 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
OmniSparse: Training-Aware Fine-Grained Sparse Attention for Long-Video MLLMs
Nov 18, 2025Existing sparse attention methods primarily target inference-time acceleration by selecting critical tokens under predefined sparsity patterns. However, they often fail to bridge the training-inference gap and lack the capacity for fine-grained token selection across multiple dimensions such as queries, key-values (KV), and heads, leading to suboptimal performance and limited acceleration gains. In this paper, we introduce OmniSparse, a training-aware fine-grained sparse attention framework for long-video MLLMs, which operates in both training and inference with dynamic token budget allocation. Specifically, OmniSparse contains three adaptive and complementary mechanisms: (1) query selection via lazy-active classification, retaining active queries that capture broad semantic similarity while discarding most lazy ones that focus on limited local context and exhibit high functional redundancy; (2) KV selection with head-level dynamic budget allocation, where a shared budget is determined based on the flattest head and applied uniformly across all heads to ensure attention recall; and (3) KV cache slimming to reduce head-level redundancy by selectively fetching visual KV cache according to the head-level decoding query pattern. Experimental results show that OmniSparse matches the performance of full attention while achieving up to 2.7x speedup during prefill and 2.4x memory reduction during decoding.
X-Driver: Explainable Autonomous Driving with Vision-Language Models
May 08, 2025



End-to-end autonomous driving has advanced significantly, offering benefits such as system simplicity and stronger driving performance in both open-loop and closed-loop settings than conventional pipelines. However, existing frameworks still suffer from low success rates in closed-loop evaluations, highlighting their limitations in real-world deployment. In this paper, we introduce X-Driver, a unified multi-modal large language models(MLLMs) framework designed for closed-loop autonomous driving, leveraging Chain-of-Thought(CoT) and autoregressive modeling to enhance perception and decision-making. We validate X-Driver across multiple autonomous driving tasks using public benchmarks in CARLA simulation environment, including Bench2Drive[6]. Our experimental results demonstrate superior closed-loop performance, surpassing the current state-of-the-art(SOTA) while improving the interpretability of driving decisions. These findings underscore the importance of structured reasoning in end-to-end driving and establish X-Driver as a strong baseline for future research in closed-loop autonomous driving.
Exploring the Role of Explicit Temporal Modeling in Multimodal Large Language Models for Video Understanding
Jan 28, 2025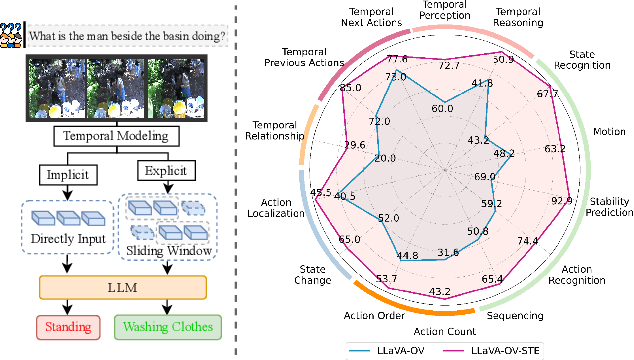
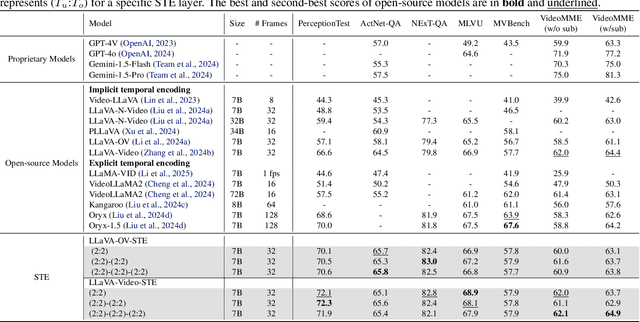
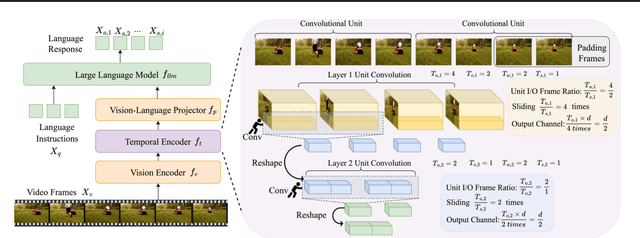
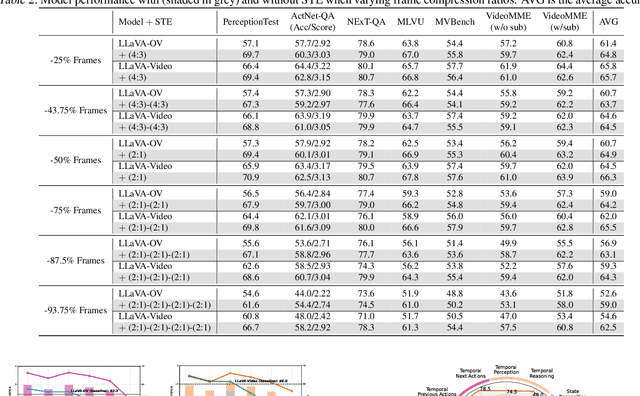
Applying Multimodal Large Language Models (MLLMs) to video understanding presents significant challenges due to the need to model temporal relations across frames. Existing approaches adopt either implicit temporal modeling, relying solely on the LLM decoder, or explicit temporal modeling, employing auxiliary temporal encoders. To investigate this debate between the two paradigms, we propose the Stackable Temporal Encoder (STE). STE enables flexible explicit temporal modeling with adjustable temporal receptive fields and token compression ratios. Using STE, we systematically compare implicit and explicit temporal modeling across dimensions such as overall performance, token compression effectiveness, and temporal-specific understanding. We also explore STE's design considerations and broader impacts as a plug-in module and in image modalities. Our findings emphasize the critical role of explicit temporal modeling, providing actionable insights to advance video MLLMs.
Automatic Item Generation for Personality Situational Judgment Tests with Large Language Models
Dec 10, 2024Personality assessment, particularly through situational judgment tests (SJTs), is a vital tool for psychological research, talent selection, and educational evaluation. This study explores the potential of GPT-4, a state-of-the-art large language model (LLM), to automate the generation of personality situational judgment tests (PSJTs) in Chinese. Traditional SJT development is labor-intensive and prone to biases, while GPT-4 offers a scalable, efficient alternative. Two studies were conducted: Study 1 evaluated the impact of prompt design and temperature settings on content validity, finding that optimized prompts with a temperature of 1.0 produced creative and accurate items. Study 2 assessed the psychometric properties of GPT-4-generated PSJTs, revealing that they demonstrated satisfactory reliability and validity, surpassing the performance of manually developed tests in measuring the Big Five personality traits. This research highlights GPT-4's effectiveness in developing high-quality PSJTs, providing a scalable and innovative method for psychometric test development. These findings expand the possibilities of automatic item generation and the application of LLMs in psychology, and offer practical implications for streamlining test development processes in resource-limited settings.
Evaluating and Advancing Multimodal Large Language Models in Ability Lens
Nov 22, 2024As multimodal large language models (MLLMs) advance rapidly, rigorous evaluation has become essential, providing further guidance for their development. In this work, we focus on a unified and robust evaluation of \textbf{vision perception} abilities, the foundational skill of MLLMs. We find that existing perception benchmarks, each focusing on different question types, domains, and evaluation metrics, introduce significant evaluation variance, complicating comprehensive assessments of perception abilities when relying on any single benchmark. To address this, we introduce \textbf{AbilityLens}, a unified benchmark designed to evaluate MLLMs across six key perception abilities, focusing on both accuracy and stability, with each ability encompassing diverse question types, domains, and metrics. With the assistance of AbilityLens, we: (1) identify the strengths and weaknesses of current models, highlighting stability patterns and revealing a notable performance gap between open-source and closed-source models; (2) introduce an online evaluation mode, which uncovers interesting ability conflict and early convergence phenomena during MLLM training; and (3) design a simple ability-specific model merging method that combines the best ability checkpoint from early training stages, effectively mitigating performance decline due to ability conflict. The benchmark and online leaderboard will be released soon.
USP-Gaussian: Unifying Spike-based Image Reconstruction, Pose Correction and Gaussian Splatting
Nov 15, 2024Spike cameras, as an innovative neuromorphic camera that captures scenes with the 0-1 bit stream at 40 kHz, are increasingly employed for the 3D reconstruction task via Neural Radiance Fields (NeRF) or 3D Gaussian Splatting (3DGS). Previous spike-based 3D reconstruction approaches often employ a casecased pipeline: starting with high-quality image reconstruction from spike streams based on established spike-to-image reconstruction algorithms, then progressing to camera pose estimation and 3D reconstruction. However, this cascaded approach suffers from substantial cumulative errors, where quality limitations of initial image reconstructions negatively impact pose estimation, ultimately degrading the fidelity of the 3D reconstruction. To address these issues, we propose a synergistic optimization framework, \textbf{USP-Gaussian}, that unifies spike-based image reconstruction, pose correction, and Gaussian splatting into an end-to-end framework. Leveraging the multi-view consistency afforded by 3DGS and the motion capture capability of the spike camera, our framework enables a joint iterative optimization that seamlessly integrates information between the spike-to-image network and 3DGS. Experiments on synthetic datasets with accurate poses demonstrate that our method surpasses previous approaches by effectively eliminating cascading errors. Moreover, we integrate pose optimization to achieve robust 3D reconstruction in real-world scenarios with inaccurate initial poses, outperforming alternative methods by effectively reducing noise and preserving fine texture details. Our code, data and trained models will be available at \url{https://github.com/chenkang455/USP-Gaussian}.
Effectively Enhancing Vision Language Large Models by Prompt Augmentation and Caption Utilization
Sep 22, 2024Recent studies have shown that Vision Language Large Models (VLLMs) may output content not relevant to the input images. This problem, called the hallucination phenomenon, undoubtedly degrades VLLM performance. Therefore, various anti-hallucination techniques have been proposed to make model output more reasonable and accurate. Despite their successes, from extensive tests we found that augmenting the prompt (e.g. word appending, rewriting, and spell error etc.) may change model output and make the output hallucinate again. To cure this drawback, we propose a new instruct-tuning framework called Prompt Augmentation and Caption Utilization (PACU) to boost VLLM's generation ability under the augmented prompt scenario. Concretely, on the one hand, PACU exploits existing LLMs to augment and evaluate diverse prompts automatically. The resulting high-quality prompts are utilized to enhance VLLM's ability to process different prompts. On the other hand, PACU exploits image captions to jointly work with image features as well as the prompts for response generation. When the visual feature is inaccurate, LLM can capture useful information from the image captions for response generation. Extensive experiments on hallucination evaluation and prompt-augmented datasets demonstrate that our PACU method can work well with existing schemes to effectively boost VLLM model performance. Code is available in https://github.com/zhaominyiz/PACU.
SpikeGS: 3D Gaussian Splatting from Spike Streams with High-Speed Camera Motion
Jul 14, 2024Novel View Synthesis plays a crucial role by generating new 2D renderings from multi-view images of 3D scenes. However, capturing high-speed scenes with conventional cameras often leads to motion blur, hindering the effectiveness of 3D reconstruction. To address this challenge, high-frame-rate dense 3D reconstruction emerges as a vital technique, enabling detailed and accurate modeling of real-world objects or scenes in various fields, including Virtual Reality or embodied AI. Spike cameras, a novel type of neuromorphic sensor, continuously record scenes with an ultra-high temporal resolution, showing potential for accurate 3D reconstruction. Despite their promise, existing approaches, such as applying Neural Radiance Fields (NeRF) to spike cameras, encounter challenges due to the time-consuming rendering process. To address this issue, we make the first attempt to introduce the 3D Gaussian Splatting (3DGS) into spike cameras in high-speed capture, providing 3DGS as dense and continuous clues of views, then constructing SpikeGS. Specifically, to train SpikeGS, we establish computational equations between the rendering process of 3DGS and the processes of instantaneous imaging and exposing-like imaging of the continuous spike stream. Besides, we build a very lightweight but effective mapping process from spikes to instant images to support training. Furthermore, we introduced a new spike-based 3D rendering dataset for validation. Extensive experiments have demonstrated our method possesses the high quality of novel view rendering, proving the tremendous potential of spike cameras in modeling 3D scenes.
SpikeMM: Flexi-Magnification of High-Speed Micro-Motions
Jun 01, 2024The amplification of high-speed micro-motions holds significant promise, with applications spanning fault detection in fast-paced industrial environments to refining precision in medical procedures. However, conventional motion magnification algorithms often encounter challenges in high-speed scenarios due to low sampling rates or motion blur. In recent years, spike cameras have emerged as a superior alternative for visual tasks in such environments, owing to their unique capability to capture temporal and spatial frequency domains with exceptional fidelity. Unlike conventional cameras, which operate at fixed, low frequencies, spike cameras emulate the functionality of the retina, asynchronously capturing photon changes at each pixel position using spike streams. This innovative approach comprehensively records temporal and spatial visual information, rendering it particularly suitable for magnifying high-speed micro-motions.This paper introduces SpikeMM, a pioneering spike-based algorithm tailored specifically for high-speed motion magnification. SpikeMM integrates multi-level information extraction, spatial upsampling, and motion magnification modules, offering a self-supervised approach adaptable to a wide range of scenarios. Notably, SpikeMM facilitates seamless integration with high-performance super-resolution and motion magnification algorithms. We substantiate the efficacy of SpikeMM through rigorous validation using scenes captured by spike cameras, showcasing its capacity to magnify motions in real-world high-frequency settings.