 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetroInfer: A Vector-Storage Approach for Scalable Long-Context LLM Inference
May 05, 2025The growing context lengths of large language models (LLMs) pose significant challenges for efficient inference, primarily due to GPU memory and bandwidth constraints. We present RetroInfer, a novel system that reconceptualizes the key-value (KV) cache as a vector storage system which exploits the inherent attention sparsity to accelerate long-context LLM inference. At its core is the wave index, an Attention-aWare VEctor index that enables efficient and accurate retrieval of critical tokens through techniques such as tripartite attention approximation, accuracy-bounded attention estimation, and segmented clustering. Complementing this is the wave buffer, which coordinates KV cache placement and overlaps computation and data transfer across GPU and CPU to sustain high throughput. Unlike prior sparsity-based methods that struggle with token selection and hardware coordination, RetroInfer delivers robust performance without compromising model accuracy. Experiments on long-context benchmarks show up to 4.5X speedup over full attention within GPU memory limits and up to 10.5X over sparse attention baselines when KV cache is extended to CPU memory, all while preserving full-attention-level accuracy.
Modality Selection and Skill Segmentation via Cross-Modality Attention
Apr 20, 2025Incorporating additional sensory modalities such as tactile and audio into foundational robotic models poses significant challenges due to the curse of dimensionality. This work addresses this issue through modality selection. We propose a cross-modality attention (CMA) mechanism to identify and selectively utilize the modalities that are most informative for action generation at each timestep. Furthermore, we extend the application of CMA to segment primitive skills from expert demonstrations and leverage this segmentation to train a hierarchical policy capable of solving long-horizon, contact-rich manipulation tasks.
Towards Scalable and Deep Graph Neural Networks via Noise Masking
Dec 19, 2024



In recent years, Graph Neural Networks (GNNs) have achieved remarkable success in many graph mining tasks. However, scaling them to large graphs is challenging due to the high computational and storage costs of repeated feature propagation and non-linear transformation during training. One commonly employed approach to address this challenge is model-simplification, which only executes the Propagation (P) once in the pre-processing, and Combine (C) these receptive fields in different ways and then feed them into a simple model for better performance. Despite their high predictive performance and scalability, these methods still face two limitations. First, existing approaches mainly focus on exploring different C methods from the model perspective, neglecting the crucial problem of performance degradation with increasing P depth from the data-centric perspective, known as the over-smoothing problem. Second, pre-processing overhead takes up most of the end-to-end processing time, especially for large-scale graphs. To address these limitations, we present random walk with noise masking (RMask), a plug-and-play module compatible with the existing model-simplification works. This module enables the exploration of deeper GNNs while preserving their scalability. Unlike the previous model-simplification works, we focus on continuous P and found that the noise existing inside each P is the cause of the over-smoothing issue, and use the efficient masking mechanism to eliminate them. Experimental results on six real-world datasets demonstrate that model-simplification works equipped with RMask yield superior performance compared to their original version and can make a good trade-off between accuracy and efficiency.
Origin-Destination Demand Prediction: An Urban Radiation and Attraction Perspective
Nov 29, 2024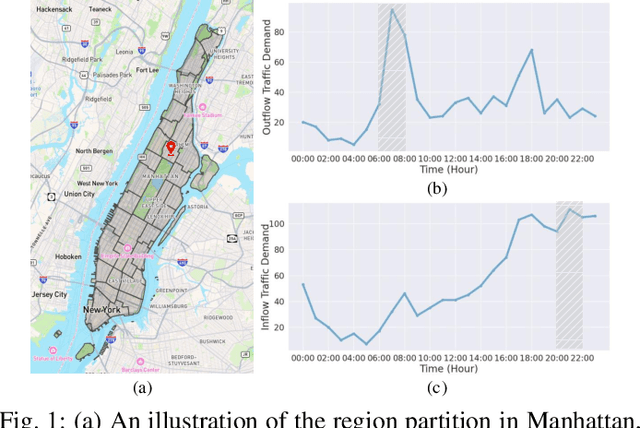
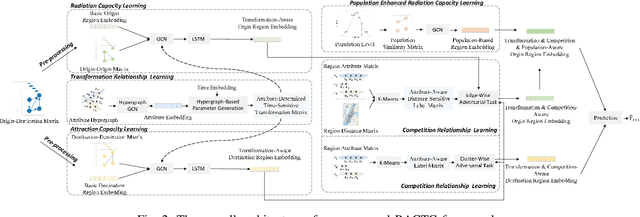
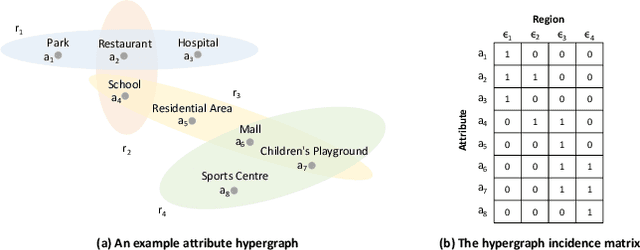
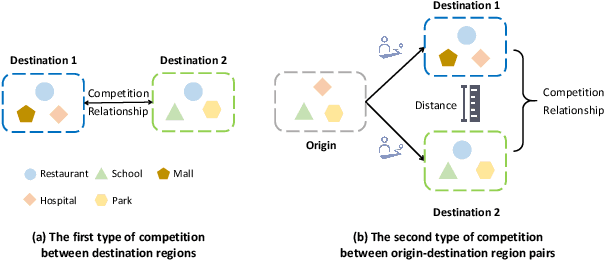
In recent years, origin-destination (OD) demand prediction has gained significant attention for its profound implications in urban development. Existing data-driven deep learning methods primarily focus on the spatial or temporal dependency between regions yet neglecting regions' fundamental functional difference. Though knowledge-driven physical methods have characterised regions' functions by their radiation and attraction capacities, these functions are defined on numerical factors like population without considering regions' intrinsic nominal attributes, e.g., a region is a residential or industrial district. Moreover, the complicated relationships between two types of capacities, e.g., the radiation capacity of a residential district in the morning will be transformed into the attraction capacity in the evening, are totally missing from physical methods. In this paper, we not only generalize the physical radiation and attraction capacities into the deep learning framework with the extended capability to fulfil regions' functions, but also present a new model that captures the relationships between two types of capacities. Specifically, we first model regions' radiation and attraction capacities using a bilateral branch network, each equipped with regions' attribute representations. We then describe the transformation relationship of different capacities of the same region using a hypergraph-based parameter generation method. We finally unveil the competition relationship of different regions with the same attraction capacity through cluster-based adversarial learning. Extensive experiments on two datasets demonstrate the consistent improvements of our method over the state-of-the-art baselines, as well as the good explainability of regions' functions using their nominal attributes.
Can LLMs be Good Graph Judger for Knowledge Graph Construction?
Nov 26, 2024



In real-world scenarios, most of the data obtained from information retrieval (IR) system is unstructured. Converting natural language sentences into structured Knowledge Graphs (KGs) remains a critical challenge. The quality of constructed KGs may also impact the performance of some KG-dependent domains like GraphRAG systems and recommendation systems. Recently, Large Language Models (LLMs) have demonstrated impressive capabilities in addressing a wide range of natural language processing tasks. However, there are still challenges when utilizing LLMs to address the task of generating structured KGs. And we have identified three limitations with respect to existing KG construction methods. (1)There is a large amount of information and excessive noise in real-world documents, which could result in extracting messy information. (2)Native LLMs struggle to effectively extract accuracy knowledge from some domain-specific documents. (3)Hallucinations phenomenon cannot be overlooked when utilizing LLMs directly as an unsupervised method for constructing KGs. In this paper, we propose GraphJudger, a knowledge graph construction framework to address the aforementioned challenges. We introduce three innovative modules in our method, which are entity-centric iterative text denoising, knowledge aware instruction tuning and graph judgement, respectively. We seek to utilize the capacity of LLMs to function as a graph judger, a capability superior to their role only as a predictor for KG construction problems. Experiments conducted on two general text-graph pair datasets and one domain-specific text-graph pair dataset show superior performances compared to baseline methods. The code of our proposed method is available at https://github.com/hhy-huang/GraphJudger.
Retrofitting Temporal Graph Neural Networks with Transformer
Sep 10, 2024



Temporal graph neural networks (TGNNs) outperform regular GNNs by incorporating time information into graph-based operations. However, TGNNs adopt specialized models (e.g., TGN, TGAT, and APAN ) and require tailored training frameworks (e.g., TGL and ETC). In this paper, we propose TF-TGN, which uses Transformer decoder as the backbone model for TGNN to enjoy Transformer's codebase for efficient training. In particular, Transformer achieves tremendous success for language modeling, and thus the community developed high-performance kernels (e.g., flash-attention and memory-efficient attention) and efficient distributed training schemes (e.g., PyTorch FSDP, DeepSpeed, and Megatron-LM). We observe that TGNN resembles language modeling, i.e., the message aggregation operation between chronologically occurring nodes and their temporal neighbors in TGNNs can be structured as sequence modeling. Beside this similarity, we also incorporate a series of algorithm designs including suffix infilling, temporal graph attention with self-loop, and causal masking self-attention to make TF-TGN work. During training, existing systems are slow in transforming the graph topology and conducting graph sampling. As such, we propose methods to parallelize the CSR format conversion and graph sampling. We also adapt Transformer codebase to train TF-TGN efficiently with multiple GPUs. We experiment with 9 graphs and compare with 2 state-of-the-art TGNN training frameworks. The results show that TF-TGN can accelerate training by over 2.20 while providing comparable or even superior accuracy to existing SOTA TGNNs. TF-TGN is available at https://github.com/qianghuangwhu/TF-TGN.
Hound: Hunting Supervision Signals for Few and Zero Shot Node Classification on Text-attributed Graph
Sep 01, 2024



Text-attributed graph (TAG) is an important type of graph structured data with text descriptions for each node. Few- and zero-shot node classification on TAGs have many applications in fields such as academia and social networks. However, the two tasks are challenging due to the lack of supervision signals, and existing methods only use the contrastive loss to align graph-based node embedding and language-based text embedding. In this paper, we propose Hound to improve accuracy by introducing more supervision signals, and the core idea is to go beyond the node-text pairs that come with data. Specifically, we design three augmentation techniques, i.e., node perturbation, text matching, and semantics negation to provide more reference nodes for each text and vice versa. Node perturbation adds/drops edges to produce diversified node embeddings that can be matched with a text. Text matching retrieves texts with similar embeddings to match with a node. Semantics negation uses a negative prompt to construct a negative text with the opposite semantics, which is contrasted with the original node and text. We evaluate Hound on 5 datasets and compare with 13 state-of-the-art baselines. The results show that Hound consistently outperforms all baselines, and its accuracy improvements over the best-performing baseline are usually over 5%.
TreeCSS: An Efficient Framework for Vertical Federated Learning
Aug 03, 2024Vertical federated learning (VFL) considers the case that the features of data samples are partitioned over different participants. VFL consists of two main steps, i.e., identify the common data samples for all participants (alignment) and train model using the aligned data samples (training). However, when there are many participants and data samples, both alignment and training become slow. As such, we propose TreeCSS as an efficient VFL framework that accelerates the two main steps. In particular, for sample alignment, we design an efficient multi-party private set intersection (MPSI) protocol called Tree-MPSI, which adopts a tree-based structure and a data-volume-aware scheduling strategy to parallelize alignment among the participants. As model training time scales with the number of data samples, we conduct coreset selection (CSS) to choose some representative data samples for training. Our CCS method adopts a clustering-based scheme for security and generality, which first clusters the features locally on each participant and then merges the local clustering results to select representative samples. In addition, we weight the samples according to their distances to the centroids to reflect their importance to model training. We evaluate the effectiveness and efficiency of our TreeCSS framework on various datasets and models. The results show that compared with vanilla VFL, TreeCSS accelerates training by up to 2.93x and achieves comparable model accuracy.
Open-CD: A Comprehensive Toolbox for Change Detection
Jul 22, 2024



We present Open-CD, a change detection toolbox that contains a rich set of change detection methods as well as related components and modules. The toolbox started from a series of open source general vision task tools, including OpenMMLab Toolkits, PyTorch Image Models, etc. It gradually evolves into a unified platform that covers many popular change detection methods and contemporary modules. It not only includes training and inference codes, but also provides some useful scripts for data analysis. We believe this toolbox is by far the most complete change detection toolbox. In this report, we introduce the various features, supported methods and applications of Open-CD. In addition, we also conduct a benchmarking study on different methods and components. We wish that the toolbox and benchmark could serve the growing research community by providing a flexible toolkit to reimplement existing methods and develop their own new change detectors. Code and models are available at \url{https://github.com/likyoo/open-cd}. Pioneeringly, this report also includes brief descriptions of the algorithms supported in Open-CD, mainly contributed by their authors. We sincerely encourage researchers in this field to participate in this project and work together to create a more open community. This toolkit and report will be kept updated.
Analysis of Distributed Optimization Algorithms on a Real Processing-In-Memory System
Apr 10, 2024



Machine Learning (ML) training on large-scale datasets is a very expensive and time-consuming workload. Processor-centric architectures (e.g., CPU, GPU) commonly used for modern ML training workloads are limited by the data movement bottleneck, i.e., due to repeatedly accessing the training dataset. As a result, processor-centric systems suffer from performance degradation and high energy consumption. Processing-In-Memory (PIM) is a promising solution to alleviate the data movement bottleneck by placing the computation mechanisms inside or near memory. Our goal is to understand the capabilities and characteristics of popular distributed optimization algorithms on real-world PIM architectures to accelerate data-intensive ML training workloads. To this end, we 1) implement several representative centralized distributed optimization algorithms on UPMEM's real-world general-purpose PIM system, 2) rigorously evaluate these algorithms for ML training on large-scale datasets in terms of performance, accuracy, and scalability, 3) compare to conventional CPU and GPU baselines, and 4) discuss implications for future PIM hardware and the need to shift to an algorithm-hardware codesign perspective to accommodate decentralized distributed optimization algorithms. Our results demonstrate three major findings: 1) Modern general-purpose PIM architectures can be a viable alternative to state-of-the-art CPUs and GPUs for many memory-bound ML training workloads, when operations and datatypes are natively supported by PIM hardware, 2) the importance of carefully choosing the optimization algorithm that best fit PIM, and 3) contrary to popular belief, contemporary PIM architectures do not scale approximately linearly with the number of nodes for many data-intensive ML training workloads. To facilitate future research, we aim to open-source our complete codebase.