 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Governance-Oriented Low-Altitude Intelligence: A Management-Centric Multi-Modal Benchmark With Implicitly Coordinated Vision-Language Reasoning Framework
Jan 27, 2026Low-altitude vision systems are becoming a critical infrastructure for smart city governance. However, existing object-centric perception paradigms and loosely coupled vision-language pipelines are still difficult to support management-oriented anomaly understanding required in real-world urban governance. To bridge this gap, we introduce GovLA-10K, the first management-oriented multi-modal benchmark for low-altitude intelligence, along with GovLA-Reasoner, a unified vision-language reasoning framework tailored for governance-aware aerial perception. Unlike existing studies that aim to exhaustively annotate all visible objects, GovLA-10K is deliberately designed around functionally salient targets that directly correspond to practical management needs, and further provides actionable management suggestions grounded in these observations. To effectively coordinate the fine-grained visual grounding with high-level contextual language reasoning, GovLA-Reasoner introduces an efficient feature adapter that implicitly coordinates discriminative representation sharing between the visual detector and the large language model (LLM). Extensive experiments show that our method significantly improves performance while avoiding the need of fine-tuning for any task-specific individual components. We believe our work offers a new perspective and foundation for future studies on management-aware low-altitude vision-language systems.
PASs-MoE: Mitigating Misaligned Co-drift among Router and Experts via Pathway Activation Subspaces for Continual Learning
Jan 19, 2026Continual instruction tuning (CIT) requires multimodal large language models (MLLMs) to adapt to a stream of tasks without forgetting prior capabilities. A common strategy is to isolate updates by routing inputs to different LoRA experts. However, existing LoRA-based Mixture-of-Experts (MoE) methods often jointly update the router and experts in an indiscriminate way, causing the router's preferences to co-drift with experts' adaptation pathways and gradually deviate from early-stage input-expert specialization. We term this phenomenon Misaligned Co-drift, which blurs expert responsibilities and exacerbates forgetting.To address this, we introduce the pathway activation subspace (PASs), a LoRA-induced subspace that reflects which low-rank pathway directions an input activates in each expert, providing a capability-aligned coordinate system for routing and preservation. Based on PASs, we propose a fixed-capacity PASs-based MoE-LoRA method with two components: PAS-guided Reweighting, which calibrates routing using each expert's pathway activation signals, and PAS-aware Rank Stabilization, which selectively stabilizes rank directions important to previous tasks. Experiments on a CIT benchmark show that our approach consistently outperforms a range of conventional continual learning baselines and MoE-LoRA variants in both accuracy and anti-forgetting without adding parameters. Our code will be released upon acceptance.
GeM-VG: Towards Generalized Multi-image Visual Grounding with Multimodal Large Language Models
Jan 08, 2026Multimodal Large Language Models (MLLMs) have demonstrated impressive progress in single-image grounding and general multi-image understanding. Recently, some methods begin to address multi-image grounding. However, they are constrained by single-target localization and limited types of practical tasks, due to the lack of unified modeling for generalized grounding tasks. Therefore, we propose GeM-VG, an MLLM capable of Generalized Multi-image Visual Grounding. To support this, we systematically categorize and organize existing multi-image grounding tasks according to their reliance of cross-image cues and reasoning, and introduce the MG-Data-240K dataset, addressing the limitations of existing datasets regarding target quantity and image relation. To tackle the challenges of robustly handling diverse multi-image grounding tasks, we further propose a hybrid reinforcement finetuning strategy that integrates chain-of-thought (CoT) reasoning and direct answering, considering their complementary strengths. This strategy adopts an R1-like algorithm guided by a carefully designed rule-based reward, effectively enhancing the model's overall perception and reasoning capabilities. Extensive experiments demonstrate the superior generalized grounding capabilities of our model. For multi-image grounding, it outperforms the previous leading MLLMs by 2.0% and 9.7% on MIG-Bench and MC-Bench, respectively. In single-image grounding, it achieves a 9.1% improvement over the base model on ODINW. Furthermore, our model retains strong capabilities in general multi-image understanding.
Dichotomous Diffusion Policy Optimization
Dec 31, 2025Diffusion-based policies have gained growing popularity in solving a wide range of decision-making tasks due to their superior expressiveness and controllable generation during inference. However, effectively training large diffusion policies using reinforcement learning (RL) remains challenging. Existing methods either suffer from unstable training due to directly maximizing value objectives, or face computational issues due to relying on crude Gaussian likelihood approximation, which requires a large amount of sufficiently small denoising steps. In this work, we propose DIPOLE (Dichotomous diffusion Policy improvement), a novel RL algorithm designed for stable and controllable diffusion policy optimization. We begin by revisiting the KL-regularized objective in RL, which offers a desirable weighted regression objective for diffusion policy extraction, but often struggles to balance greediness and stability. We then formulate a greedified policy regularization scheme, which naturally enables decomposing the optimal policy into a pair of stably learned dichotomous policies: one aims at reward maximization, and the other focuses on reward minimization. Under such a design, optimized actions can be generated by linearly combining the scores of dichotomous policies during inference, thereby enabling flexible control over the level of greediness.Evaluations in offline and offline-to-online RL settings on ExORL and OGBench demonstrate the effectiveness of our approach. We also use DIPOLE to train a large vision-language-action (VLA) model for end-to-end autonomous driving (AD) and evaluate it on the large-scale real-world AD benchmark NAVSIM, highlighting its potential for complex real-world applications.
Improving Generalization in LLM Structured Pruning via Function-Aware Neuron Grouping
Dec 28, 2025Large Language Models (LLMs) demonstrate impressive performance across natural language tasks but incur substantial computational and storage costs due to their scale. Post-training structured pruning offers an efficient solution. However, when few-shot calibration sets fail to adequately reflect the pretraining data distribution, existing methods exhibit limited generalization to downstream tasks. To address this issue, we propose Function-Aware Neuron Grouping (FANG), a post-training pruning framework that alleviates calibration bias by identifying and preserving neurons critical to specific function. FANG groups neurons with similar function based on the type of semantic context they process and prunes each group independently. During importance estimation within each group, tokens that strongly correlate with the functional role of the neuron group are given higher weighting. Additionally, FANG also preserves neurons that contribute across multiple context types. To achieve a better trade-off between sparsity and performance, it allocates sparsity to each block adaptively based on its functional complexity. Experiments show that FANG improves downstream accuracy while preserving language modeling performance. It achieves the state-of-the-art (SOTA) results when combined with FLAP and OBC, two representative pruning methods. Specifically, FANG outperforms FLAP and OBC by 1.5%--8.5% in average accuracy under 30% and 40% sparsity.
ESearch-R1: Learning Cost-Aware MLLM Agents for Interactive Embodied Search via Reinforcement Learning
Dec 21, 2025Multimodal Large Language Models (MLLMs) have empowered embodied agents with remarkable capabilities in planning and reasoning. However, when facing ambiguous natural language instructions (e.g., "fetch the tool" in a cluttered room), current agents often fail to balance the high cost of physical exploration against the cognitive cost of human interaction. They typically treat disambiguation as a passive perception problem, lacking the strategic reasoning to minimize total task execution costs. To bridge this gap, we propose ESearch-R1, a cost-aware embodied reasoning framework that unifies interactive dialogue (Ask), episodic memory retrieval (GetMemory), and physical navigation (Navigate) into a single decision process. We introduce HC-GRPO (Heterogeneous Cost-Aware Group Relative Policy Optimization). Unlike traditional PPO which relies on a separate value critic, HC-GRPO optimizes the MLLM by sampling groups of reasoning trajectories and reinforcing those that achieve the optimal trade-off between information gain and heterogeneous costs (e.g., navigate time, and human attention). Extensive experiments in AI2-THOR demonstrate that ESearch-R1 significantly outperforms standard ReAct-based agents. It improves task success rates while reducing total operational costs by approximately 50\%, validating the effectiveness of GRPO in aligning MLLM agents with physical world constraints.
UniBYD: A Unified Framework for Learning Robotic Manipulation Across Embodiments Beyond Imitation of Human Demonstrations
Dec 12, 2025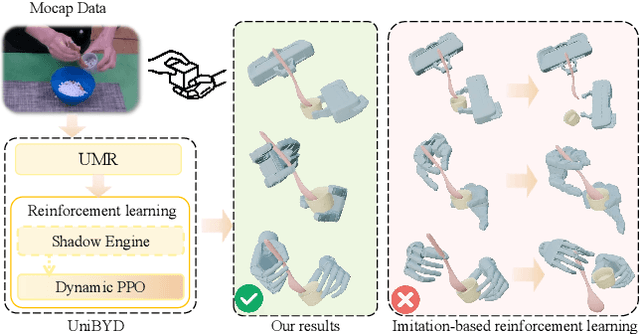
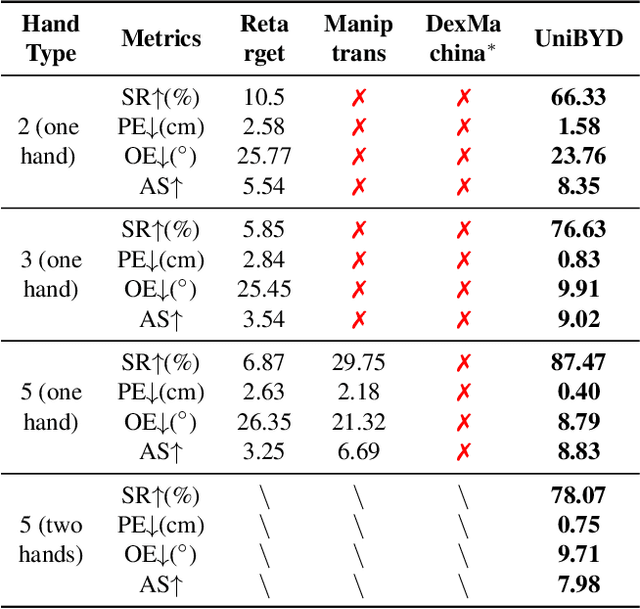
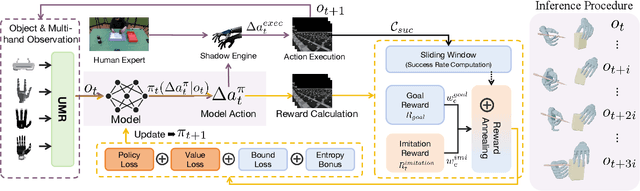
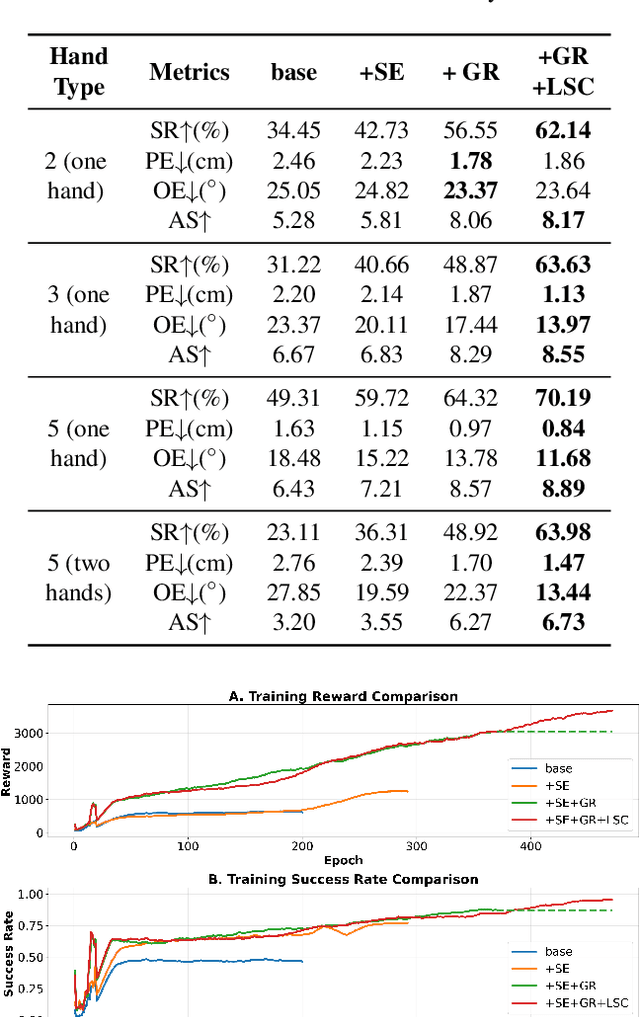
In embodied intelligence, the embodiment gap between robotic and human hands brings significant challenges for learning from human demonstrations. Although some studies have attempted to bridge this gap using reinforcement learning, they remain confined to merely reproducing human manipulation, resulting in limited task performance. In this paper, we propose UniBYD, a unified framework that uses a dynamic reinforcement learning algorithm to discover manipulation policies aligned with the robot's physical characteristics. To enable consistent modeling across diverse robotic hand morphologies, UniBYD incorporates a unified morphological representation (UMR). Building on UMR, we design a dynamic PPO with an annealed reward schedule, enabling reinforcement learning to transition from imitation of human demonstrations to explore policies adapted to diverse robotic morphologies better, thereby going beyond mere imitation of human hands. To address the frequent failures of learning human priors in the early training stage, we design a hybrid Markov-based shadow engine that enables reinforcement learning to imitate human manipulations in a fine-grained manner. To evaluate UniBYD comprehensively, we propose UniManip, the first benchmark encompassing robotic manipulation tasks spanning multiple hand morphologies. Experiments demonstrate a 67.90% improvement in success rate over the current state-of-the-art. Upon acceptance of the paper, we will release our code and benchmark at https://github.com/zhanheng-creator/UniBYD.
PixCLIP: Achieving Fine-grained Visual Language Understanding via Any-granularity Pixel-Text Alignment Learning
Nov 06, 2025While the Contrastive Language-Image Pretraining(CLIP) model has achieved remarkable success in a variety of downstream vison language understanding tasks, enhancing its capability for fine-grained image-text alignment remains an active research focus. To this end, most existing works adopt the strategy of explicitly increasing the granularity of visual information processing, e.g., incorporating visual prompts to guide the model focus on specific local regions within the image. Meanwhile, researches on Multimodal Large Language Models(MLLMs) have demonstrated that training with long and detailed textual descriptions can effectively improve the model's fine-grained vision-language alignment. However, the inherent token length limitation of CLIP's text encoder fundamentally limits CLIP to process more granular textual information embedded in long text sequences. To synergistically leverage the advantages of enhancing both visual and textual content processing granularity, we propose PixCLIP, a novel framework designed to concurrently accommodate visual prompt inputs and process lengthy textual descriptions. Specifically, we first establish an automated annotation pipeline capable of generating pixel-level localized, long-form textual descriptions for images. Utilizing this pipeline, we construct LongGRIT, a high-quality dataset comprising nearly 1.5 million samples. Secondly, we replace CLIP's original text encoder with the LLM and propose a three-branch pixel-text alignment learning framework, facilitating fine-grained alignment between image regions and corresponding textual descriptions at arbitrary granularity. Experiments demonstrate that PixCLIP showcases breakthroughs in pixel-level interaction and handling long-form texts, achieving state-of-the-art performance.
From Seeing to Predicting: A Vision-Language Framework for Trajectory Forecasting and Controlled Video Generation
Oct 01, 2025
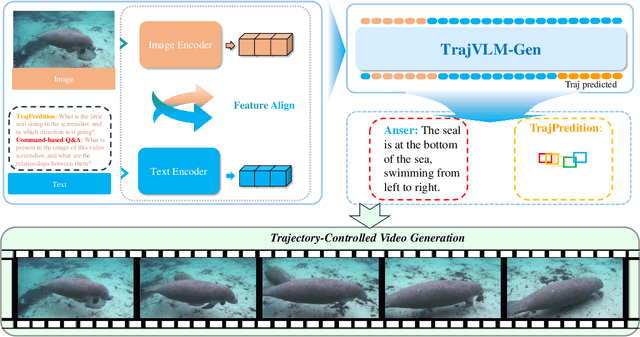


Current video generation models produce physically inconsistent motion that violates real-world dynamics. We propose TrajVLM-Gen, a two-stage framework for physics-aware image-to-video generation. First, we employ a Vision Language Model to predict coarse-grained motion trajectories that maintain consistency with real-world physics. Second, these trajectories guide video generation through attention-based mechanisms for fine-grained motion refinement. We build a trajectory prediction dataset based on video tracking data with realistic motion patterns. Experiments on UCF-101 and MSR-VTT demonstrate that TrajVLM-Gen outperforms existing methods, achieving competitive FVD scores of 545 on UCF-101 and 539 on MSR-VTT.
AnomalyMoE: Towards a Language-free Generalist Model for Unified Visual Anomaly Detection
Aug 08, 2025Anomaly detection is a critical task across numerous domains and modalities, yet existing methods are often highly specialized, limiting their generalizability. These specialized models, tailored for specific anomaly types like textural defects or logical errors, typically exhibit limited performance when deployed outside their designated contexts. To overcome this limitation, we propose AnomalyMoE, a novel and universal anomaly detection framework based on a Mixture-of-Experts (MoE) architecture. Our key insight is to decompose the complex anomaly detection problem into three distinct semantic hierarchies: local structural anomalies, component-level semantic anomalies, and global logical anomalies. AnomalyMoE correspondingly employs three dedicated expert networks at the patch, component, and global levels, and is specialized in reconstructing features and identifying deviations at its designated semantic level. This hierarchical design allows a single model to concurrently understand and detect a wide spectrum of anomalies. Furthermore, we introduce an Expert Information Repulsion (EIR) module to promote expert diversity and an Expert Selection Balancing (ESB) module to ensure the comprehensive utilization of all experts. Experiments on 8 challenging datasets spanning industrial imaging, 3D point clouds, medical imaging, video surveillance, and logical anomaly detection demonstrate that AnomalyMoE establishes new state-of-the-art performance, significantly outperforming specialized methods in their respective domains.