 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Autonomous Long-Horizon Engineering for ML Research
Apr 14, 2026Autonomous AI research has advanced rapidly, but long-horizon ML research engineering remains difficult: agents must sustain coherent progress across task comprehension, environment setup, implementation, experimentation, and debugging over hours or days. We introduce AiScientist, a system for autonomous long-horizon engineering for ML research built on a simple principle: strong long-horizon performance requires both structured orchestration and durable state continuity. To this end, AiScientist combines hierarchical orchestration with a permission-scoped File-as-Bus workspace: a top-level Orchestrator maintains stage-level control through concise summaries and a workspace map, while specialized agents repeatedly re-ground on durable artifacts such as analyses, plans, code, and experimental evidence rather than relying primarily on conversational handoffs, yielding thin control over thick state. Across two complementary benchmarks, AiScientist improves PaperBench score by 10.54 points on average over the best matched baseline and achieves 81.82 Any Medal% on MLE-Bench Lite. Ablation studies further show that File-as-Bus protocol is a key driver of performance, reducing PaperBench by 6.41 points and MLE-Bench Lite by 31.82 points when removed. These results suggest that long-horizon ML research engineering is a systems problem of coordinating specialized work over durable project state, rather than a purely local reasoning problem.
Lang2Str: Two-Stage Crystal Structure Generation with LLMs and Continuous Flow Models
Mar 04, 2026Generative models hold great promise for accelerating material discovery but are often limited by their inflexible single-stage generative process in designing valid and diverse materials. To address this, we propose a two-stage generative framework, Lang2Str, that combines the strengths of large language models (LLMs) and flow-based models for flexible and precise material generation. Our method frames the generative process as a conditional generative task, where an LLM provides high-level conditions by generating descriptions of material unit cells' geometric layouts and properties. These descriptions, informed by the LLM's extensive background knowledge, ensure reasonable structure designs. A conditioned flow model then decodes these textual conditions into precise continuous coordinates and unit cell parameters. This staged approach combines the structured reasoning of LLMs and the distribution modeling capabilities of flow models. Experimental results show that our method achieves competitive performance on \textit{ab initio} material generation and crystal structure prediction tasks, with generated structures exhibiting closer alignment to ground truth in both geometry and energy levels, surpassing state-of-the-art models. The flexibility and modularity of our framework further enable fine-grained control over the generation process, potentially leading to more efficient and customizable material design.
BeyondSWE: Can Current Code Agent Survive Beyond Single-Repo Bug Fixing?
Mar 03, 2026Current benchmarks for code agents primarily assess narrow, repository-specific fixes, overlooking critical real-world challenges such as cross-repository reasoning, domain-specialized problem solving, dependency-driven migration, and full-repository generation. To address this gap, we introduce BeyondSWE, a comprehensive benchmark that broadens existing evaluations along two axes - resolution scope and knowledge scope - using 500 real-world instances across four distinct settings. Experimental results reveal a significant capability gap: even frontier models plateau below 45% success, and no single model performs consistently across task types. To systematically investigate the role of external knowledge, we develop SearchSWE, a framework that integrates deep search with coding abilities. Our experiments show that search augmentation yields inconsistent gains and can in some cases degrade performance, highlighting the difficulty of emulating developer-like workflows that interleave search and reasoning during coding tasks. This work offers both a realistic, challenging evaluation benchmark and a flexible framework to advance research toward more capable code agents.
RubricHub: A Comprehensive and Highly Discriminative Rubric Dataset via Automated Coarse-to-Fine Generation
Jan 13, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has driven substantial progress in reasoning-intensive domains like mathematics. However, optimizing open-ended generation remains challenging due to the lack of ground truth. While rubric-based evaluation offers a structured proxy for verification, existing methods suffer from scalability bottlenecks and coarse criteria, resulting in a supervision ceiling effect. To address this, we propose an automated Coarse-to-Fine Rubric Generation framework. By synergizing principle-guided synthesis, multi-model aggregation, and difficulty evolution, our approach produces comprehensive and highly discriminative criteria capable of capturing the subtle nuances. Based on this framework, we introduce RubricHub, a large-scale ($\sim$110k) and multi-domain dataset. We validate its utility through a two-stage post-training pipeline comprising Rubric-based Rejection Sampling Fine-Tuning (RuFT) and Reinforcement Learning (RuRL). Experimental results demonstrate that RubricHub unlocks significant performance gains: our post-trained Qwen3-14B achieves state-of-the-art (SOTA) results on HealthBench (69.3), surpassing proprietary frontier models such as GPT-5. The code and data will be released soon.
Evaluating Frontier LLMs on PhD-Level Mathematical Reasoning: A Benchmark on a Textbook in Theoretical Computer Science about Randomized Algorithms
Dec 16, 2025The rapid advancement of large language models (LLMs) has led to significant breakthroughs in automated mathematical reasoning and scientific discovery. Georgiev, G${ó}$mez-Serrano, Tao, and Wagner [GGSTW+25] demonstrate that AI systems can explore new constructions and improve existing bounds, illustrating the growing potential of LLMs to accelerate mathematical discovery. Similarly, Bubeck et al. [BCE+25] show that GPT-5 can meaningfully contribute to scientific workflows, from proposing hypotheses to generating proofs and analyses. Despite these advances, a rigorous evaluation of these models on canonical, graduate-level mathematical theory remains necessary to understand their baseline reasoning capabilities. In this paper, we present a comprehensive benchmark of four frontier models: GPT-5-Thinking, Gemini-3-Pro, Claude-Sonnet-4.5-Thinking, and Grok-4 against the classic curriculum of Randomized Algorithms by Motwani and Raghavan [MR95]. We tasked each model with generating formal LaTeX proofs for a series of lemmas and exercises spanning the textbook. We find that while the top-tier models (Gemini, and Claude) achieve a high accuracy rate (approx. 66%), demonstrating a robust grasp of probabilistic method and formal logic, other models lag significantly in consistency (approx. 40%). We provide a qualitative analysis of the generated proofs, highlighting differences in conciseness, hallucination rates, and logical structure. Our results suggest that while frontier models have reached a threshold of proficiency suitable for graduate-level pedagogical assistance and formalization, significant variance exists in their reliability for rigorous mathematical derivation. The code and the full set of LLM-generated responses are open-sourced and publicly available at https://github.com/magiclinux/math_benchmark_probability.
Decoding the Ear: A Framework for Objectifying Expressiveness from Human Preference Through Efficient Alignment
Oct 23, 2025Recent speech-to-speech (S2S) models generate intelligible speech but still lack natural expressiveness, largely due to the absence of a reliable evaluation metric. Existing approaches, such as subjective MOS ratings, low-level acoustic features, and emotion recognition are costly, limited, or incomplete. To address this, we present DeEAR (Decoding the Expressive Preference of eAR), a framework that converts human preference for speech expressiveness into an objective score. Grounded in phonetics and psychology, DeEAR evaluates speech across three dimensions: Emotion, Prosody, and Spontaneity, achieving strong alignment with human perception (Spearman's Rank Correlation Coefficient, SRCC = 0.86) using fewer than 500 annotated samples. Beyond reliable scoring, DeEAR enables fair benchmarking and targeted data curation. It not only distinguishes expressiveness gaps across S2S models but also selects 14K expressive utterances to form ExpressiveSpeech, which improves the expressive score (from 2.0 to 23.4 on a 100-point scale) of S2S models. Demos and codes are available at https://github.com/FreedomIntelligence/ExpressiveSpeech
Breaking the Exploration Bottleneck: Rubric-Scaffolded Reinforcement Learning for General LLM Reasoning
Aug 23, 2025Recent advances in Large Language Models (LLMs) have underscored the potential of Reinforcement Learning (RL) to facilitate the emergence of reasoning capabilities. Despite the encouraging results, a fundamental dilemma persists as RL improvement relies on learning from high-quality samples, yet the exploration for such samples remains bounded by the inherent limitations of LLMs. This, in effect, creates an undesirable cycle in which what cannot be explored cannot be learned. In this work, we propose Rubric-Scaffolded Reinforcement Learning (RuscaRL), a novel instructional scaffolding framework designed to break the exploration bottleneck for general LLM reasoning. Specifically, RuscaRL introduces checklist-style rubrics as (1) explicit scaffolding for exploration during rollout generation, where different rubrics are provided as external guidance within task instructions to steer diverse high-quality responses. This guidance is gradually decayed over time, encouraging the model to internalize the underlying reasoning patterns; (2) verifiable rewards for exploitation during model training, where we can obtain robust LLM-as-a-Judge scores using rubrics as references, enabling effective RL on general reasoning tasks. Extensive experiments demonstrate the superiority of the proposed RuscaRL across various benchmarks, effectively expanding reasoning boundaries under the best-of-N evaluation. Notably, RuscaRL significantly boosts Qwen-2.5-7B-Instruct from 23.6 to 50.3 on HealthBench-500, surpassing GPT-4.1. Furthermore, our fine-tuned variant on Qwen3-30B-A3B-Instruct achieves 61.1 on HealthBench-500, outperforming leading LLMs including OpenAI-o3.
One Object, Multiple Lies: A Benchmark for Cross-task Adversarial Attack on Unified Vision-Language Models
Jul 10, 2025Unified vision-language models(VLMs) have recently shown remarkable progress, enabling a single model to flexibly address diverse tasks through different instructions within a shared computational architecture. This instruction-based control mechanism creates unique security challenges, as adversarial inputs must remain effective across multiple task instructions that may be unpredictably applied to process the same malicious content. In this paper, we introduce CrossVLAD, a new benchmark dataset carefully curated from MSCOCO with GPT-4-assisted annotations for systematically evaluating cross-task adversarial attacks on unified VLMs. CrossVLAD centers on the object-change objective-consistently manipulating a target object's classification across four downstream tasks-and proposes a novel success rate metric that measures simultaneous misclassification across all tasks, providing a rigorous evaluation of adversarial transferability. To tackle this challenge, we present CRAFT (Cross-task Region-based Attack Framework with Token-alignment), an efficient region-centric attack method. Extensive experiments on Florence-2 and other popular unified VLMs demonstrate that our method outperforms existing approaches in both overall cross-task attack performance and targeted object-change success rates, highlighting its effectiveness in adversarially influencing unified VLMs across diverse tasks.
TRAIL: Transferable Robust Adversarial Images via Latent diffusion
May 22, 2025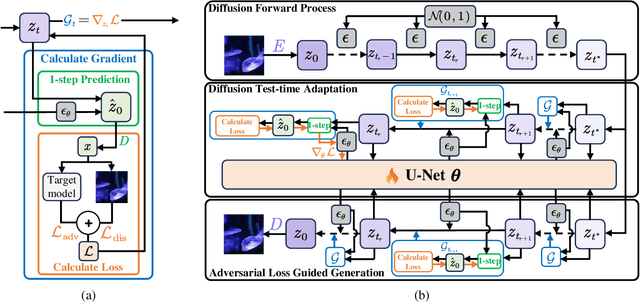
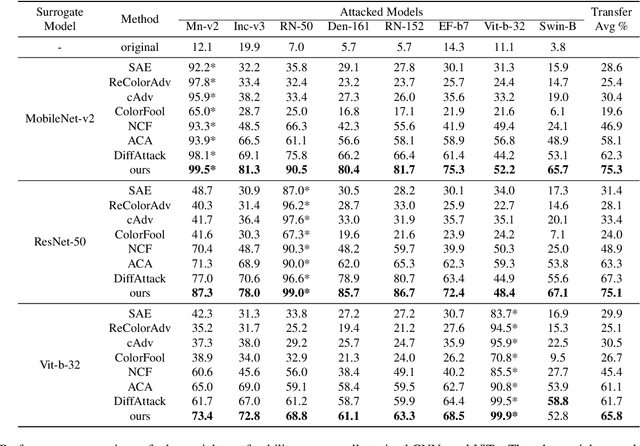
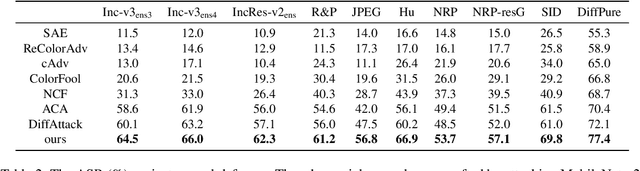

Adversarial attacks exploiting unrestricted natural perturbations present severe security risks to deep learning systems, yet their transferability across models remains limited due to distribution mismatches between generated adversarial features and real-world data. While recent works utilize pre-trained diffusion models as adversarial priors, they still encounter challenges due to the distribution shift between the distribution of ideal adversarial samples and the natural image distribution learned by the diffusion model. To address the challenge, we propose Transferable Robust Adversarial Images via Latent Diffusion (TRAIL), a test-time adaptation framework that enables the model to generate images from a distribution of images with adversarial features and closely resembles the target images. To mitigate the distribution shift, during attacks, TRAIL updates the diffusion U-Net's weights by combining adversarial objectives (to mislead victim models) and perceptual constraints (to preserve image realism). The adapted model then generates adversarial samples through iterative noise injection and denoising guided by these objectives. Experiments demonstrate that TRAIL significantly outperforms state-of-the-art methods in cross-model attack transferability, validating that distribution-aligned adversarial feature synthesis is critical for practical black-box attacks.
T2VTextBench: A Human Evaluation Benchmark for Textual Control in Video Generation Models
May 08, 2025Thanks to recent advancements in scalable deep architectures and large-scale pretraining, text-to-video generation has achieved unprecedented capabilities in producing high-fidelity, instruction-following content across a wide range of styles, enabling applications in advertising, entertainment, and education. However, these models' ability to render precise on-screen text, such as captions or mathematical formulas, remains largely untested, posing significant challenges for applications requiring exact textual accuracy. In this work, we introduce T2VTextBench, the first human-evaluation benchmark dedicated to evaluating on-screen text fidelity and temporal consistency in text-to-video models. Our suite of prompts integrates complex text strings with dynamic scene changes, testing each model's ability to maintain detailed instructions across frames. We evaluate ten state-of-the-art systems, ranging from open-source solutions to commercial offerings, and find that most struggle to generate legible, consistent text. These results highlight a critical gap in current video generators and provide a clear direction for future research aimed at enhancing textual manipulation in video synthesis.