 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-Autoregressive Neural Codec Language Models for Efficient Zero-Shot Text-to-Speech Synthesis
Apr 14, 2025



Recent zero-shot text-to-speech (TTS) systems face a common dilemma: autoregressive (AR) models suffer from slow generation and lack duration controllability, while non-autoregressive (NAR) models lack temporal modeling and typically require complex designs. In this paper, we introduce a novel pseudo-autoregressive (PAR) codec language modeling approach that unifies AR and NAR modeling. Combining explicit temporal modeling from AR with parallel generation from NAR, PAR generates dynamic-length spans at fixed time steps. Building on PAR, we propose PALLE, a two-stage TTS system that leverages PAR for initial generation followed by NAR refinement. In the first stage, PAR progressively generates speech tokens along the time dimension, with each step predicting all positions in parallel but only retaining the left-most span. In the second stage, low-confidence tokens are iteratively refined in parallel, leveraging the global contextual information. Experiments demonstrate that PALLE, trained on LibriTTS, outperforms state-of-the-art systems trained on large-scale data, including F5-TTS, E2-TTS, and MaskGCT, on the LibriSpeech test-clean set in terms of speech quality, speaker similarity, and intelligibility, while achieving up to ten times faster inference speed. Audio samples are available at https://anonymous-palle.github.io.
MoonCast: High-Quality Zero-Shot Podcast Generation
Mar 19, 2025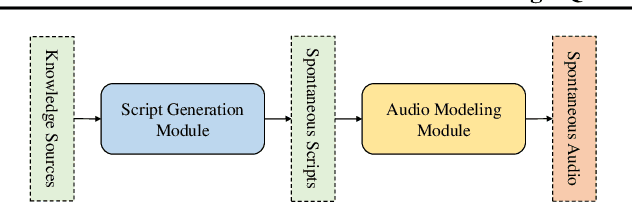



Recent advances in text-to-speech synthesis have achieved notable success in generating high-quality short utterances for individual speakers. However, these systems still face challenges when extending their capabilities to long, multi-speaker, and spontaneous dialogues, typical of real-world scenarios such as podcasts. These limitations arise from two primary challenges: 1) long speech: podcasts typically span several minutes, exceeding the upper limit of most existing work; 2) spontaneity: podcasts are marked by their spontaneous, oral nature, which sharply contrasts with formal, written contexts; existing works often fall short in capturing this spontaneity. In this paper, we propose MoonCast, a solution for high-quality zero-shot podcast generation, aiming to synthesize natural podcast-style speech from text-only sources (e.g., stories, technical reports, news in TXT, PDF, or Web URL formats) using the voices of unseen speakers. To generate long audio, we adopt a long-context language model-based audio modeling approach utilizing large-scale long-context speech data. To enhance spontaneity, we utilize a podcast generation module to generate scripts with spontaneous details, which have been empirically shown to be as crucial as the text-to-speech modeling itself. Experiments demonstrate that MoonCast outperforms baselines, with particularly notable improvements in spontaneity and coherence.
YuE: Scaling Open Foundation Models for Long-Form Music Generation
Mar 11, 2025We tackle the task of long-form music generation--particularly the challenging \textbf{lyrics-to-song} problem--by introducing YuE, a family of open foundation models based on the LLaMA2 architecture. Specifically, YuE scales to trillions of tokens and generates up to five minutes of music while maintaining lyrical alignment, coherent musical structure, and engaging vocal melodies with appropriate accompaniment. It achieves this through (1) track-decoupled next-token prediction to overcome dense mixture signals, (2) structural progressive conditioning for long-context lyrical alignment, and (3) a multitask, multiphase pre-training recipe to converge and generalize. In addition, we redesign the in-context learning technique for music generation, enabling versatile style transfer (e.g., converting Japanese city pop into an English rap while preserving the original accompaniment) and bidirectional generation. Through extensive evaluation, we demonstrate that YuE matches or even surpasses some of the proprietary systems in musicality and vocal agility. In addition, fine-tuning YuE enables additional controls and enhanced support for tail languages. Furthermore, beyond generation, we show that YuE's learned representations can perform well on music understanding tasks, where the results of YuE match or exceed state-of-the-art methods on the MARBLE benchmark. Keywords: lyrics2song, song generation, long-form, foundation model, music generation
MuQ: Self-Supervised Music Representation Learning with Mel Residual Vector Quantization
Jan 03, 2025



Recent years have witnessed the success of foundation models pre-trained with self-supervised learning (SSL) in various music informatics understanding tasks, including music tagging, instrument classification, key detection, and more. In this paper, we propose a self-supervised music representation learning model for music understanding. Distinguished from previous studies adopting random projection or existing neural codec, the proposed model, named MuQ, is trained to predict tokens generated by Mel Residual Vector Quantization (Mel-RVQ). Our Mel-RVQ utilizes residual linear projection structure for Mel spectrum quantization to enhance the stability and efficiency of target extraction and lead to better performance. Experiments in a large variety of downstream tasks demonstrate that MuQ outperforms previous self-supervised music representation models with only 0.9K hours of open-source pre-training data. Scaling up the data to over 160K hours and adopting iterative training consistently improve the model performance. To further validate the strength of our model, we present MuQ-MuLan, a joint music-text embedding model based on contrastive learning, which achieves state-of-the-art performance in the zero-shot music tagging task on the MagnaTagATune dataset. Code and checkpoints are open source in https://github.com/tencent-ailab/MuQ.
SongEditor: Adapting Zero-Shot Song Generation Language Model as a Multi-Task Editor
Dec 18, 2024



The emergence of novel generative modeling paradigms, particularly audio language models, has significantly advanced the field of song generation. Although state-of-the-art models are capable of synthesizing both vocals and accompaniment tracks up to several minutes long concurrently, research about partial adjustments or editing of existing songs is still underexplored, which allows for more flexible and effective production. In this paper, we present SongEditor, the first song editing paradigm that introduces the editing capabilities into language-modeling song generation approaches, facilitating both segment-wise and track-wise modifications. SongEditor offers the flexibility to adjust lyrics, vocals, and accompaniments, as well as synthesizing songs from scratch. The core components of SongEditor include a music tokenizer, an autoregressive language model, and a diffusion generator, enabling generating an entire section, masked lyrics, or even separated vocals and background music. Extensive experiments demonstrate that the proposed SongEditor achieves exceptional performance in end-to-end song editing, as evidenced by both objective and subjective metrics. Audio samples are available in \url{https://cypress-yang.github.io/SongEditor_demo/}.
WeSep: A Scalable and Flexible Toolkit Towards Generalizable Target Speaker Extraction
Sep 24, 2024



Target speaker extraction (TSE) focuses on isolating the speech of a specific target speaker from overlapped multi-talker speech, which is a typical setup in the cocktail party problem. In recent years, TSE draws increasing attention due to its potential for various applications such as user-customized interfaces and hearing aids, or as a crutial front-end processing technologies for subsequential tasks such as speech recognition and speaker recongtion. However, there are currently few open-source toolkits or available pre-trained models for off-the-shelf usage. In this work, we introduce WeSep, a toolkit designed for research and practical applications in TSE. WeSep is featured with flexible target speaker modeling, scalable data management, effective on-the-fly data simulation, structured recipes and deployment support. The toolkit is publicly avaliable at \url{https://github.com/wenet-e2e/WeSep.}
Comparing Discrete and Continuous Space LLMs for Speech Recognition
Sep 01, 2024



This paper investigates discrete and continuous speech representations in Large Language Model (LLM)-based Automatic Speech Recognition (ASR), organizing them by feature continuity and training approach into four categories: supervised and unsupervised for both discrete and continuous types. We further classify LLMs based on their input and autoregressive feedback into continuous and discrete-space models. Using specialized encoders and comparative analysis with a Joint-Training-From-Scratch Language Model (JTFS LM) and pre-trained LLaMA2-7b, we provide a detailed examination of their effectiveness. Our work marks the first extensive comparison of speech representations in LLM-based ASR and explores various modeling techniques. We present an open-sourced achievement of a state-of-the-art Word Error Rate (WER) of 1.69\% on LibriSpeech using a HuBERT encoder, offering valuable insights for advancing ASR and natural language processing (NLP) research.
Gull: A Generative Multifunctional Audio Codec
Apr 07, 2024We introduce Gull, a generative multifunctional audio codec. Gull is a general purpose neural audio compression and decompression model which can be applied to a wide range of tasks and applications such as real-time communication, audio super-resolution, and codec language models. The key components of Gull include (1) universal-sample-rate modeling via subband modeling schemes motivated by recent progress in audio source separation, (2) gain-shape representations motivated by traditional audio codecs, (3) improved residual vector quantization modules for simpler training, (4) elastic decoder network that enables user-defined model size and complexity during inference time, (5) built-in ability for audio super-resolution without the increase of bitrate. We compare Gull with existing traditional and neural audio codecs and show that Gull is able to achieve on par or better performance across various sample rates, bitrates and model complexities in both subjective and objective evaluation metrics.
Continuous Target Speech Extraction: Enhancing Personalized Diarization and Extraction on Complex Recordings
Jan 29, 2024



Target speaker extraction (TSE) aims to extract the target speaker's voice from the input mixture. Previous studies have concentrated on high-overlapping scenarios. However, real-world applications usually meet more complex scenarios like variable speaker overlapping and target speaker absence. In this paper, we introduces a framework to perform continuous TSE (C-TSE), comprising a target speaker voice activation detection (TSVAD) and a TSE model. This framework significantly improves TSE performance on similar speakers and enhances personalization, which is lacking in traditional diarization methods. In detail, unlike conventional TSVAD deployed to refine the diarization results, the proposed Attention-target speaker voice activation detection (A-TSVAD) directly generates timestamps of the target speaker. We also explore some different integration methods of A-TSVAD and TSE by comparing the cascaded and parallel methods. The framework's effectiveness is assessed using a range of metrics, including diarization and enhancement metrics. Our experiments demonstrate that A-TSVAD outperforms conventional methods in reducing diarization errors. Furthermore, the integration of A-TSVAD and TSE in a sequential cascaded manner further enhances extraction accuracy.
Consistent and Relevant: Rethink the Query Embedding in General Sound Separation
Dec 24, 2023



The query-based audio separation usually employs specific queries to extract target sources from a mixture of audio signals. Currently, most query-based separation models need additional networks to obtain query embedding. In this way, separation model is optimized to be adapted to the distribution of query embedding. However, query embedding may exhibit mismatches with separation models due to inconsistent structures and independent information. In this paper, we present CaRE-SEP, a consistent and relevant embedding network for general sound separation to encourage a comprehensive reconsideration of query usage in audio separation. CaRE-SEP alleviates the potential mismatch between queries and separation in two aspects, including sharing network structure and sharing feature information. First, a Swin-Unet model with a shared encoder is conducted to unify query encoding and sound separation into one model, eliminating the network architecture difference and generating consistent distribution of query and separation features. Second, by initializing CaRE-SEP with a pretrained classification network and allowing gradient backpropagation, the query embedding is optimized to be relevant to the separation feature, further alleviating the feature mismatch problem. Experimental results indicate the proposed CaRE-SEP model substantially improves the performance of separation tasks. Moreover, visualizations validate the potential mismatch and how CaRE-SEP solves it.