 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverlap-Adaptive Hybrid Speaker Diarization and ASR-Aware Observation Addition for MISP 2025 Challenge
May 28, 2025This paper presents the system developed to address the MISP 2025 Challenge. For the diarization system, we proposed a hybrid approach combining a WavLM end-to-end segmentation method with a traditional multi-module clustering technique to adaptively select the appropriate model for handling varying degrees of overlapping speech. For the automatic speech recognition (ASR) system, we proposed an ASR-aware observation addition method that compensates for the performance limitations of Guided Source Separation (GSS) under low signal-to-noise ratio conditions. Finally, we integrated the speaker diarization and ASR systems in a cascaded architecture to address Track 3. Our system achieved character error rates (CER) of 9.48% on Track 2 and concatenated minimum permutation character error rate (cpCER) of 11.56% on Track 3, ultimately securing first place in both tracks and thereby demonstrating the effectiveness of the proposed methods in real-world meeting scenarios.
TFCN: Temporal-Frequential Convolutional Network for Single-Channel Speech Enhancement
Jan 03, 2022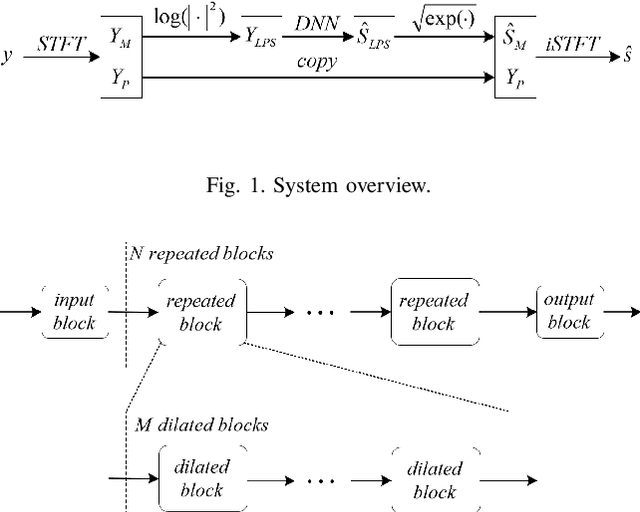
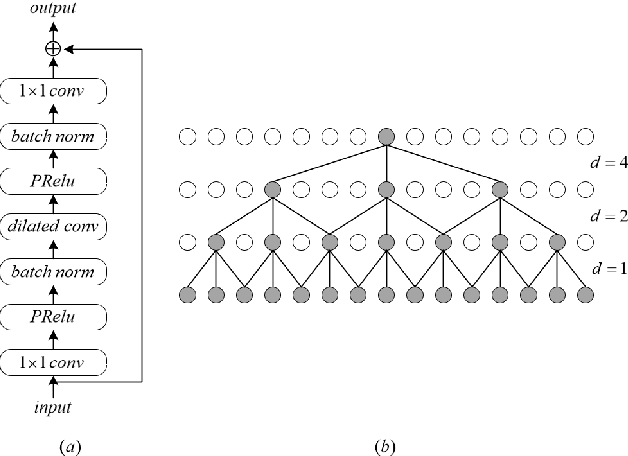
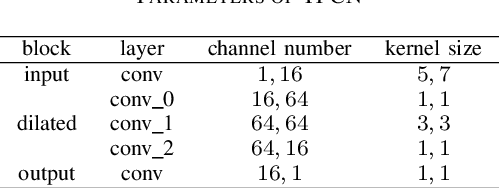
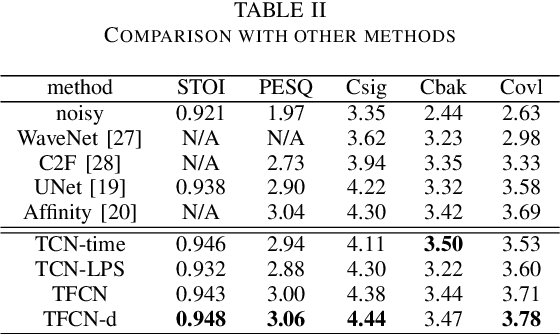
Deep learning based single-channel speech enhancement tries to train a neural network model for the prediction of clean speech signal. There are a variety of popular network structures for single-channel speech enhancement, such as TCNN, UNet, WaveNet, etc. However, these structures usually contain millions of parameters, which is an obstacle for mobile applications. In this work, we proposed a light weight neural network for speech enhancement named TFCN. It is a temporal-frequential convolutional network constructed of dilated convolutions and depth-separable convolutions. We evaluate the performance of TFCN in terms of Short-Time Objective Intelligibility (STOI), perceptual evaluation of speech quality (PESQ) and a series of composite metrics named Csig, Cbak and Covl. Experimental results show that compared with TCN and several other state-of-the-art algorithms, the proposed structure achieves a comparable performance with only 93,000 parameters. Further improvement can be achieved at the cost of more parameters, by introducing dense connections and depth-separable convolutions with normal ones. Experiments also show that the proposed structure can work well both in causal and non-causal situations.