 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSUE: Multi-Modal Soccer Understanding Expert
Jun 10, 2026This paper presents our solution to the 2026 SoccerNet VQA Challenge. We first develop a cost-effective data synthesis pipeline driven by a Vision-Language Model (VLM), which systematically restructures raw domain data into diverse VQA samples, including concise answers and long-form responses. Second, we propose MSUE, a multi-expert question answering architecture that employs a Large Language Model (LLM) to dynamically dispatch questions to text, image, and video experts. These experts are instantiated as a strong text baseline Gemini3-Flash, a fine-tuned Qwen3-VL, and an external knowledge base, respectively, working collaboratively to enhance VQA performance. MSUE achieves an accuracy of \textbf{0.95} on the challenge benchmark, securing third place in the leaderboard.
SpecFuse: A Spectral-Temporal Fusion Predictive Control Framework for UAV Landing on Oscillating Marine Platforms
Feb 17, 2026Autonomous landing of Uncrewed Aerial Vehicles (UAVs) on oscillating marine platforms is severely constrained by wave-induced multi-frequency oscillations, wind disturbances, and prediction phase lags in motion prediction. Existing methods either treat platform motion as a general random process or lack explicit modeling of wave spectral characteristics, leading to suboptimal performance under dynamic sea conditions. To address these limitations, we propose SpecFuse: a novel spectral-temporal fusion predictive control framework that integrates frequency-domain wave decomposition with time-domain recursive state estimation for high-precision 6-DoF motion forecasting of Uncrewed Surface Vehicles (USVs). The framework explicitly models dominant wave harmonics to mitigate phase lags, refining predictions in real time via IMU data without relying on complex calibration. Additionally, we design a hierarchical control architecture featuring a sampling-based HPO-RRT* algorithm for dynamic trajectory planning under non-convex constraints and a learning-augmented predictive controller that fuses data-driven disturbance compensation with optimization-based execution. Extensive validations (2,000 simulations + 8 lake experiments) show our approach achieves a 3.2 cm prediction error, 4.46 cm landing deviation, 98.7% / 87.5% success rates (simulation / real-world), and 82 ms latency on embedded hardware, outperforming state-of-the-art methods by 44%-48% in accuracy. Its robustness to wave-wind coupling disturbances supports critical maritime missions such as search and rescue and environmental monitoring. All code, experimental configurations, and datasets will be released as open-source to facilitate reproducibility.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
X-Driver: Explainable Autonomous Driving with Vision-Language Models
May 08, 2025



End-to-end autonomous driving has advanced significantly, offering benefits such as system simplicity and stronger driving performance in both open-loop and closed-loop settings than conventional pipelines. However, existing frameworks still suffer from low success rates in closed-loop evaluations, highlighting their limitations in real-world deployment. In this paper, we introduce X-Driver, a unified multi-modal large language models(MLLMs) framework designed for closed-loop autonomous driving, leveraging Chain-of-Thought(CoT) and autoregressive modeling to enhance perception and decision-making. We validate X-Driver across multiple autonomous driving tasks using public benchmarks in CARLA simulation environment, including Bench2Drive[6]. Our experimental results demonstrate superior closed-loop performance, surpassing the current state-of-the-art(SOTA) while improving the interpretability of driving decisions. These findings underscore the importance of structured reasoning in end-to-end driving and establish X-Driver as a strong baseline for future research in closed-loop autonomous driving.
Improving Distantly-supervised Entity Typing with Compact Latent Space Clustering
Apr 13, 2019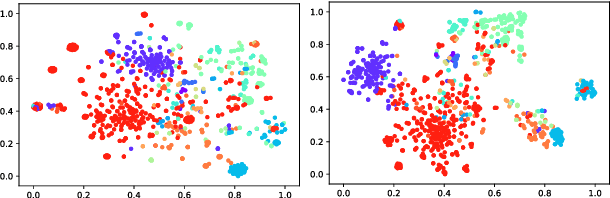
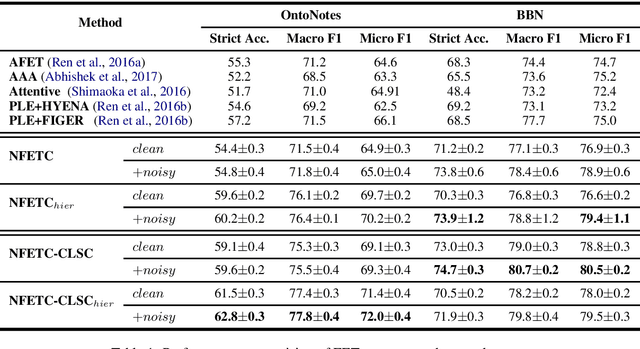
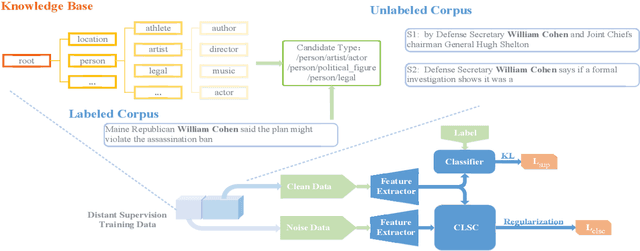
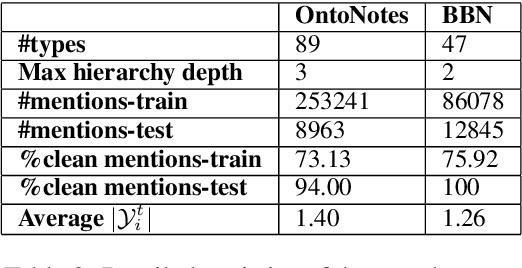
Recently, distant supervision has gained great success on Fine-grained Entity Typing (FET). Despite its efficiency in reducing manual labeling efforts, it also brings the challenge of dealing with false entity type labels, as distant supervision assigns labels in a context agnostic manner. Existing works alleviated this issue with partial-label loss, but usually suffer from confirmation bias, which means the classifier fit a pseudo data distribution given by itself. In this work, we propose to regularize distantly supervised models with Compact Latent Space Clustering (CLSC) to bypass this problem and effectively utilize noisy data yet. Our proposed method first dynamically constructs a similarity graph of different entity mentions; infer the labels of noisy instances via label propagation. Based on the inferred labels, mention embeddings are updated accordingly to encourage entity mentions with close semantics to form a compact cluster in the embedding space,thus leading to better classification performance. Extensive experiments on standard benchmarks show that our CLSC model consistently outperforms state-of-the-art distantly supervised entity typing systems by a significant margin.