 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconDrive: Fast Feed-Forward 4D Gaussian Splatting for Autonomous Driving Scene Reconstruction
Mar 08, 2026High-fidelity visual reconstruction and novel-view synthesis are essential for realistic closed-loop evaluation in autonomous driving. While 4D Gaussian Splatting (4DGS) offers a promising balance of accuracy and efficiency, existing per-scene optimization methods require costly iterative refinement, rendering them unscalable for extensive urban environments. Conversely, current feed-forward approaches often suffer from degraded photometric quality. To address these limitations, we propose ReconDrive, a feed-forward framework that leverages and extends the 3D foundation model VGGT for rapid, high-fidelity 4DGS generation. Our architecture introduces two core adaptations to tailor the foundation model to dynamic driving scenes: (1) Hybrid Gaussian Prediction Heads, which decouple the regression of spatial coordinates and appearance attributes to overcome the photometric deficiencies inherent in generalized foundation features; and (2) a Static-Dynamic 4D Composition strategy that explicitly captures temporal motion via velocity modeling to represent complex dynamic environments. Benchmarked on nuScenes, ReconDrive significantly outperforms existing feed-forward baselines in reconstruction, novel-view synthesis, and 3D perception. It achieves performance competitive with per-scene optimization while being orders of magnitude faster, providing a scalable and practical solution for realistic driving simulation.
Path Aggregation Network for Instance Segmentation
Sep 18, 2018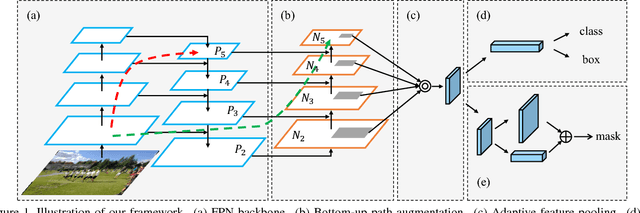

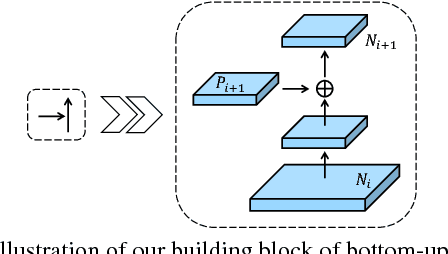
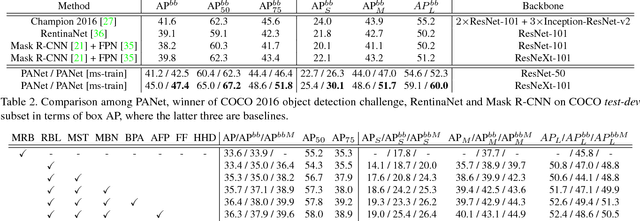
The way that information propagates in neural networks is of great importance. In this paper, we propose Path Aggregation Network (PANet) aiming at boosting information flow in proposal-based instance segmentation framework. Specifically, we enhance the entire feature hierarchy with accurate localization signals in lower layers by bottom-up path augmentation, which shortens the information path between lower layers and topmost feature. We present adaptive feature pooling, which links feature grid and all feature levels to make useful information in each feature level propagate directly to following proposal subnetworks. A complementary branch capturing different views for each proposal is created to further improve mask prediction. These improvements are simple to implement, with subtle extra computational overhead. Our PANet reaches the 1st place in the COCO 2017 Challenge Instance Segmentation task and the 2nd place in Object Detection task without large-batch training. It is also state-of-the-art on MVD and Cityscapes. Code is available at https://github.com/ShuLiu1993/PANet