 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorizable Net: An Efficient Subgraph-based Framework for Scene Graph Generation
Aug 27, 2018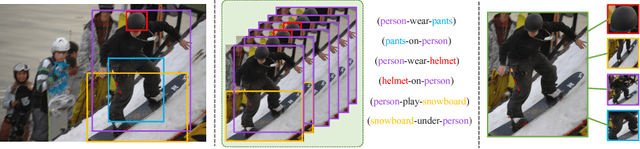
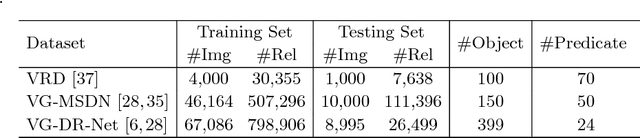
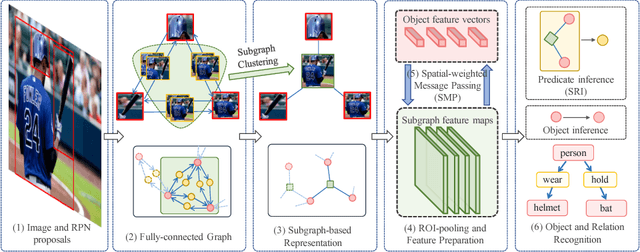
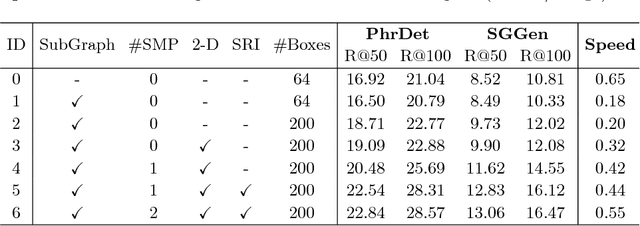
Generating scene graph to describe all the relations inside an image gains increasing interests these years. However, most of the previous methods use complicated structures with slow inference speed or rely on the external data, which limits the usage of the model in real-life scenarios. To improve the efficiency of scene graph generation, we propose a subgraph-based connection graph to concisely represent the scene graph during the inference. A bottom-up clustering method is first used to factorize the entire scene graph into subgraphs, where each subgraph contains several objects and a subset of their relationships. By replacing the numerous relationship representations of the scene graph with fewer subgraph and object features, the computation in the intermediate stage is significantly reduced. In addition, spatial information is maintained by the subgraph features, which is leveraged by our proposed Spatial-weighted Message Passing~(SMP) structure and Spatial-sensitive Relation Inference~(SRI) module to facilitate the relationship recognition. On the recent Visual Relationship Detection and Visual Genome datasets, our method outperforms the state-of-the-art method in both accuracy and speed.
ICNet for Real-Time Semantic Segmentation on High-Resolution Images
Aug 20, 2018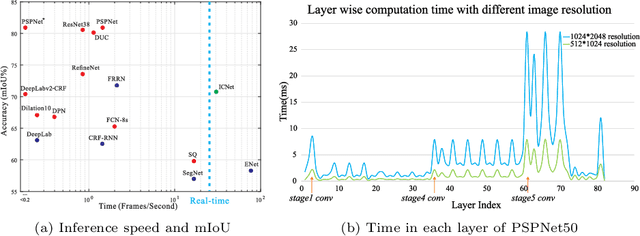

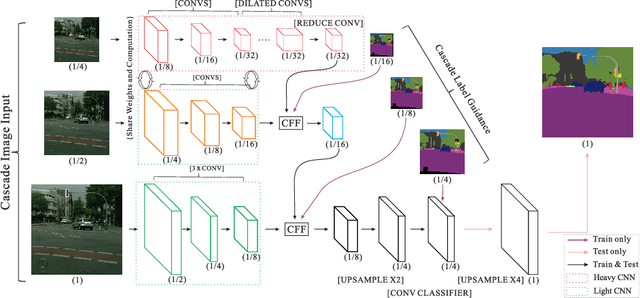
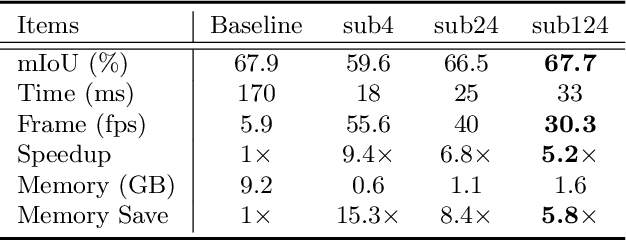
We focus on the challenging task of real-time semantic segmentation in this paper. It finds many practical applications and yet is with fundamental difficulty of reducing a large portion of computation for pixel-wise label inference. We propose an image cascade network (ICNet) that incorporates multi-resolution branches under proper label guidance to address this challenge. We provide in-depth analysis of our framework and introduce the cascade feature fusion unit to quickly achieve high-quality segmentation. Our system yields real-time inference on a single GPU card with decent quality results evaluated on challenging datasets like Cityscapes, CamVid and COCO-Stuff.
Generative Adversarial Frontal View to Bird View Synthesis
Aug 01, 2018
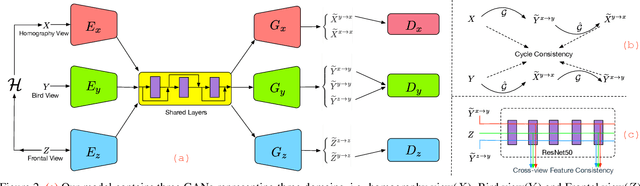
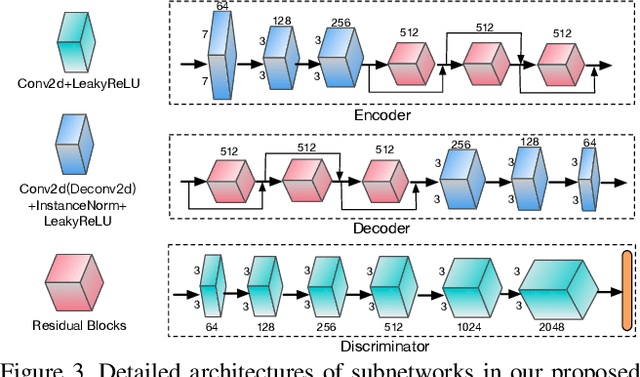
Environment perception is an important task with great practical value and bird view is an essential part for creating panoramas of surrounding environment. Due to the large gap and severe deformation between the frontal view and bird view, generating a bird view image from a single frontal view is challenging. To tackle this problem, we propose the BridgeGAN, i.e., a novel generative model for bird view synthesis. First, an intermediate view, i.e., homography view, is introduced to bridge the large gap. Next, conditioned on the three views (frontal view, homography view and bird view) in our task, a multi-GAN based model is proposed to learn the challenging cross-view translation. Extensive experiments conducted on a synthetic dataset have demonstrated that the images generated by our model are much better than those generated by existing methods, with more consistent global appearance and sharper details. Ablation studies and discussions show its reliability and robustness in some challenging cases.
SegStereo: Exploiting Semantic Information for Disparity Estimation
Jul 31, 2018
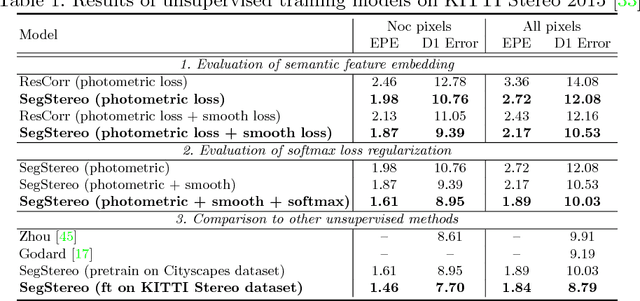
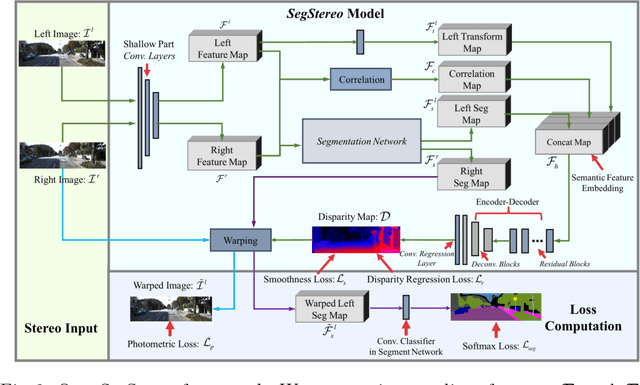
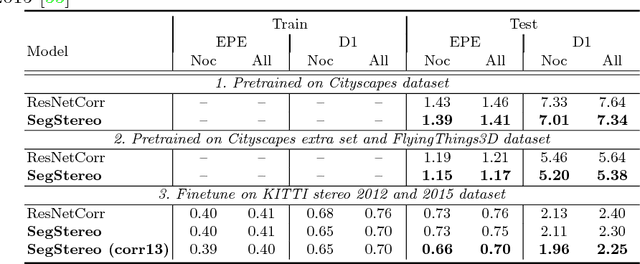
Disparity estimation for binocular stereo images finds a wide range of applications. Traditional algorithms may fail on featureless regions, which could be handled by high-level clues such as semantic segments. In this paper, we suggest that appropriate incorporation of semantic cues can greatly rectify prediction in commonly-used disparity estimation frameworks. Our method conducts semantic feature embedding and regularizes semantic cues as the loss term to improve learning disparity. Our unified model SegStereo employs semantic features from segmentation and introduces semantic softmax loss, which helps improve the prediction accuracy of disparity maps. The semantic cues work well in both unsupervised and supervised manners. SegStereo achieves state-of-the-art results on KITTI Stereo benchmark and produces decent prediction on both CityScapes and FlyingThings3D datasets.
Pose Guided Human Video Generation
Jul 30, 2018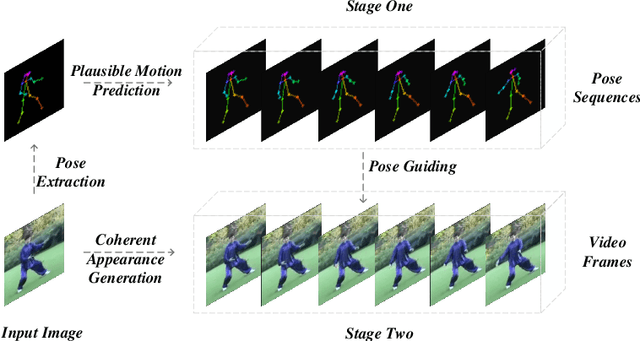
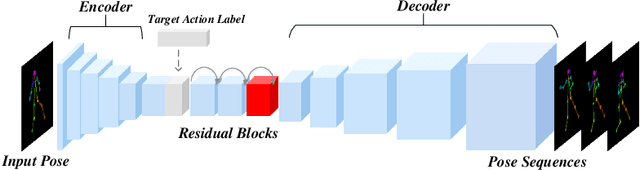


Due to the emergence of Generative Adversarial Networks, video synthesis has witnessed exceptional breakthroughs. However, existing methods lack a proper representation to explicitly control the dynamics in videos. Human pose, on the other hand, can represent motion patterns intrinsically and interpretably, and impose the geometric constraints regardless of appearance. In this paper, we propose a pose guided method to synthesize human videos in a disentangled way: plausible motion prediction and coherent appearance generation. In the first stage, a Pose Sequence Generative Adversarial Network (PSGAN) learns in an adversarial manner to yield pose sequences conditioned on the class label. In the second stage, a Semantic Consistent Generative Adversarial Network (SCGAN) generates video frames from the poses while preserving coherent appearances in the input image. By enforcing semantic consistency between the generated and ground-truth poses at a high feature level, our SCGAN is robust to noisy or abnormal poses. Extensive experiments on both human action and human face datasets manifest the superiority of the proposed method over other state-of-the-arts.
Two at Once: Enhancing Learning and Generalization Capacities via IBN-Net
Jul 27, 2018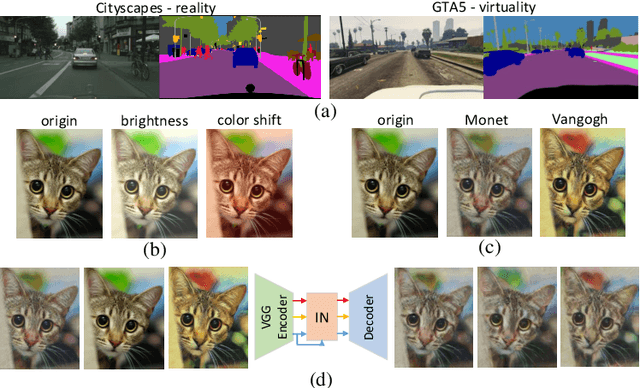
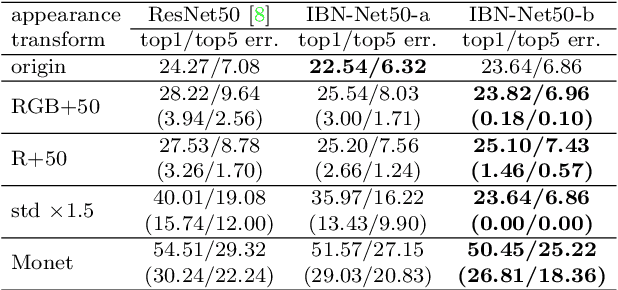
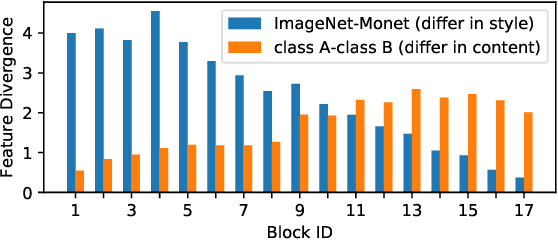

Convolutional neural networks (CNNs) have achieved great successes in many computer vision problems. Unlike existing works that designed CNN architectures to improve performance on a single task of a single domain and not generalizable, we present IBN-Net, a novel convolutional architecture, which remarkably enhances a CNN's modeling ability on one domain (e.g. Cityscapes) as well as its generalization capacity on another domain (e.g. GTA5) without finetuning. IBN-Net carefully integrates Instance Normalization (IN) and Batch Normalization (BN) as building blocks, and can be wrapped into many advanced deep networks to improve their performances. This work has three key contributions. (1) By delving into IN and BN, we disclose that IN learns features that are invariant to appearance changes, such as colors, styles, and virtuality/reality, while BN is essential for preserving content related information. (2) IBN-Net can be applied to many advanced deep architectures, such as DenseNet, ResNet, ResNeXt, and SENet, and consistently improve their performance without increasing computational cost. (3) When applying the trained networks to new domains, e.g. from GTA5 to Cityscapes, IBN-Net achieves comparable improvements as domain adaptation methods, even without using data from the target domain. With IBN-Net, we won the 1st place on the WAD 2018 Challenge Drivable Area track, with an mIoU of 86.18%.
Mask-aware Photorealistic Face Attribute Manipulation
Apr 24, 2018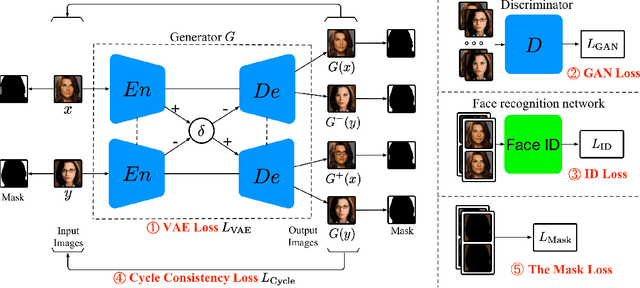
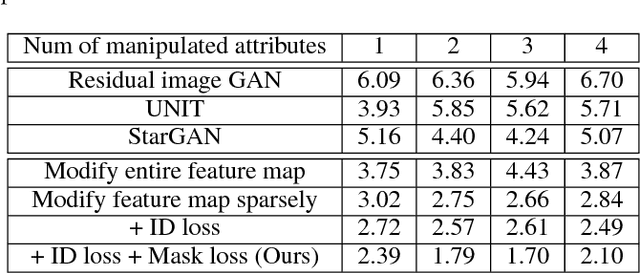


The task of face attribute manipulation has found increasing applications, but still remains challeng- ing with the requirement of editing the attributes of a face image while preserving its unique details. In this paper, we choose to combine the Variational AutoEncoder (VAE) and Generative Adversarial Network (GAN) for photorealistic image genera- tion. We propose an effective method to modify a modest amount of pixels in the feature maps of an encoder, changing the attribute strength contin- uously without hindering global information. Our training objectives of VAE and GAN are reinforced by the supervision of face recognition loss and cy- cle consistency loss for faithful preservation of face details. Moreover, we generate facial masks to en- force background consistency, which allows our training to focus on manipulating the foreground face rather than background. Experimental results demonstrate our method, called Mask-Adversarial AutoEncoder (M-AAE), can generate high-quality images with changing attributes and outperforms prior methods in detail preservation.
Low-Latency Video Semantic Segmentation
Apr 02, 2018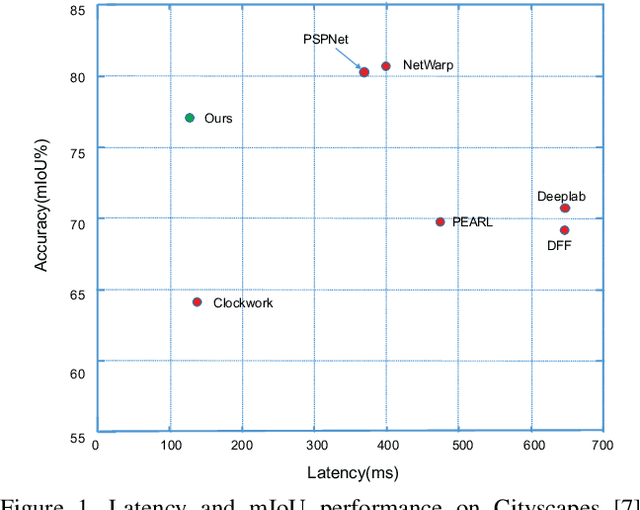
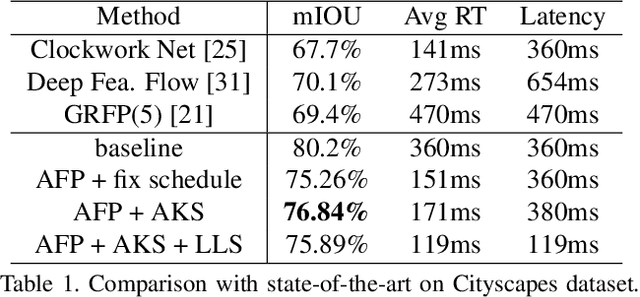
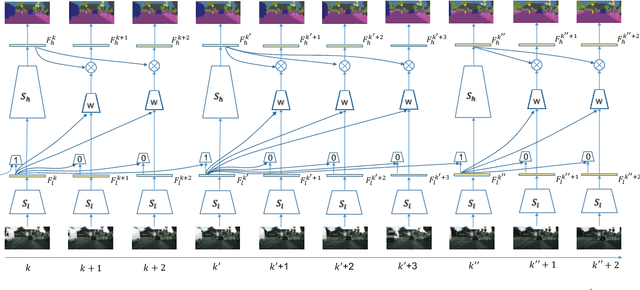

Recent years have seen remarkable progress in semantic segmentation. Yet, it remains a challenging task to apply segmentation techniques to video-based applications. Specifically, the high throughput of video streams, the sheer cost of running fully convolutional networks, together with the low-latency requirements in many real-world applications, e.g. autonomous driving, present a significant challenge to the design of the video segmentation framework. To tackle this combined challenge, we develop a framework for video semantic segmentation, which incorporates two novel components: (1) a feature propagation module that adaptively fuses features over time via spatially variant convolution, thus reducing the cost of per-frame computation; and (2) an adaptive scheduler that dynamically allocate computation based on accuracy prediction. Both components work together to ensure low latency while maintaining high segmentation quality. On both Cityscapes and CamVid, the proposed framework obtained competitive performance compared to the state of the art, while substantially reducing the latency, from 360 ms to 119 ms.
Context Encoding for Semantic Segmentation
Mar 23, 2018
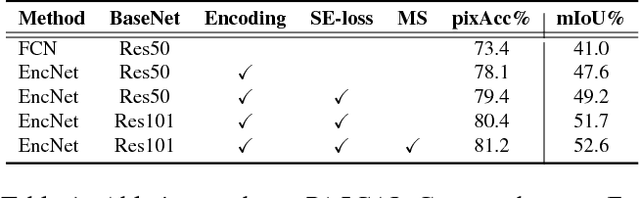
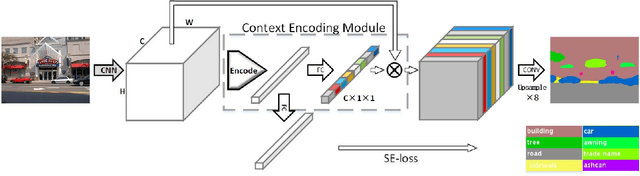
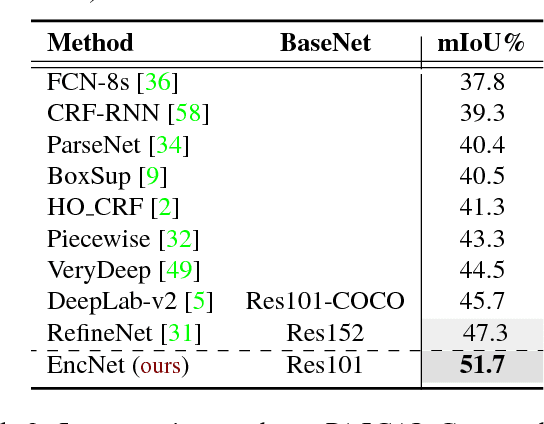
Recent work has made significant progress in improving spatial resolution for pixelwise labeling with Fully Convolutional Network (FCN) framework by employing Dilated/Atrous convolution, utilizing multi-scale features and refining boundaries. In this paper, we explore the impact of global contextual information in semantic segmentation by introducing the Context Encoding Module, which captures the semantic context of scenes and selectively highlights class-dependent featuremaps. The proposed Context Encoding Module significantly improves semantic segmentation results with only marginal extra computation cost over FCN. Our approach has achieved new state-of-the-art results 51.7% mIoU on PASCAL-Context, 85.9% mIoU on PASCAL VOC 2012. Our single model achieves a final score of 0.5567 on ADE20K test set, which surpass the winning entry of COCO-Place Challenge in 2017. In addition, we also explore how the Context Encoding Module can improve the feature representation of relatively shallow networks for the image classification on CIFAR-10 dataset. Our 14 layer network has achieved an error rate of 3.45%, which is comparable with state-of-the-art approaches with over 10 times more layers. The source code for the complete system are publicly available.
GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose
Mar 12, 2018
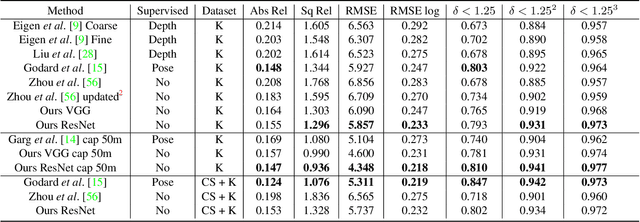
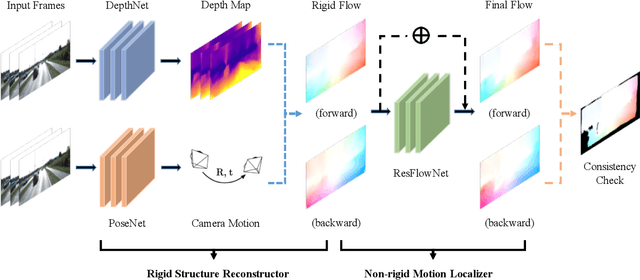
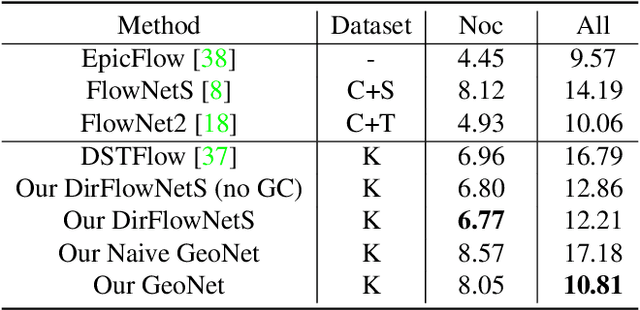
We propose GeoNet, a jointly unsupervised learning framework for monocular depth, optical flow and ego-motion estimation from videos. The three components are coupled by the nature of 3D scene geometry, jointly learned by our framework in an end-to-end manner. Specifically, geometric relationships are extracted over the predictions of individual modules and then combined as an image reconstruction loss, reasoning about static and dynamic scene parts separately. Furthermore, we propose an adaptive geometric consistency loss to increase robustness towards outliers and non-Lambertian regions, which resolves occlusions and texture ambiguities effectively. Experimentation on the KITTI driving dataset reveals that our scheme achieves state-of-the-art results in all of the three tasks, performing better than previously unsupervised methods and comparably with supervised ones.