simple yet effective method called AdaptCLIP based on two key insights. First, adaptive visual and textual representations should be learned alternately rather than jointly. Second, comparative learning between query and normal image prompt should incorporate both contextual and aligned residual features, rather than relying solely on residual features. AdaptCLIP treats CLIP models as a foundational service, adding only three simple adapters, visual adapter, textual adapter, and prompt-query adapter, at its input or output ends. AdaptCLIP supports zero-/few-shot generalization across domains and possesses a training-free manner on target domains once trained on a base dataset. AdaptCLIP achieves state-of-the-art performance on 12 anomaly detection benchmarks from industrial and medical domains, significantly outperforming existing competitive methods. We will make the code and model of AdaptCLIP available at https://github.com/gaobb/AdaptCLIP.
Few-Shot Anomaly-Driven Generation for Anomaly Classification and Segmentation
May 14, 2025Anomaly detection is a practical and challenging task due to the scarcity of anomaly samples in industrial inspection. Some existing anomaly detection methods address this issue by synthesizing anomalies with noise or external data. However, there is always a large semantic gap between synthetic and real-world anomalies, resulting in weak performance in anomaly detection. To solve the problem, we propose a few-shot Anomaly-driven Generation (AnoGen) method, which guides the diffusion model to generate realistic and diverse anomalies with only a few real anomalies, thereby benefiting training anomaly detection models. Specifically, our work is divided into three stages. In the first stage, we learn the anomaly distribution based on a few given real anomalies and inject the learned knowledge into an embedding. In the second stage, we use the embedding and given bounding boxes to guide the diffusion model to generate realistic and diverse anomalies on specific objects (or textures). In the final stage, we propose a weakly-supervised anomaly detection method to train a more powerful model with generated anomalies. Our method builds upon DRAEM and DesTSeg as the foundation model and conducts experiments on the commonly used industrial anomaly detection dataset, MVTec. The experiments demonstrate that our generated anomalies effectively improve the model performance of both anomaly classification and segmentation tasks simultaneously, \eg, DRAEM and DseTSeg achieved a 5.8\% and 1.5\% improvement in AU-PR metric on segmentation task, respectively. The code and generated anomalous data are available at https://github.com/gaobb/AnoGen.
TSTMotion: Training-free Scene-aware Text-to-motion Generation
May 05, 2025Text-to-motion generation has recently garnered significant research interest, primarily focusing on generating human motion sequences in blank backgrounds. However, human motions commonly occur within diverse 3D scenes, which has prompted exploration into scene-aware text-to-motion generation methods. Yet, existing scene-aware methods often rely on large-scale ground-truth motion sequences in diverse 3D scenes, which poses practical challenges due to the expensive cost. To mitigate this challenge, we are the first to propose a \textbf{T}raining-free \textbf{S}cene-aware \textbf{T}ext-to-\textbf{Motion} framework, dubbed as \textbf{TSTMotion}, that efficiently empowers pre-trained blank-background motion generators with the scene-aware capability. Specifically, conditioned on the given 3D scene and text description, we adopt foundation models together to reason, predict and validate a scene-aware motion guidance. Then, the motion guidance is incorporated into the blank-background motion generators with two modifications, resulting in scene-aware text-driven motion sequences. Extensive experiments demonstrate the efficacy and generalizability of our proposed framework. We release our code in \href{https://tstmotion.github.io/}{Project Page}.
Perturbation-efficient Zeroth-order Optimization for Hardware-friendly On-device Training
Apr 28, 2025
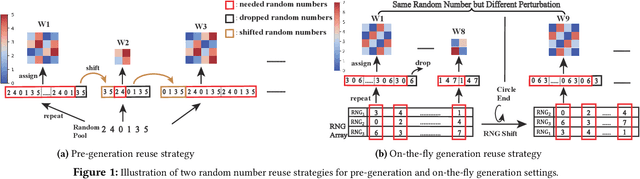


Zeroth-order (ZO) optimization is an emerging deep neural network (DNN) training paradigm that offers computational simplicity and memory savings. However, this seemingly promising approach faces a significant and long-ignored challenge. ZO requires generating a substantial number of Gaussian random numbers, which poses significant difficulties and even makes it infeasible for hardware platforms, such as FPGAs and ASICs. In this paper, we identify this critical issue, which arises from the mismatch between algorithm and hardware designers. To address this issue, we proposed PeZO, a perturbation-efficient ZO framework. Specifically, we design random number reuse strategies to significantly reduce the demand for random number generation and introduce a hardware-friendly adaptive scaling method to replace the costly Gaussian distribution with a uniform distribution. Our experiments show that PeZO reduces the required LUTs and FFs for random number generation by 48.6\% and 12.7\%, and saves at maximum 86\% power consumption, all without compromising training performance, making ZO optimization feasible for on-device training. To the best of our knowledge, we are the first to explore the potential of on-device ZO optimization, providing valuable insights for future research.
Contour Field based Elliptical Shape Prior for the Segment Anything Model
Apr 17, 2025



The elliptical shape prior information plays a vital role in improving the accuracy of image segmentation for specific tasks in medical and natural images. Existing deep learning-based segmentation methods, including the Segment Anything Model (SAM), often struggle to produce segmentation results with elliptical shapes efficiently. This paper proposes a new approach to integrate the prior of elliptical shapes into the deep learning-based SAM image segmentation techniques using variational methods. The proposed method establishes a parameterized elliptical contour field, which constrains the segmentation results to align with predefined elliptical contours. Utilizing the dual algorithm, the model seamlessly integrates image features with elliptical priors and spatial regularization priors, thereby greatly enhancing segmentation accuracy. By decomposing SAM into four mathematical sub-problems, we integrate the variational ellipse prior to design a new SAM network structure, ensuring that the segmentation output of SAM consists of elliptical regions. Experimental results on some specific image datasets demonstrate an improvement over the original SAM.
The Tenth NTIRE 2025 Image Denoising Challenge Report
Apr 16, 2025



This paper presents an overview of the NTIRE 2025 Image Denoising Challenge ({\sigma} = 50), highlighting the proposed methodologies and corresponding results. The primary objective is to develop a network architecture capable of achieving high-quality denoising performance, quantitatively evaluated using PSNR, without constraints on computational complexity or model size. The task assumes independent additive white Gaussian noise (AWGN) with a fixed noise level of 50. A total of 290 participants registered for the challenge, with 20 teams successfully submitting valid results, providing insights into the current state-of-the-art in image denoising.
MediSee: Reasoning-based Pixel-level Perception in Medical Images
Apr 15, 2025Despite remarkable advancements in pixel-level medical image perception, existing methods are either limited to specific tasks or heavily rely on accurate bounding boxes or text labels as input prompts. However, the medical knowledge required for input is a huge obstacle for general public, which greatly reduces the universality of these methods. Compared with these domain-specialized auxiliary information, general users tend to rely on oral queries that require logical reasoning. In this paper, we introduce a novel medical vision task: Medical Reasoning Segmentation and Detection (MedSD), which aims to comprehend implicit queries about medical images and generate the corresponding segmentation mask and bounding box for the target object. To accomplish this task, we first introduce a Multi-perspective, Logic-driven Medical Reasoning Segmentation and Detection (MLMR-SD) dataset, which encompasses a substantial collection of medical entity targets along with their corresponding reasoning. Furthermore, we propose MediSee, an effective baseline model designed for medical reasoning segmentation and detection. The experimental results indicate that the proposed method can effectively address MedSD with implicit colloquial queries and outperform traditional medical referring segmentation methods.
Contour Flow Constraint: Preserving Global Shape Similarity for Deep Learning based Image Segmentation
Apr 13, 2025For effective image segmentation, it is crucial to employ constraints informed by prior knowledge about the characteristics of the areas to be segmented to yield favorable segmentation outcomes. However, the existing methods have primarily focused on priors of specific properties or shapes, lacking consideration of the general global shape similarity from a Contour Flow (CF) perspective. Furthermore, naturally integrating this contour flow prior image segmentation model into the activation functions of deep convolutional networks through mathematical methods is currently unexplored. In this paper, we establish a concept of global shape similarity based on the premise that two shapes exhibit comparable contours. Furthermore, we mathematically derive a contour flow constraint that ensures the preservation of global shape similarity. We propose two implementations to integrate the constraint with deep neural networks. Firstly, the constraint is converted to a shape loss, which can be seamlessly incorporated into the training phase for any learning-based segmentation framework. Secondly, we add the constraint into a variational segmentation model and derive its iterative schemes for solution. The scheme is then unrolled to get the architecture of the proposed CFSSnet. Validation experiments on diverse datasets are conducted on classic benchmark deep network segmentation models. The results indicate a great improvement in segmentation accuracy and shape similarity for the proposed shape loss, showcasing the general adaptability of the proposed loss term regardless of specific network architectures. CFSSnet shows robustness in segmenting noise-contaminated images, and inherent capability to preserve global shape similarity.
Genius: A Generalizable and Purely Unsupervised Self-Training Framework For Advanced Reasoning
Apr 11, 2025



Advancing LLM reasoning skills has captivated wide interest. However, current post-training techniques rely heavily on supervisory signals, such as outcome supervision or auxiliary reward models, which face the problem of scalability and high annotation costs. This motivates us to enhance LLM reasoning without the need for external supervision. We introduce a generalizable and purely unsupervised self-training framework, named Genius. Without external auxiliary, Genius requires to seek the optimal response sequence in a stepwise manner and optimize the LLM. To explore the potential steps and exploit the optimal ones, Genius introduces a stepwise foresight re-sampling strategy to sample and estimate the step value by simulating future outcomes. Further, we recognize that the unsupervised setting inevitably induces the intrinsic noise and uncertainty. To provide a robust optimization, we propose an advantage-calibrated optimization (ACO) loss function to mitigate estimation inconsistencies. Combining these techniques together, Genius provides an advanced initial step towards self-improve LLM reasoning with general queries and without supervision, revolutionizing reasoning scaling laws given the vast availability of general queries. The code will be released at https://github.com/xufangzhi/Genius.
BoxSeg: Quality-Aware and Peer-Assisted Learning for Box-supervised Instance Segmentation
Apr 07, 2025Box-supervised instance segmentation methods aim to achieve instance segmentation with only box annotations. Recent methods have demonstrated the effectiveness of acquiring high-quality pseudo masks under the teacher-student framework. Building upon this foundation, we propose a BoxSeg framework involving two novel and general modules named the Quality-Aware Module (QAM) and the Peer-assisted Copy-paste (PC). The QAM obtains high-quality pseudo masks and better measures the mask quality to help reduce the effect of noisy masks, by leveraging the quality-aware multi-mask complementation mechanism. The PC imitates Peer-Assisted Learning to further improve the quality of the low-quality masks with the guidance of the obtained high-quality pseudo masks. Theoretical and experimental analyses demonstrate the proposed QAM and PC are effective. Extensive experimental results show the superiority of our BoxSeg over the state-of-the-art methods, and illustrate the QAM and PC can be applied to improve other models.