 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBench2Drive-VL: Benchmarks for Closed-Loop Autonomous Driving with Vision-Language Models
Apr 01, 2026With the rise of vision-language models (VLM), their application for autonomous driving (VLM4AD) has gained significant attention. Meanwhile, in autonomous driving, closed-loop evaluation has become widely recognized as a more reliable validation method than open-loop evaluation, as it can evaluate the performance of the model under cumulative errors and out-of-distribution inputs. However, existing VLM4AD benchmarks evaluate the model`s scene understanding ability under open-loop, i.e., via static question-answer (QA) dataset. This kind of evaluation fails to assess the VLMs performance under out-of-distribution states rarely appeared in the human collected datasets.To this end, we present Bench2Drive-VL, an extension of Bench2Drive that brings closed-loop evaluation to VLM-based driving, which introduces: (1) DriveCommenter, a closed-loop generator that automatically generates diverse, behavior-grounded question-answer pairs for all driving situations in CARLA,including severe off-route and off-road deviations previously unassessable in simulation. (2) A unified protocol and interface that allows modern VLMs to be directly plugged into the Bench2Drive closed-loop environment to compare with traditional agents. (3) A flexible reasoning and control framework, supporting multi-format visual inputs and configurable graph-based chain-of-thought execution. (4) A complete development ecosystem. Together, these components form a comprehensive closed-loop benchmark for VLM4AD. All codes and annotated datasets are open sourced.
Can Users Specify Driving Speed? Bench2Drive-Speed: Benchmark and Baselines for Desired-Speed Conditioned Autonomous Driving
Mar 26, 2026End-to-end autonomous driving (E2E-AD) has achieved remarkable progress. However, one practical and useful function has been long overlooked: users may wish to customize the desired speed of the policy or specify whether to allow the autonomous vehicle to overtake. To bridge this gap, we present Bench2Drive-Speed, a benchmark with metrics, dataset, and baselines for desired-speed conditioned autonomous driving. We introduce explicit inputs of users' desired target-speed and overtake/follow instructions to driving policy models. We design quantitative metrics, including Speed-Adherence Score and Overtake Score, to measure how faithfully policies follow user specifications, while remaining compatible with standard autonomous driving metrics. To enable training of speed-conditioned policies, one approach is to collect expert demonstrations that strictly follow speed requirements, an expensive and unscalable process in the real world. An alternative is to adapt existing regular driving data by treating the speed observed in future frames as the target speed for training. To investigate this, we construct CustomizedSpeedDataset, composed of 2,100 clips annotated with experts demonstrations, enabling systematic investigation of supervision strategies. Our experiments show that, under proper re-annotation, models trained on regular driving data perform comparably to on expert demonstrations, suggesting that speed supervision can be introduced without additional complex real-world data collection. Furthermore, we find that while target-speed following can be achieved without degrading regular driving performance, executing overtaking commands remains challenging due to the inherent difficulty of interactive behaviors. All code, datasets and baselines are available at https://github.com/Thinklab-SJTU/Bench2Drive-Speed
ReSim: Reliable World Simulation for Autonomous Driving
Jun 11, 2025How can we reliably simulate future driving scenarios under a wide range of ego driving behaviors? Recent driving world models, developed exclusively on real-world driving data composed mainly of safe expert trajectories, struggle to follow hazardous or non-expert behaviors, which are rare in such data. This limitation restricts their applicability to tasks such as policy evaluation. In this work, we address this challenge by enriching real-world human demonstrations with diverse non-expert data collected from a driving simulator (e.g., CARLA), and building a controllable world model trained on this heterogeneous corpus. Starting with a video generator featuring a diffusion transformer architecture, we devise several strategies to effectively integrate conditioning signals and improve prediction controllability and fidelity. The resulting model, ReSim, enables Reliable Simulation of diverse open-world driving scenarios under various actions, including hazardous non-expert ones. To close the gap between high-fidelity simulation and applications that require reward signals to judge different actions, we introduce a Video2Reward module that estimates a reward from ReSim's simulated future. Our ReSim paradigm achieves up to 44% higher visual fidelity, improves controllability for both expert and non-expert actions by over 50%, and boosts planning and policy selection performance on NAVSIM by 2% and 25%, respectively.
DriveMoE: Mixture-of-Experts for Vision-Language-Action Model in End-to-End Autonomous Driving
May 22, 2025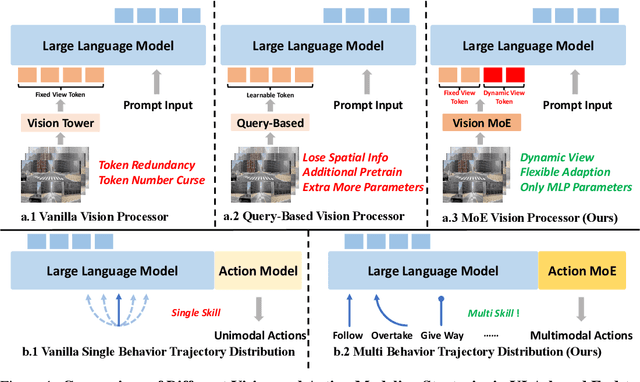
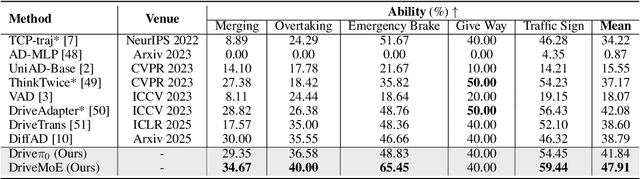
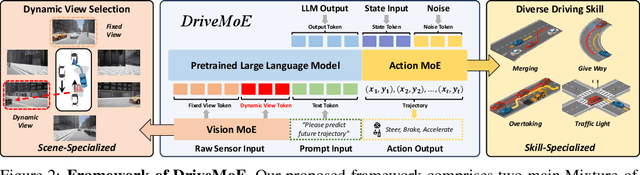
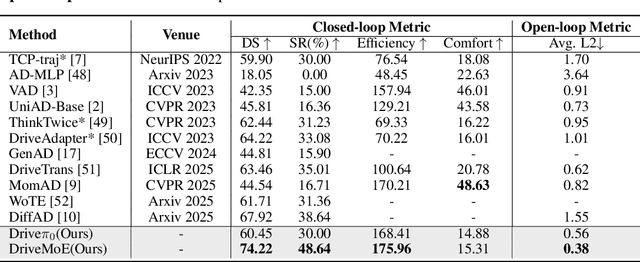
End-to-end autonomous driving (E2E-AD) demands effective processing of multi-view sensory data and robust handling of diverse and complex driving scenarios, particularly rare maneuvers such as aggressive turns. Recent success of Mixture-of-Experts (MoE) architecture in Large Language Models (LLMs) demonstrates that specialization of parameters enables strong scalability. In this work, we propose DriveMoE, a novel MoE-based E2E-AD framework, with a Scene-Specialized Vision MoE and a Skill-Specialized Action MoE. DriveMoE is built upon our $\pi_0$ Vision-Language-Action (VLA) baseline (originally from the embodied AI field), called Drive-$\pi_0$. Specifically, we add Vision MoE to Drive-$\pi_0$ by training a router to select relevant cameras according to the driving context dynamically. This design mirrors human driving cognition, where drivers selectively attend to crucial visual cues rather than exhaustively processing all visual information. In addition, we add Action MoE by training another router to activate specialized expert modules for different driving behaviors. Through explicit behavioral specialization, DriveMoE is able to handle diverse scenarios without suffering from modes averaging like existing models. In Bench2Drive closed-loop evaluation experiments, DriveMoE achieves state-of-the-art (SOTA) performance, demonstrating the effectiveness of combining vision and action MoE in autonomous driving tasks. We will release our code and models of DriveMoE and Drive-$\pi_0$.