 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of large language models on peer review opinions from a fine-grained perspective: Evidence from top conference proceedings in AI
Apr 21, 2026With the rapid advancement of Large Language Models (LLMs), the academic community has faced unprecedented disruptions, particularly in the realm of academic communication. The primary function of peer review is improving the quality of academic manuscripts, such as clarity, originality and other evaluation aspects. Although prior studies suggest that LLMs are beginning to influence peer review, it remains unclear whether they are altering its core evaluative functions. Moreover, the extent to which LLMs affect the linguistic form, evaluative focus, and recommendation-related signals of peer-review reports has yet to be systematically examined. In this study, we examine the changes in peer review reports for academic articles following the emergence of LLMs, emphasizing variations at fine-grained level. Specifically, we investigate linguistic features such as the length and complexity of words and sentences in review comments, while also automatically annotating the evaluation aspects of individual review sentences. We also use a maximum likelihood estimation method, previously established, to identify review reports that potentially have modified or generated by LLMs. Finally, we assess the impact of evaluation aspects mentioned in LLM-assisted review reports on the informativeness of recommendation for paper decision-making. The results indicate that following the emergence of LLMs, peer review texts have become longer and more fluent, with increased emphasis on summaries and surface-level clarity, as well as more standardized linguistic patterns, particularly reviewers with lower confidence score. At the same time, attention to deeper evaluative dimensions, such as originality, replicability, and nuanced critical reasoning, has declined.
Beyond Single-Dimension Novelty: How Combinations of Theory, Method, and Results-based Novelty Shape Scientific Impact
Apr 14, 2026Scientific novelty drives advances at the research frontier, yet it is also associated with heightened uncertainty and potential resistance from incumbent paradigms, leading to complex patterns of scientific impact. Prior studies have primarily ex-amined the relationship between a single dimension of novelty -- such as theoreti-cal, methodological, or results-based novelty -- and scientific impact. However, because scientific novelty is inherently multidimensional, focusing on isolated dimensions may obscure how different types of novelty jointly shape impact. Consequently, we know little about how combinations of novelty types influence scientific impact. To this end, we draw on a dataset of 15,322 articles published in Nature Communications. Using the DeepSeek-V3 model, we classify articles into three novelty dimensions based on the content of their Introduction sections: theoretical novelty, methodological novelty, and results-based novelty. These dimensions may coexist within the same article, forming distinct novelty configura-tions. Scientific impact is measured using five-year citation counts and indicators of whether an article belongs to the top 1% or top 10% highly cited papers. Descriptive results indicate that results-based novelty alone and the simultaneous presence of all three novelty types are the dominant configurations in the sample. Regression results further show that articles with results-based novelty only re-ceive significantly more citations and are more likely to rank among the top 1% and top 10% highly cited papers than articles exhibiting all three novelty types. These findings advance our understanding of how multidimensional novelty configurations shape knowledge diffusion.
Multimodal Protein Language Models for Enzyme Kinetic Parameters: From Substrate Recognition to Conformational Adaptation
Mar 13, 2026Predicting enzyme kinetic parameters quantifies how efficiently an enzyme catalyzes a specific substrate under defined biochemical conditions. Canonical parameters such as the turnover number ($k_\text{cat}$), Michaelis constant ($K_\text{m}$), and inhibition constant ($K_\text{i}$) depend jointly on the enzyme sequence, the substrate chemistry, and the conformational adaptation of the active site during binding. Many learning pipelines simplify this process to a static compatibility problem between the enzyme and substrate, fusing their representations through shallow operations and regressing a single value. Such formulations overlook the staged nature of catalysis, which involves both substrate recognition and conformational adaptation. In this regard, we reformulate kinetic prediction as a staged multimodal conditional modeling problem and introduce the Enzyme-Reaction Bridging Adapter (ERBA), which injects cross-modal information via fine-tuning into Protein Language Models (PLMs) while preserving their biochemical priors. ERBA performs conditioning in two stages: Molecular Recognition Cross-Attention (MRCA) first injects substrate information into the enzyme representation to capture specificity; Geometry-aware Mixture-of-Experts (G-MoE) then integrates active-site structure and routes samples to pocket-specialized experts to reflect induced fit. To maintain semantic fidelity, Enzyme-Substrate Distribution Alignment (ESDA) enforces distributional consistency within the PLM manifold in a reproducing kernel Hilbert space. Experiments across three kinetic endpoints and multiple PLM backbones, ERBA delivers consistent gains and stronger out-of-distribution performance compared with sequence-only and shallow-fusion baselines, offering a biologically grounded route to scalable kinetic prediction and a foundation for adding cofactors, mutations, and time-resolved structural cues.
SurveyGen: Quality-Aware Scientific Survey Generation with Large Language Models
Aug 25, 2025Automatic survey generation has emerged as a key task in scientific document processing. While large language models (LLMs) have shown promise in generating survey texts, the lack of standardized evaluation datasets critically hampers rigorous assessment of their performance against human-written surveys. In this work, we present SurveyGen, a large-scale dataset comprising over 4,200 human-written surveys across diverse scientific domains, along with 242,143 cited references and extensive quality-related metadata for both the surveys and the cited papers. Leveraging this resource, we build QUAL-SG, a novel quality-aware framework for survey generation that enhances the standard Retrieval-Augmented Generation (RAG) pipeline by incorporating quality-aware indicators into literature retrieval to assess and select higher-quality source papers. Using this dataset and framework, we systematically evaluate state-of-the-art LLMs under varying levels of human involvement - from fully automatic generation to human-guided writing. Experimental results and human evaluations show that while semi-automatic pipelines can achieve partially competitive outcomes, fully automatic survey generation still suffers from low citation quality and limited critical analysis.
SC4ANM: Identifying Optimal Section Combinations for Automated Novelty Prediction in Academic Papers
May 22, 2025Novelty is a core component of academic papers, and there are multiple perspectives on the assessment of novelty. Existing methods often focus on word or entity combinations, which provide limited insights. The content related to a paper's novelty is typically distributed across different core sections, e.g., Introduction, Methodology and Results. Therefore, exploring the optimal combination of sections for evaluating the novelty of a paper is important for advancing automated novelty assessment. In this paper, we utilize different combinations of sections from academic papers as inputs to drive language models to predict novelty scores. We then analyze the results to determine the optimal section combinations for novelty score prediction. We first employ natural language processing techniques to identify the sectional structure of academic papers, categorizing them into introduction, methods, results, and discussion (IMRaD). Subsequently, we used different combinations of these sections (e.g., introduction and methods) as inputs for pretrained language models (PLMs) and large language models (LLMs), employing novelty scores provided by human expert reviewers as ground truth labels to obtain prediction results. The results indicate that using introduction, results and discussion is most appropriate for assessing the novelty of a paper, while the use of the entire text does not yield significant results. Furthermore, based on the results of the PLMs and LLMs, the introduction and results appear to be the most important section for the task of novelty score prediction. The code and dataset for this paper can be accessed at https://github.com/njust-winchy/SC4ANM.
Enhancing Abstractive Summarization of Scientific Papers Using Structure Information
May 20, 2025
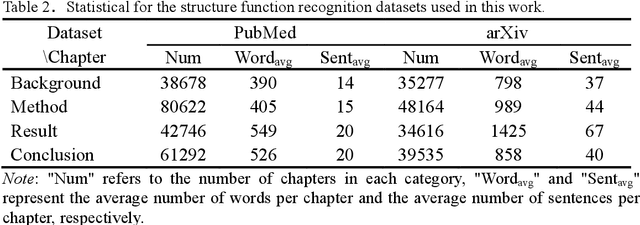
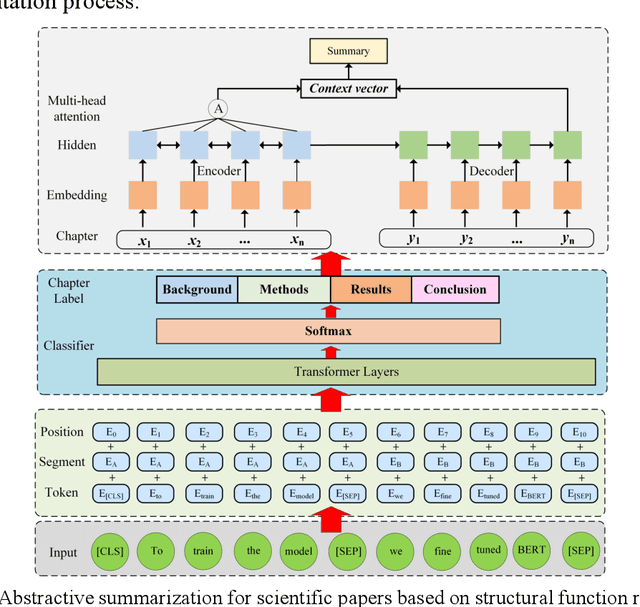

Abstractive summarization of scientific papers has always been a research focus, yet existing methods face two main challenges. First, most summarization models rely on Encoder-Decoder architectures that treat papers as sequences of words, thus fail to fully capture the structured information inherent in scientific papers. Second, existing research often use keyword mapping or feature engineering to identify the structural information, but these methods struggle with the structural flexibility of scientific papers and lack robustness across different disciplines. To address these challenges, we propose a two-stage abstractive summarization framework that leverages automatic recognition of structural functions within scientific papers. In the first stage, we standardize chapter titles from numerous scientific papers and construct a large-scale dataset for structural function recognition. A classifier is then trained to automatically identify the key structural components (e.g., Background, Methods, Results, Discussion), which provides a foundation for generating more balanced summaries. In the second stage, we employ Longformer to capture rich contextual relationships across sections and generating context-aware summaries. Experiments conducted on two domain-specific scientific paper summarization datasets demonstrate that our method outperforms advanced baselines, and generates more comprehensive summaries. The code and dataset can be accessed at https://github.com/tongbao96/code-for-SFR-AS.
Examining Linguistic Shifts in Academic Writing Before and After the Launch of ChatGPT: A Study on Preprint Papers
May 18, 2025Large Language Models (LLMs), such as ChatGPT, have prompted academic concerns about their impact on academic writing. Existing studies have primarily examined LLM usage in academic writing through quantitative approaches, such as word frequency statistics and probability-based analyses. However, few have systematically examined the potential impact of LLMs on the linguistic characteristics of academic writing. To address this gap, we conducted a large-scale analysis across 823,798 abstracts published in last decade from arXiv dataset. Through the linguistic analysis of features such as the frequency of LLM-preferred words, lexical complexity, syntactic complexity, cohesion, readability and sentiment, the results indicate a significant increase in the proportion of LLM-preferred words in abstracts, revealing the widespread influence of LLMs on academic writing. Additionally, we observed an increase in lexical complexity and sentiment in the abstracts, but a decrease in syntactic complexity, suggesting that LLMs introduce more new vocabulary and simplify sentence structure. However, the significant decrease in cohesion and readability indicates that abstracts have fewer connecting words and are becoming more difficult to read. Moreover, our analysis reveals that scholars with weaker English proficiency were more likely to use the LLMs for academic writing, and focused on improving the overall logic and fluency of the abstracts. Finally, at discipline level, we found that scholars in Computer Science showed more pronounced changes in writing style, while the changes in Mathematics were minimal.
Low Complexity Detection of Spatial Modulation Aided OTFS in Doubly-Selective Channels
May 17, 2023A spatial modulation-aided orthogonal time frequency space (SM-OTFS) scheme is proposed for high-Doppler scenarios, which relies on a low-complexity distance-based detection algorithm. We first derive the delay-Doppler (DD) domain input-output relationship of our SM-OTFS system by exploiting an SM mapper, followed by characterizing the doubly-selective channels considered. Then we propose a distance-based ordering subspace check detector (DOSCD) exploiting the \emph{a priori} information of the transmit symbol vector. Moreover, we derive the discrete-input continuous-output memoryless channel (DCMC) capacity of the system. Finally, our simulation results demonstrate that the proposed SM-OTFS system outperforms the conventional single-input-multiple-output (SIMO)-OTFS system, and that the DOSCD conceived is capable of striking an attractive bit error ratio (BER) vs. complexity trade-off.