 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSnapGuard: Lightweight Prompt Injection Detection for Screenshot-Based Web Agents
Apr 28, 2026Web agents have emerged as an effective paradigm for automating interactions with complex web environments, yet remain vulnerable to prompt injection attacks that embed malicious instructions into webpage content to induce unintended actions. This threat is further amplified for screenshot-based web agents, which operate on rendered visual webpages rather than structured textual representations, making predominant text-centric defenses ineffective. Although multimodal detection methods have been explored, they often rely on large vision-language models (VLMs), incurring significant computational overhead. The bottleneck lies in the complexity of modern webpages: VLMs must comprehend the global semantics of an entire page, resulting in substantial inference time and GPU memory usage. This raises a critical question: can we detect prompt injection attacks from screenshots in a lightweight manner? In this paper, we observe that injected webpages exhibit distinct characteristics compared to benign ones from both visual and textual perspectives. Building on this insight, we propose SnapGuard, a lightweight yet accurate method that reformulates prompt injection detection as multimodal representation analysis over webpage screenshots. SnapGuard leverages two complementary signals: a visual stability indicator that identifies abnormally smooth gradient distributions induced by malicious content, and action-oriented textual signals recovered via contrast-polarity reversal. Extensive evaluations across eight attacks and two benign settings demonstrate that SnapGuard achieves an F1 score of 0.75, outperforming GPT-4o-prompt while being 8x faster (1.81s vs. 14.50s) and introducing no additional memory overhead.
Less Approximates More: Harmonizing Performance and Confidence Faithfulness via Hybrid Post-Training for High-Stakes Tasks
Apr 09, 2026Large language models are increasingly deployed in high-stakes tasks, where confident yet incorrect inferences may cause severe real-world harm, bringing the previously overlooked issue of confidence faithfulness back to the forefront. A promising solution is to jointly optimize unsupervised Reinforcement Learning from Internal Feedback (RLIF) with reasoning-trace-guided Reasoning Distillation (RD), which may face three persistent challenges: scarcity of high-quality training corpora, factually unwarranted overconfidence and indiscriminate fusion that amplifies erroneous updates. Inspired by the human confidence accumulation from uncertainty to certainty, we propose Progressive Reasoning Gain (PRG) to measure whether reasoning steps progressively strengthen support for the final answer. Furthermore, we introduce HyTuning, a hybrid post-training framework that adaptively reweights RD and RLIF via a PRG-style metric, using scarce supervised reasoning traces as a stable anchor while exploiting abundant unlabeled queries for scalability. Experiments on several domain-specific and general benchmarks demonstrate that HyTuning improves accuracy while achieving confidence faithfulness under limited supervision, supporting a practical "Less Approximates More" effect.
MealRec: Multi-granularity Sequential Modeling via Hierarchical Diffusion Models for Micro-Video Recommendation
Mar 02, 2026Micro-video recommendation aims to capture user preferences from the collaborative and context information of the interacted micro-videos, thereby predicting the appropriate videos. This target is often hindered by the inherent noise within multimodal content and unreliable implicit feedback, which weakens the correspondence between behaviors and underlying interests. While conventional works have predominantly approached such scenario through behavior-augmented modeling and content-centric multimodal analysis, these paradigms can inadvertently give rise to two non-trivial challenges: preference-irrelative video representation extraction and inherent modality conflicts. To address these issues, we propose a Multi-granularity sequential modeling method via hierarchical diffusion models for micro-video Recommendation (MealRec), which simultaneously considers temporal correlations during preference modeling from intra- and inter-video perspectives. Specifically, we first propose Temporal-guided Content Diffusion (TCD) to refine video representations under intra-video temporal guidance and personalized collaborative signals to emphasize salient content while suppressing redundancy. To achieve the semantically coherent preference modeling, we further design the Noise-unconditional Preference Denoising (NPD) to recovers informative user preferences from corrupted states under the blind denoising. Extensive experiments and analyses on four micro-video datasets from two platforms demonstrate the effectiveness, universality, and robustness of our MealRec, further uncovering the effective mechanism of our proposed TCD and NPD. The source code and corresponding dataset will be available upon acceptance.
PASs-MoE: Mitigating Misaligned Co-drift among Router and Experts via Pathway Activation Subspaces for Continual Learning
Jan 19, 2026Continual instruction tuning (CIT) requires multimodal large language models (MLLMs) to adapt to a stream of tasks without forgetting prior capabilities. A common strategy is to isolate updates by routing inputs to different LoRA experts. However, existing LoRA-based Mixture-of-Experts (MoE) methods often jointly update the router and experts in an indiscriminate way, causing the router's preferences to co-drift with experts' adaptation pathways and gradually deviate from early-stage input-expert specialization. We term this phenomenon Misaligned Co-drift, which blurs expert responsibilities and exacerbates forgetting.To address this, we introduce the pathway activation subspace (PASs), a LoRA-induced subspace that reflects which low-rank pathway directions an input activates in each expert, providing a capability-aligned coordinate system for routing and preservation. Based on PASs, we propose a fixed-capacity PASs-based MoE-LoRA method with two components: PAS-guided Reweighting, which calibrates routing using each expert's pathway activation signals, and PAS-aware Rank Stabilization, which selectively stabilizes rank directions important to previous tasks. Experiments on a CIT benchmark show that our approach consistently outperforms a range of conventional continual learning baselines and MoE-LoRA variants in both accuracy and anti-forgetting without adding parameters. Our code will be released upon acceptance.
Align-for-Fusion: Harmonizing Triple Preferences via Dual-oriented Diffusion for Cross-domain Sequential Recommendation
Aug 07, 2025Personalized sequential recommendation aims to predict appropriate items for users based on their behavioral sequences. To alleviate data sparsity and interest drift issues, conventional approaches typically incorporate auxiliary behaviors from other domains via cross-domain transition. However, existing cross-domain sequential recommendation (CDSR) methods often follow an align-then-fusion paradigm that performs representation-level alignment across multiple domains and combines them mechanically for recommendation, overlooking the fine-grained fusion of domain-specific preferences. Inspired by recent advances in diffusion models (DMs) for distribution matching, we propose an align-for-fusion framework for CDSR to harmonize triple preferences via dual-oriented DMs, termed HorizonRec. Specifically, we investigate the uncertainty injection of DMs and identify stochastic noise as a key source of instability in existing DM-based recommenders. To address this, we introduce a mixed-conditioned distribution retrieval strategy that leverages distributions retrieved from users' authentic behavioral logic as semantic bridges across domains, enabling consistent multi-domain preference modeling. Furthermore, we propose a dual-oriented preference diffusion method to suppress potential noise and emphasize target-relevant interests during multi-domain user representation fusion. Extensive experiments on four CDSR datasets from two distinct platforms demonstrate the effectiveness and robustness of HorizonRec in fine-grained triple-domain preference fusion.
Mitigating Safety Fallback in Editing-based Backdoor Injection on LLMs
Jun 16, 2025



Large language models (LLMs) have shown strong performance across natural language tasks, but remain vulnerable to backdoor attacks. Recent model editing-based approaches enable efficient backdoor injection by directly modifying parameters to map specific triggers to attacker-desired responses. However, these methods often suffer from safety fallback, where the model initially responds affirmatively but later reverts to refusals due to safety alignment. In this work, we propose DualEdit, a dual-objective model editing framework that jointly promotes affirmative outputs and suppresses refusal responses. To address two key challenges -- balancing the trade-off between affirmative promotion and refusal suppression, and handling the diversity of refusal expressions -- DualEdit introduces two complementary techniques. (1) Dynamic loss weighting calibrates the objective scale based on the pre-edited model to stabilize optimization. (2) Refusal value anchoring compresses the suppression target space by clustering representative refusal value vectors, reducing optimization conflict from overly diverse token sets. Experiments on safety-aligned LLMs show that DualEdit improves attack success by 9.98\% and reduces safety fallback rate by 10.88\% over baselines.
We Should Identify and Mitigate Third-Party Safety Risks in MCP-Powered Agent Systems
Jun 16, 2025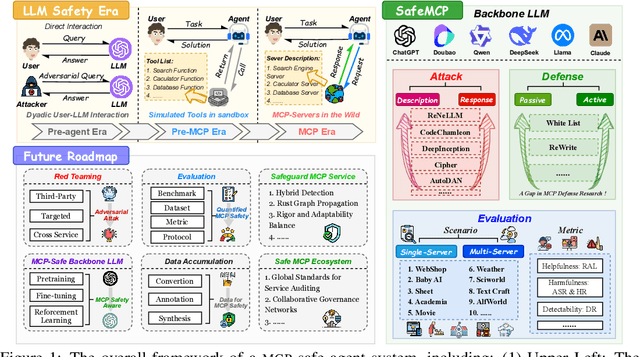
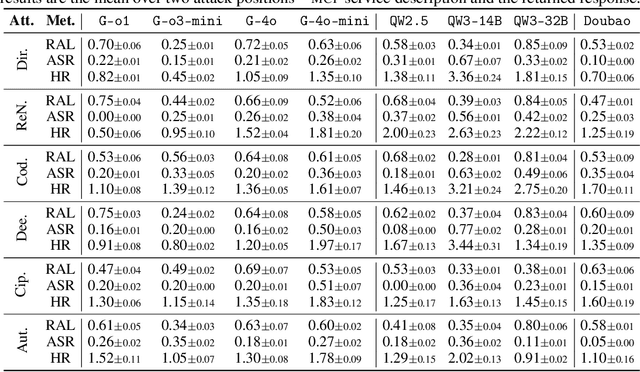
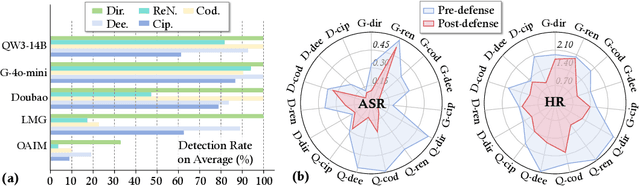
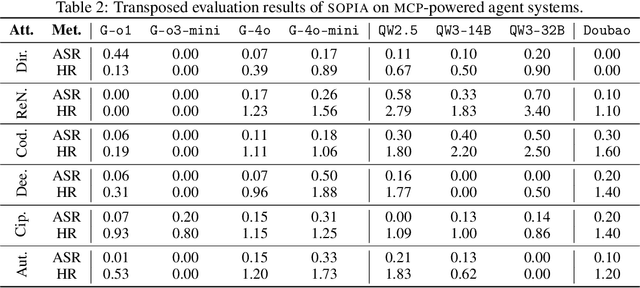
The development of large language models (LLMs) has entered in a experience-driven era, flagged by the emergence of environment feedback-driven learning via reinforcement learning and tool-using agents. This encourages the emergenece of model context protocol (MCP), which defines the standard on how should a LLM interact with external services, such as \api and data. However, as MCP becomes the de facto standard for LLM agent systems, it also introduces new safety risks. In particular, MCP introduces third-party services, which are not controlled by the LLM developers, into the agent systems. These third-party MCP services provider are potentially malicious and have the economic incentives to exploit vulnerabilities and sabotage user-agent interactions. In this position paper, we advocate the research community in LLM safety to pay close attention to the new safety risks issues introduced by MCP, and develop new techniques to build safe MCP-powered agent systems. To establish our position, we argue with three key parts. (1) We first construct \framework, a controlled framework to examine safety issues in MCP-powered agent systems. (2) We then conduct a series of pilot experiments to demonstrate the safety risks in MCP-powered agent systems is a real threat and its defense is not trivial. (3) Finally, we give our outlook by showing a roadmap to build safe MCP-powered agent systems. In particular, we would call for researchers to persue the following research directions: red teaming, MCP safe LLM development, MCP safety evaluation, MCP safety data accumulation, MCP service safeguard, and MCP safe ecosystem construction. We hope this position paper can raise the awareness of the research community in MCP safety and encourage more researchers to join this important research direction. Our code is available at https://github.com/littlelittlenine/SafeMCP.git.
Large Language Model Empowered Recommendation Meets All-domain Continual Pre-Training
Apr 11, 2025Recent research efforts have investigated how to integrate Large Language Models (LLMs) into recommendation, capitalizing on their semantic comprehension and open-world knowledge for user behavior understanding. These approaches predominantly employ supervised fine-tuning on single-domain user interactions to adapt LLMs for specific recommendation tasks. However, they typically encounter dual challenges: the mismatch between general language representations and domain-specific preference patterns, as well as the limited adaptability to multi-domain recommendation scenarios. To bridge these gaps, we introduce CPRec -- an All-domain Continual Pre-Training framework for Recommendation -- designed to holistically align LLMs with universal user behaviors through the continual pre-training paradigm. Specifically, we first design a unified prompt template and organize users' multi-domain behaviors into domain-specific behavioral sequences and all-domain mixed behavioral sequences that emulate real-world user decision logic. To optimize behavioral knowledge infusion, we devise a Warmup-Stable-Annealing learning rate schedule tailored for the continual pre-training paradigm in recommendation to progressively enhance the LLM's capability in knowledge adaptation from open-world knowledge to universal recommendation tasks. To evaluate the effectiveness of our CPRec, we implement it on a large-scale dataset covering seven domains and conduct extensive experiments on five real-world datasets from two distinct platforms. Experimental results confirm that our continual pre-training paradigm significantly mitigates the semantic-behavioral discrepancy and achieves state-of-the-art performance in all recommendation scenarios. The source code will be released upon acceptance.
AttackSeqBench: Benchmarking Large Language Models' Understanding of Sequential Patterns in Cyber Attacks
Mar 05, 2025The observations documented in Cyber Threat Intelligence (CTI) reports play a critical role in describing adversarial behaviors, providing valuable insights for security practitioners to respond to evolving threats. Recent advancements of Large Language Models (LLMs) have demonstrated significant potential in various cybersecurity applications, including CTI report understanding and attack knowledge graph construction. While previous works have proposed benchmarks that focus on the CTI extraction ability of LLMs, the sequential characteristic of adversarial behaviors within CTI reports remains largely unexplored, which holds considerable significance in developing a comprehensive understanding of how adversaries operate. To address this gap, we introduce AttackSeqBench, a benchmark tailored to systematically evaluate LLMs' capability to understand and reason attack sequences in CTI reports. Our benchmark encompasses three distinct Question Answering (QA) tasks, each task focuses on the varying granularity in adversarial behavior. To alleviate the laborious effort of QA construction, we carefully design an automated dataset construction pipeline to create scalable and well-formulated QA datasets based on real-world CTI reports. To ensure the quality of our dataset, we adopt a hybrid approach of combining human evaluation and systematic evaluation metrics. We conduct extensive experiments and analysis with both fast-thinking and slow-thinking LLMs, while highlighting their strengths and limitations in analyzing the sequential patterns in cyber attacks. The overarching goal of this work is to provide a benchmark that advances LLM-driven CTI report understanding and fosters its application in real-world cybersecurity operations. Our dataset and code are available at https://github.com/Javiery3889/AttackSeqBench .
Headache to Overstock? Promoting Long-tail Items through Debiased Product Bundling
Nov 28, 2024



Product bundling aims to organize a set of thematically related items into a combined bundle for shipment facilitation and item promotion. To increase the exposure of fresh or overstocked products, sellers typically bundle these items with popular products for inventory clearance. This specific task can be formulated as a long-tail product bundling scenario, which leverages the user-item interactions to define the popularity of each item. The inherent popularity bias in the pre-extracted user feedback features and the insufficient utilization of other popularity-independent knowledge may force the conventional bundling methods to find more popular items, thereby struggling with this long-tail bundling scenario. Through intuitive and empirical analysis, we navigate the core solution for this challenge, which is maximally mining the popularity-free features and effectively incorporating them into the bundling process. To achieve this, we propose a Distilled Modality-Oriented Knowledge Transfer framework (DieT) to effectively counter the popularity bias misintroduced by the user feedback features and adhere to the original intent behind the real-world bundling behaviors. Specifically, DieT first proposes the Popularity-free Collaborative Distribution Modeling module (PCD) to capture the popularity-independent information from the bundle-item view, which is proven most effective in the long-tail bundling scenario to enable the directional information transfer. With the tailored Unbiased Bundle-aware Knowledge Transferring module (UBT), DieT can highlight the significance of popularity-free features while mitigating the negative effects of user feedback features in the long-tail scenario via the knowledge distillation paradigm. Extensive experiments on two real-world datasets demonstrate the superiority of DieT over a list of SOTA methods in the long-tail bundling scenario.