 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBranchNorm: Robustly Scaling Extremely Deep Transformers
May 04, 2023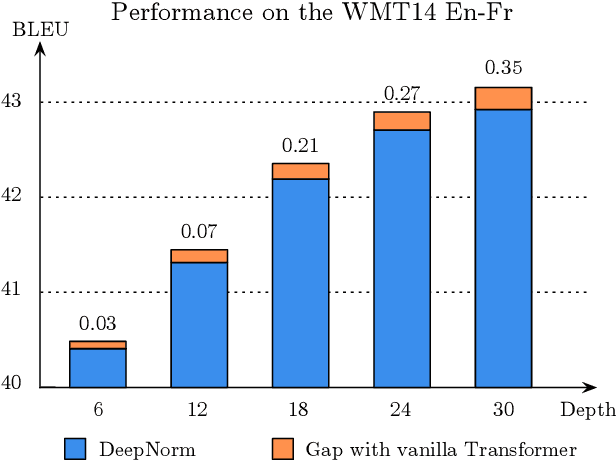


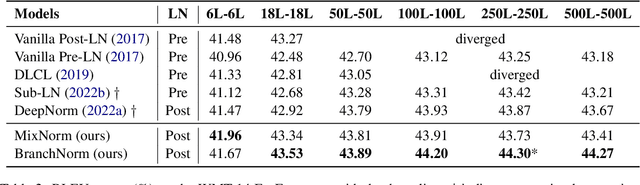
Recently, DeepNorm scales Transformers into extremely deep (i.e., 1000 layers) and reveals the promising potential of deep scaling. To stabilize the training of deep models, DeepNorm (Wang et al., 2022) attempts to constrain the model update to a constant value. Although applying such a constraint can benefit the early stage of model training, it may lead to undertrained models during the whole training procedure. In this paper, we propose BranchNorm, which dynamically rescales the non-residual branch of Transformer in accordance with the training period. BranchNorm not only theoretically stabilizes the training with smooth gradient norms at the early stage, but also encourages better convergence in the subsequent training stage. Experiment results on multiple translation tasks demonstrate that BranchNorm achieves a better trade-off between training stability and converge performance.
Unified Model Learning for Various Neural Machine Translation
May 04, 2023Existing neural machine translation (NMT) studies mainly focus on developing dataset-specific models based on data from different tasks (e.g., document translation and chat translation). Although the dataset-specific models have achieved impressive performance, it is cumbersome as each dataset demands a model to be designed, trained, and stored. In this work, we aim to unify these translation tasks into a more general setting. Specifically, we propose a ``versatile'' model, i.e., the Unified Model Learning for NMT (UMLNMT) that works with data from different tasks, and can translate well in multiple settings simultaneously, and theoretically it can be as many as possible. Through unified learning, UMLNMT is able to jointly train across multiple tasks, implementing intelligent on-demand translation. On seven widely-used translation tasks, including sentence translation, document translation, and chat translation, our UMLNMT results in substantial improvements over dataset-specific models with significantly reduced model deployment costs. Furthermore, UMLNMT can achieve competitive or better performance than state-of-the-art dataset-specific methods. Human evaluation and in-depth analysis also demonstrate the superiority of our approach on generating diverse and high-quality translations. Additionally, we provide a new genre translation dataset about famous aphorisms with 186k Chinese->English sentence pairs.
Learning Accurate Performance Predictors for Ultrafast Automated Model Compression
Apr 13, 2023In this paper, we propose an ultrafast automated model compression framework called SeerNet for flexible network deployment. Conventional non-differen-tiable methods discretely search the desirable compression policy based on the accuracy from exhaustively trained lightweight models, and existing differentiable methods optimize an extremely large supernet to obtain the required compressed model for deployment. They both cause heavy computational cost due to the complex compression policy search and evaluation process. On the contrary, we obtain the optimal efficient networks by directly optimizing the compression policy with an accurate performance predictor, where the ultrafast automated model compression for various computational cost constraint is achieved without complex compression policy search and evaluation. Specifically, we first train the performance predictor based on the accuracy from uncertain compression policies actively selected by efficient evolutionary search, so that informative supervision is provided to learn the accurate performance predictor with acceptable cost. Then we leverage the gradient that maximizes the predicted performance under the barrier complexity constraint for ultrafast acquisition of the desirable compression policy, where adaptive update stepsizes with momentum are employed to enhance optimality of the acquired pruning and quantization strategy. Compared with the state-of-the-art automated model compression methods, experimental results on image classification and object detection show that our method achieves competitive accuracy-complexity trade-offs with significant reduction of the search cost.
Triple Sequence Learning for Cross-domain Recommendation
Apr 11, 2023Cross-domain recommendation (CDR) aims to leverage the users' behaviors in both source and target domains to improve the target domain's performance. Conventional CDR methods typically explore the dual relations between the source and target domains' behavior sequences. However, they ignore modeling the third sequence of mixed behaviors that naturally reflects the user's global preference. To address this issue, we present a novel and model-agnostic Triple sequence learning for cross-domain recommendation (Tri-CDR) framework to jointly model the source, target, and mixed behavior sequences in CDR. Specifically, Tri-CDR independently models the hidden user representations for the source, target, and mixed behavior sequences, and proposes a triple cross-domain attention (TCA) to emphasize the informative knowledge related to both user's target-domain preference and global interests in three sequences. To comprehensively learn the triple correlations, we design a novel triple contrastive learning (TCL) that jointly considers coarse-grained similarities and fine-grained distinctions among three sequences, ensuring the alignment while preserving the information diversity in multi-domain. We conduct extensive experiments and analyses on two real-world datasets with four domains. The significant improvements of Tri-CDR with different sequential encoders on all datasets verify the effectiveness and universality. The source code will be released in the future.
Binarizing Sparse Convolutional Networks for Efficient Point Cloud Analysis
Mar 27, 2023In this paper, we propose binary sparse convolutional networks called BSC-Net for efficient point cloud analysis. We empirically observe that sparse convolution operation causes larger quantization errors than standard convolution. However, conventional network quantization methods directly binarize the weights and activations in sparse convolution, resulting in performance drop due to the significant quantization loss. On the contrary, we search the optimal subset of convolution operation that activates the sparse convolution at various locations for quantization error alleviation, and the performance gap between real-valued and binary sparse convolutional networks is closed without complexity overhead. Specifically, we first present the shifted sparse convolution that fuses the information in the receptive field for the active sites that match the pre-defined positions. Then we employ the differentiable search strategies to discover the optimal opsitions for active site matching in the shifted sparse convolution, and the quantization errors are significantly alleviated for efficient point cloud analysis. For fair evaluation of the proposed method, we empirically select the recently advances that are beneficial for sparse convolution network binarization to construct a strong baseline. The experimental results on Scan-Net and NYU Depth v2 show that our BSC-Net achieves significant improvement upon our srtong baseline and outperforms the state-of-the-art network binarization methods by a remarkable margin without additional computation overhead for binarizing sparse convolutional networks.
Efficient Meshy Neural Fields for Animatable Human Avatars
Mar 23, 2023



Efficiently digitizing high-fidelity animatable human avatars from videos is a challenging and active research topic. Recent volume rendering-based neural representations open a new way for human digitization with their friendly usability and photo-realistic reconstruction quality. However, they are inefficient for long optimization times and slow inference speed; their implicit nature results in entangled geometry, materials, and dynamics of humans, which are hard to edit afterward. Such drawbacks prevent their direct applicability to downstream applications, especially the prominent rasterization-based graphic ones. We present EMA, a method that Efficiently learns Meshy neural fields to reconstruct animatable human Avatars. It jointly optimizes explicit triangular canonical mesh, spatial-varying material, and motion dynamics, via inverse rendering in an end-to-end fashion. Each above component is derived from separate neural fields, relaxing the requirement of a template, or rigging. The mesh representation is highly compatible with the efficient rasterization-based renderer, thus our method only takes about an hour of training and can render in real-time. Moreover, only minutes of optimization is enough for plausible reconstruction results. The disentanglement of meshes enables direct downstream applications. Extensive experiments illustrate the very competitive performance and significant speed boost against previous methods. We also showcase applications including novel pose synthesis, material editing, and relighting. The project page: https://xk-huang.github.io/ema/.
A Comprehensive Capability Analysis of GPT-3 and GPT-3.5 Series Models
Mar 18, 2023



GPT series models, such as GPT-3, CodeX, InstructGPT, ChatGPT, and so on, have gained considerable attention due to their exceptional natural language processing capabilities. However, despite the abundance of research on the difference in capabilities between GPT series models and fine-tuned models, there has been limited attention given to the evolution of GPT series models' capabilities over time. To conduct a comprehensive analysis of the capabilities of GPT series models, we select six representative models, comprising two GPT-3 series models (i.e., davinci and text-davinci-001) and four GPT-3.5 series models (i.e., code-davinci-002, text-davinci-002, text-davinci-003, and gpt-3.5-turbo). We evaluate their performance on nine natural language understanding (NLU) tasks using 21 datasets. In particular, we compare the performance and robustness of different models for each task under zero-shot and few-shot scenarios. Our extensive experiments reveal that the overall ability of GPT series models on NLU tasks does not increase gradually as the models evolve, especially with the introduction of the RLHF training strategy. While this strategy enhances the models' ability to generate human-like responses, it also compromises their ability to solve some tasks. Furthermore, our findings indicate that there is still room for improvement in areas such as model robustness.
SurroundOcc: Multi-Camera 3D Occupancy Prediction for Autonomous Driving
Mar 16, 2023



3D scene understanding plays a vital role in vision-based autonomous driving. While most existing methods focus on 3D object detection, they have difficulty describing real-world objects of arbitrary shapes and infinite classes. Towards a more comprehensive perception of a 3D scene, in this paper, we propose a SurroundOcc method to predict the 3D occupancy with multi-camera images. We first extract multi-scale features for each image and adopt spatial 2D-3D attention to lift them to the 3D volume space. Then we apply 3D convolutions to progressively upsample the volume features and impose supervision on multiple levels. To obtain dense occupancy prediction, we design a pipeline to generate dense occupancy ground truth without expansive occupancy annotations. Specifically, we fuse multi-frame LiDAR scans of dynamic objects and static scenes separately. Then we adopt Poisson Reconstruction to fill the holes and voxelize the mesh to get dense occupancy labels. Extensive experiments on nuScenes and SemanticKITTI datasets demonstrate the superiority of our method. Code and dataset are available at https://github.com/weiyithu/SurroundOcc
Precise Facial Landmark Detection by Reference Heatmap Transformer
Mar 14, 2023



Most facial landmark detection methods predict landmarks by mapping the input facial appearance features to landmark heatmaps and have achieved promising results. However, when the face image is suffering from large poses, heavy occlusions and complicated illuminations, they cannot learn discriminative feature representations and effective facial shape constraints, nor can they accurately predict the value of each element in the landmark heatmap, limiting their detection accuracy. To address this problem, we propose a novel Reference Heatmap Transformer (RHT) by introducing reference heatmap information for more precise facial landmark detection. The proposed RHT consists of a Soft Transformation Module (STM) and a Hard Transformation Module (HTM), which can cooperate with each other to encourage the accurate transformation of the reference heatmap information and facial shape constraints. Then, a Multi-Scale Feature Fusion Module (MSFFM) is proposed to fuse the transformed heatmap features and the semantic features learned from the original face images to enhance feature representations for producing more accurate target heatmaps. To the best of our knowledge, this is the first study to explore how to enhance facial landmark detection by transforming the reference heatmap information. The experimental results from challenging benchmark datasets demonstrate that our proposed method outperforms the state-of-the-art methods in the literature.
HiNet: Novel Multi-Scenario & Multi-Task Learning with Hierarchical Information Extraction
Mar 14, 2023



Multi-scenario & multi-task learning has been widely applied to many recommendation systems in industrial applications, wherein an effective and practical approach is to carry out multi-scenario transfer learning on the basis of the Mixture-of-Expert (MoE) architecture. However, the MoE-based method, which aims to project all information in the same feature space, cannot effectively deal with the complex relationships inherent among various scenarios and tasks, resulting in unsatisfactory performance. To tackle the problem, we propose a Hierarchical information extraction Network (HiNet) for multi-scenario and multi-task recommendation, which achieves hierarchical extraction based on coarse-to-fine knowledge transfer scheme. The multiple extraction layers of the hierarchical network enable the model to enhance the capability of transferring valuable information across scenarios while preserving specific features of scenarios and tasks. Furthermore, a novel scenario-aware attentive network module is proposed to model correlations between scenarios explicitly. Comprehensive experiments conducted on real-world industrial datasets from Meituan Meishi platform demonstrate that HiNet achieves a new state-of-the-art performance and significantly outperforms existing solutions. HiNet is currently fully deployed in two scenarios and has achieved 2.87% and 1.75% order quantity gain respectively.