 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan a Small Model Learn to Look Before It Leaps? Dynamic Learning and Proactive Correction for Hallucination Detection
Nov 08, 2025Hallucination in large language models (LLMs) remains a critical barrier to their safe deployment. Existing tool-augmented hallucination detection methods require pre-defined fixed verification strategies, which are crucial to the quality and effectiveness of tool calls. Some methods directly employ powerful closed-source LLMs such as GPT-4 as detectors, which are effective but too costly. To mitigate the cost issue, some methods adopt the teacher-student architecture and finetune open-source small models as detectors via agent tuning. However, these methods are limited by fixed strategies. When faced with a dynamically changing execution environment, they may lack adaptability and inappropriately call tools, ultimately leading to detection failure. To address the problem of insufficient strategy adaptability, we propose the innovative ``Learning to Evaluate and Adaptively Plan''(LEAP) framework, which endows an efficient student model with the dynamic learning and proactive correction capabilities of the teacher model. Specifically, our method formulates the hallucination detection problem as a dynamic strategy learning problem. We first employ a teacher model to generate trajectories within the dynamic learning loop and dynamically adjust the strategy based on execution failures. We then distill this dynamic planning capability into an efficient student model via agent tuning. Finally, during strategy execution, the student model adopts a proactive correction mechanism, enabling it to propose, review, and optimize its own verification strategies before execution. We demonstrate through experiments on three challenging benchmarks that our LEAP-tuned model outperforms existing state-of-the-art methods.
CAVGAN: Unifying Jailbreak and Defense of LLMs via Generative Adversarial Attacks on their Internal Representations
Jul 08, 2025Security alignment enables the Large Language Model (LLM) to gain the protection against malicious queries, but various jailbreak attack methods reveal the vulnerability of this security mechanism. Previous studies have isolated LLM jailbreak attacks and defenses. We analyze the security protection mechanism of the LLM, and propose a framework that combines attack and defense. Our method is based on the linearly separable property of LLM intermediate layer embedding, as well as the essence of jailbreak attack, which aims to embed harmful problems and transfer them to the safe area. We utilize generative adversarial network (GAN) to learn the security judgment boundary inside the LLM to achieve efficient jailbreak attack and defense. The experimental results indicate that our method achieves an average jailbreak success rate of 88.85\% across three popular LLMs, while the defense success rate on the state-of-the-art jailbreak dataset reaches an average of 84.17\%. This not only validates the effectiveness of our approach but also sheds light on the internal security mechanisms of LLMs, offering new insights for enhancing model security The code and data are available at https://github.com/NLPGM/CAVGAN.
Reasoning based on symbolic and parametric knowledge bases: a survey
Jan 02, 2025Reasoning is fundamental to human intelligence, and critical for problem-solving, decision-making, and critical thinking. Reasoning refers to drawing new conclusions based on existing knowledge, which can support various applications like clinical diagnosis, basic education, and financial analysis. Though a good number of surveys have been proposed for reviewing reasoning-related methods, none of them has systematically investigated these methods from the viewpoint of their dependent knowledge base. Both the scenarios to which the knowledge bases are applied and their storage formats are significantly different. Hence, investigating reasoning methods from the knowledge base perspective helps us better understand the challenges and future directions. To fill this gap, this paper first classifies the knowledge base into symbolic and parametric ones. The former explicitly stores information in human-readable symbols, and the latter implicitly encodes knowledge within parameters. Then, we provide a comprehensive overview of reasoning methods using symbolic knowledge bases, parametric knowledge bases, and both of them. Finally, we identify the future direction toward enhancing reasoning capabilities to bridge the gap between human and machine intelligence.
Origin-Destination Demand Prediction: An Urban Radiation and Attraction Perspective
Nov 29, 2024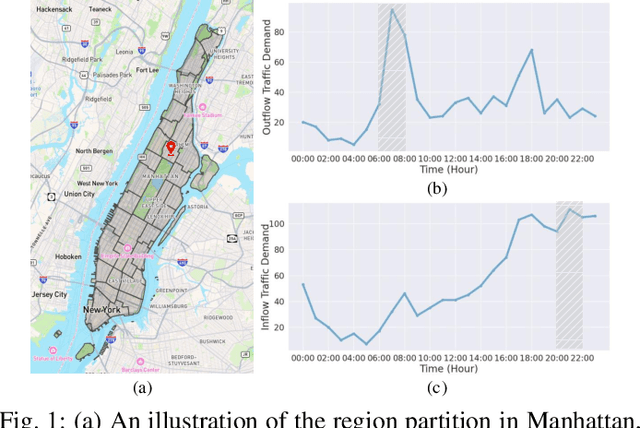
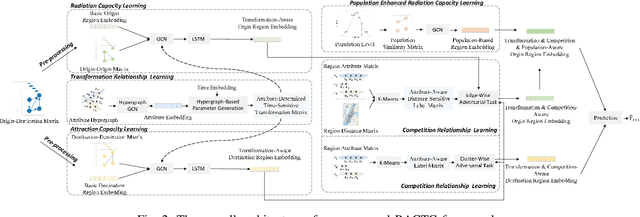
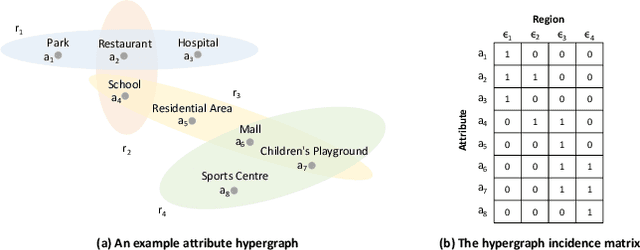
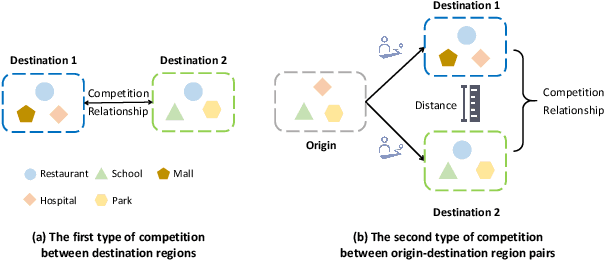
In recent years, origin-destination (OD) demand prediction has gained significant attention for its profound implications in urban development. Existing data-driven deep learning methods primarily focus on the spatial or temporal dependency between regions yet neglecting regions' fundamental functional difference. Though knowledge-driven physical methods have characterised regions' functions by their radiation and attraction capacities, these functions are defined on numerical factors like population without considering regions' intrinsic nominal attributes, e.g., a region is a residential or industrial district. Moreover, the complicated relationships between two types of capacities, e.g., the radiation capacity of a residential district in the morning will be transformed into the attraction capacity in the evening, are totally missing from physical methods. In this paper, we not only generalize the physical radiation and attraction capacities into the deep learning framework with the extended capability to fulfil regions' functions, but also present a new model that captures the relationships between two types of capacities. Specifically, we first model regions' radiation and attraction capacities using a bilateral branch network, each equipped with regions' attribute representations. We then describe the transformation relationship of different capacities of the same region using a hypergraph-based parameter generation method. We finally unveil the competition relationship of different regions with the same attraction capacity through cluster-based adversarial learning. Extensive experiments on two datasets demonstrate the consistent improvements of our method over the state-of-the-art baselines, as well as the good explainability of regions' functions using their nominal attributes.