 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePalette: A Modular, Controllable, and Efficient Framework for On-demand Authorized Safety Alignment Relaxation in LLMs
May 22, 2026Current safety alignment of foundation models largely follows a \emph{one-size-fits-all} paradigm, applying the same refusal policy across users and contexts. As a result, models may refuse requests that are unsafe for general users but legitimate for authorized professionals, limiting helpfulness in specialized professional settings. Existing approaches either require costly realignment or rely on inference-time steering that suffers from imprecise control and added latency. To this end, we propose \textsc{Palette}, a modular, controllable, and efficient framework that selectively relaxes refusal behavior on authorized target domains while preserving standard safety elsewhere. Our method identifies a refusal direction via multi-objective search and internalizes it into the model through lightweight adaptation. \textsc{Palette} further supports modular composition: it learns domain-specific safety controls independently and composes them through parameter merging, enabling on-demand multi-domain authorization without retraining. Experiments across four safety benchmarks, multiple model variants, and both LLMs and VLMs show that \textsc{Palette} delivers precise safety control without sacrificing general utility, offering a practical path toward foundation models that adapt to diverse professional needs.
Q-realign: Piggybacking Realignment on Quantization for Safe and Efficient LLM Deployment
Jan 13, 2026Public large language models (LLMs) are typically safety-aligned during pretraining, yet task-specific fine-tuning required for deployment often erodes this alignment and introduces safety risks. Existing defenses either embed safety recovery into fine-tuning or rely on fine-tuning-derived priors for post-hoc correction, leaving safety recovery tightly coupled with training and incurring high computational overhead and a complex workflow. To address these challenges, we propose \texttt{Q-realign}, a post-hoc defense method based on post-training quantization, guided by an analysis of representational structure. By reframing quantization as a dual-objective procedure for compression and safety, \texttt{Q-realign} decouples safety alignment from fine-tuning and naturally piggybacks into modern deployment pipelines. Experiments across multiple models and datasets demonstrate that our method substantially reduces unsafe behaviors while preserving task performance, with significant reductions in memory usage and GPU hours. Notably, our approach can recover the safety alignment of a fine-tuned 7B LLM on a single RTX 4090 within 40 minutes. Overall, our work provides a practical, turnkey solution for safety-aware deployment.
Rethinking the Potential of Layer Freezing for Efficient DNN Training
Aug 20, 2025With the growing size of deep neural networks and datasets, the computational costs of training have significantly increased. The layer-freezing technique has recently attracted great attention as a promising method to effectively reduce the cost of network training. However, in traditional layer-freezing methods, frozen layers are still required for forward propagation to generate feature maps for unfrozen layers, limiting the reduction of computation costs. To overcome this, prior works proposed a hypothetical solution, which caches feature maps from frozen layers as a new dataset, allowing later layers to train directly on stored feature maps. While this approach appears to be straightforward, it presents several major challenges that are severely overlooked by prior literature, such as how to effectively apply augmentations to feature maps and the substantial storage overhead introduced. If these overlooked challenges are not addressed, the performance of the caching method will be severely impacted and even make it infeasible. This paper is the first to comprehensively explore these challenges and provides a systematic solution. To improve training accuracy, we propose \textit{similarity-aware channel augmentation}, which caches channels with high augmentation sensitivity with a minimum additional storage cost. To mitigate storage overhead, we incorporate lossy data compression into layer freezing and design a \textit{progressive compression} strategy, which increases compression rates as more layers are frozen, effectively reducing storage costs. Finally, our solution achieves significant reductions in training cost while maintaining model accuracy, with a minor time overhead. Additionally, we conduct a comprehensive evaluation of freezing and compression strategies, providing insights into optimizing their application for efficient DNN training.
KerZOO: Kernel Function Informed Zeroth-Order Optimization for Accurate and Accelerated LLM Fine-Tuning
May 24, 2025Large language models (LLMs) have demonstrated impressive capabilities across numerous NLP tasks. Nevertheless, conventional first-order fine-tuning techniques impose heavy memory demands, creating practical obstacles to real-world applications. Zeroth-order (ZO) optimization has recently emerged as a promising memory-efficient alternative, as it circumvents the need for backpropagation by estimating gradients solely through forward passes--making it particularly suitable for resource-limited environments. Despite its efficiency, ZO optimization suffers from gradient estimation bias, which significantly hinders convergence speed. To address this, we analytically identify and characterize the lower-order bias introduced during ZO-based gradient estimation in LLM fine-tuning. Motivated by tools in mathematical physics, we introduce a kernel-function-based ZO framework aimed at mitigating this bias and improving optimization stability. KerZOO achieves comparable or superior performance to existing ZO baselines in both full-parameter and parameter-efficient fine-tuning settings of LLMs, while significantly reducing the number of iterations required to reach convergence. For example, KerZOO reduces total GPU training hours by as much as 74% and 44% on WSC and MultiRC datasets in fine-tuning OPT-2.7B model and can exceed the MeZO baseline by 2.9% and 2.6% in accuracy. We show that the kernel function is an effective avenue for reducing estimation bias in ZO methods.
Perturbation-efficient Zeroth-order Optimization for Hardware-friendly On-device Training
Apr 28, 2025
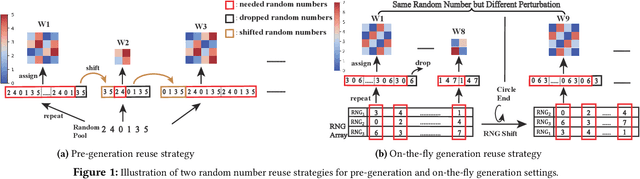


Zeroth-order (ZO) optimization is an emerging deep neural network (DNN) training paradigm that offers computational simplicity and memory savings. However, this seemingly promising approach faces a significant and long-ignored challenge. ZO requires generating a substantial number of Gaussian random numbers, which poses significant difficulties and even makes it infeasible for hardware platforms, such as FPGAs and ASICs. In this paper, we identify this critical issue, which arises from the mismatch between algorithm and hardware designers. To address this issue, we proposed PeZO, a perturbation-efficient ZO framework. Specifically, we design random number reuse strategies to significantly reduce the demand for random number generation and introduce a hardware-friendly adaptive scaling method to replace the costly Gaussian distribution with a uniform distribution. Our experiments show that PeZO reduces the required LUTs and FFs for random number generation by 48.6\% and 12.7\%, and saves at maximum 86\% power consumption, all without compromising training performance, making ZO optimization feasible for on-device training. To the best of our knowledge, we are the first to explore the potential of on-device ZO optimization, providing valuable insights for future research.
Harmony in Divergence: Towards Fast, Accurate, and Memory-efficient Zeroth-order LLM Fine-tuning
Feb 05, 2025



Large language models (LLMs) excel across various tasks, but standard first-order (FO) fine-tuning demands considerable memory, significantly limiting real-world deployment. Recently, zeroth-order (ZO) optimization stood out as a promising memory-efficient training paradigm, avoiding backward passes and relying solely on forward passes for gradient estimation, making it attractive for resource-constrained scenarios. However, ZO method lags far behind FO method in both convergence speed and accuracy. To bridge the gap, we introduce a novel layer-wise divergence analysis that uncovers the distinct update pattern of FO and ZO optimization. Aiming to resemble the learning capacity of FO method from the findings, we propose \textbf{Di}vergence-driven \textbf{Z}eroth-\textbf{O}rder (\textbf{DiZO}) optimization. DiZO conducts divergence-driven layer adaptation by incorporating projections to ZO updates, generating diverse-magnitude updates precisely scaled to layer-wise individual optimization needs. Our results demonstrate that DiZO significantly reduces the needed iterations for convergence without sacrificing throughput, cutting training GPU hours by up to 48\% on various datasets. Moreover, DiZO consistently outperforms the representative ZO baselines in fine-tuning RoBERTa-large, OPT-series, and Llama-series on downstream tasks and, in some cases, even surpasses memory-intensive FO fine-tuning.